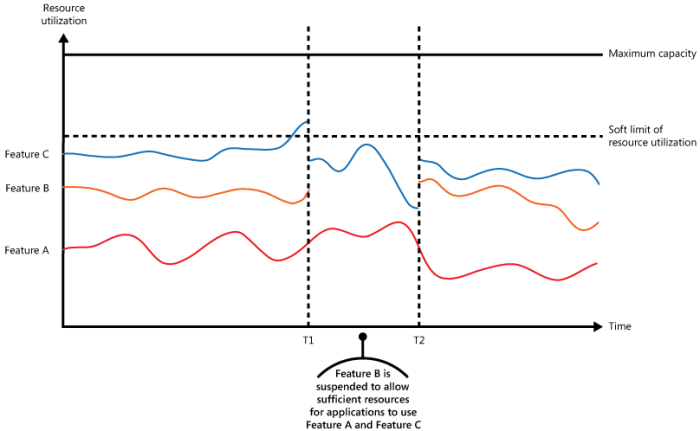
Understanding CAP theorem in distributed databases is crucial for designing and implementing robust, scalable systems. This intricate concept explores the fundamental trade-offs inherent in managing data across multiple interconnected nodes. The theorem’s core tenets – Consistency, Availability, and Partition Tolerance – dictate how data integrity, system responsiveness, and fault resilience are balanced in distributed environments. This guide delves into the intricacies of each component, examining their implications and trade-offs across various database architectures.
From understanding various consistency models, including strong and eventual consistency, to analyzing the significance of availability in modern applications, this exploration provides a comprehensive overview of the CAP theorem’s practical application. We’ll investigate how different database types (relational and NoSQL) approach these trade-offs and examine real-world examples of systems that have successfully navigated the CAP theorem’s challenges. Furthermore, the discussion will cover emerging trends in distributed databases and their implications for future system design.
Introduction to CAP Theorem

The CAP theorem, a cornerstone of distributed systems design, posits a fundamental trade-off in designing reliable and available distributed databases. It highlights the inherent limitations in achieving all three desirable properties simultaneously: consistency, availability, and partition tolerance. Understanding these trade-offs is crucial for architects and developers choosing the right database architecture for their specific needs.The CAP theorem, articulated by Eric Brewer, demonstrates that in a distributed system, it is impossible to simultaneously guarantee all three properties: consistency, availability, and partition tolerance.
This means that developers must make conscious choices about which properties to prioritize, understanding the potential implications of these choices.
Core Concepts of CAP Theorem
The CAP theorem revolves around three crucial properties of distributed databases: consistency, availability, and partition tolerance.
- Consistency: Ensures that all nodes in the system see the same data at any given time. This means that if one node updates a value, all other nodes should reflect that update immediately. A good example of a highly consistent system is a single-node database, where all operations are performed on a single, unchanging copy of the data.
- Availability: Guarantees that the system will always respond to requests within a reasonable timeframe. This means that even if some parts of the system are experiencing issues, users should still be able to access the data they need.
- Partition Tolerance: Indicates the system’s ability to function correctly even if some nodes or communication channels are unavailable or disconnected. This is critical in distributed systems, where failures and network issues are inevitable. It allows for a system to remain operational despite failures.
Trade-offs in Choosing Properties
The CAP theorem highlights the inescapable trade-offs in designing distributed databases. The choice between consistency, availability, and partition tolerance depends heavily on the application’s specific needs. For example, a social media platform might prioritize availability to ensure users can always post and interact, even if some nodes are temporarily offline. In contrast, an e-commerce system might prioritize consistency to guarantee that orders are accurately reflected in inventory counts.
Database Architectures and CAP Theorem Considerations
The table below illustrates how different database architectures handle the CAP theorem trade-offs. Note that these are generalizations, and specific implementations can vary.
| Database Architecture | Consistency | Availability | Partition Tolerance | Typical Use Cases |
|---|---|---|---|---|
| Relational Databases (e.g., MySQL, PostgreSQL) | Strong | High | No | Transactions requiring strong consistency, like financial systems. |
| NoSQL Databases (e.g., Cassandra, MongoDB) | Eventual | High | Yes | Applications requiring high availability and scalability, such as social media platforms. |
| Distributed Key-Value Stores (e.g., Redis) | Strong (in some cases) | High | Yes | Applications requiring high performance and low latency, such as caching. |
| Cloud-based databases (e.g., Amazon DynamoDB) | Eventual or Strong (configurable) | High | Yes | Web applications, high-volume data processing, and applications requiring high scalability and fault tolerance. |
Understanding Consistency in Distributed Databases
Consistency in distributed databases is a crucial aspect of ensuring data integrity and reliability across multiple nodes. Different consistency models address the trade-off between data consistency and system performance, influencing the design and operation of distributed applications. This section explores various consistency models, their implications, and the challenges involved in achieving consistency in distributed systems.
Consistency Models
Various consistency models exist, each defining a different level of agreement on data updates across distributed nodes. Strong consistency guarantees that all nodes see the same data at the same time, while eventual consistency allows for some lag in data updates across nodes.
Strong Consistency
Strong consistency ensures that all clients see the most recent update immediately. This model is crucial in applications requiring immediate and consistent data access, such as financial transactions or online banking. All replicas of the data are updated in a synchronized fashion, guaranteeing that all clients perceive the same state of the data. A critical implication of strong consistency is the significant overhead involved in maintaining consistency across all nodes, potentially impacting performance.
Eventual Consistency
Eventual consistency, in contrast, allows for a delay in updating all replicas. Data eventually converges to a consistent state across all nodes, but there might be a brief period where different clients see different versions of the data. This model is often preferred for applications that can tolerate a slight delay in data updates, such as social media platforms or online gaming.
The trade-off is that data consistency might not be immediately reflected across all nodes, which could lead to inconsistent views of the data for a short time.
Implications of Consistency Models
Strong consistency typically results in high data integrity, ensuring data accuracy and reliability. However, it can introduce significant latency and impact performance due to the need for immediate synchronization across all nodes. Eventual consistency, on the other hand, often prioritizes high performance by allowing for asynchronous updates, which can lead to faster response times. However, this flexibility comes at the cost of potential data inconsistencies for a short period.
Challenges of Achieving Consistency in Distributed Systems
Achieving consistency in distributed systems is challenging due to factors such as network partitions, node failures, and asynchronous communication. These factors can disrupt the synchronization of data across nodes, leading to inconsistencies. Implementing effective consistency algorithms and mechanisms to manage these challenges is crucial for building reliable distributed applications.
Comparison of Consistency Algorithms
Various consistency algorithms exist, each with its own strengths and weaknesses. Some popular algorithms include two-phase commit, Paxos, and Raft. Two-phase commit ensures strong consistency by coordinating updates across all nodes, while Paxos and Raft provide more efficient and robust approaches to achieving consensus in distributed systems. The choice of algorithm depends on the specific needs and requirements of the application.
Scenarios for Consistency Models
| Scenario | Strong Consistency | Eventual Consistency |
|---|---|---|
| Financial transactions | Required | Not suitable |
| Online banking | Required | Not suitable |
| Social media platforms | Unnecessary | Acceptable |
| Online gaming | Acceptable | Acceptable |
| E-commerce platforms | Acceptable | Acceptable |
Analyzing Availability in Distributed Systems
Availability, a crucial aspect of distributed databases, ensures that the system is operational and accessible to users at any given time. Modern applications, particularly those requiring real-time data access, demand high levels of availability to maintain user experience and prevent significant disruptions. This critical characteristic is particularly important in e-commerce, online gaming, and financial transactions, where downtime can lead to substantial financial losses and reputational damage.High availability in distributed databases is paramount for maintaining a seamless user experience.
Achieving this involves implementing strategies that minimize downtime and maximize operational efficiency. The inherent complexity of distributed systems necessitates careful consideration of trade-offs between availability, consistency, and partition tolerance. Understanding these trade-offs is crucial for architecting robust and reliable distributed database systems.
Importance of Availability in Modern Applications
Modern applications heavily rely on continuous access to data. Downtime can lead to significant revenue loss, reputational damage, and user dissatisfaction. The ability to maintain continuous service is crucial for applications such as online banking, e-commerce platforms, and social media networks. These applications require constant accessibility to function effectively, and downtime can have severe repercussions. In the case of online retail, a momentary outage can result in lost sales and a diminished customer base.
This demonstrates the critical role availability plays in the success of modern applications.
Strategies for Maximizing Availability in Distributed Databases
Several strategies can enhance availability in distributed databases. Replication is a key technique, where data is duplicated across multiple servers. This redundancy allows the system to continue functioning even if one server fails. Other strategies include load balancing, which distributes traffic across multiple servers to prevent overload on any single server, and failover mechanisms, which automatically switch to a backup server if a primary server fails.
Trade-offs Between Availability and Consistency
Availability and consistency are often conflicting goals in distributed systems. Ensuring high availability might require relaxing consistency constraints, such as allowing for eventual consistency. In certain scenarios, the need for immediate, absolute consistency may be less critical than the need for continuous operation. This trade-off must be carefully considered based on the specific requirements of the application.
For instance, a social media platform might prioritize availability over strict data consistency in cases of temporary network issues.
Examples of High-Availability Architectures in Distributed Databases
Many high-availability architectures utilize a combination of replication, load balancing, and failover mechanisms. A common example is a database cluster where multiple replicas of data are maintained across various servers. In case of failure, a failover mechanism seamlessly switches traffic to a functioning replica. This architecture ensures high availability while maintaining data redundancy. Another example is using a combination of master-slave or multi-master replication strategies, combined with load balancing to distribute traffic and handle failures effectively.
Strategies for Achieving High Availability
| Strategy | Pros | Cons |
|---|---|---|
| Replication (Master-Slave) | Improved availability due to redundancy, potentially reduced read latency. | Potential write latency, complex synchronization, and data consistency challenges. |
| Replication (Multi-Master) | Increased write throughput, potentially improved availability. | Requires more complex consistency protocols, higher operational overhead. |
| Load Balancing | Distributes traffic across multiple servers, preventing overload on any single server. | Requires complex configuration and management, potential latency variations. |
| Failover Mechanisms | Automatically switches traffic to a backup server upon failure. | Requires careful planning and testing to ensure seamless failover, potential for transient data inconsistencies. |
| Data Sharding | Improved scalability and availability by partitioning data across multiple servers. | Can introduce complexity in data access and query processing, potential for uneven load distribution. |
Partition Tolerance in Distributed Environments
Network partitions are a critical aspect of distributed database systems, representing a scenario where the network connecting the nodes of the system is divided into multiple, isolated segments. This separation disrupts communication between nodes, potentially leading to inconsistencies and data loss. Understanding how partitions affect data integrity is essential for designing robust and reliable distributed systems.
Network Partitions and Their Impact
Network partitions, often triggered by temporary network outages or failures, can sever connections between geographically dispersed nodes in a distributed system. This isolation prevents data synchronization and consistency enforcement. The consequence is a system unable to maintain a consistent view of data across all nodes.
Impact on Data Consistency and Availability
Partition tolerance directly affects both consistency and availability in distributed systems. When a partition occurs, maintaining strong consistency across all nodes becomes extremely challenging, if not impossible, because the nodes in different partitions have different views of the data. This could lead to data corruption or inconsistencies. Simultaneously, achieving high availability in a partitioned system is also a significant hurdle.
Some nodes might be unreachable or respond with delays, causing the system to appear unavailable or function at a reduced capacity.
Examples of Network Partitions
Real-world examples of network partitions are common. A major internet outage could isolate a portion of a distributed system’s nodes. Natural disasters, like earthquakes or floods, can sever network connections between geographically separated data centers. Furthermore, intentional attacks, such as denial-of-service attacks, can disrupt network communication and create partitions. In these scenarios, the system must gracefully handle the loss of connectivity and ensure that data integrity is maintained.
Designing a Partition-Tolerant System
A robust partition-tolerant system needs to anticipate and handle network disruptions. The design should prioritize data consistency and availability in the face of network partitions. This involves employing techniques to detect partitions, ensuring data integrity during partitions, and rebuilding consistency when partitions are resolved. Furthermore, the system architecture must be fault-tolerant and resilient to failures of individual nodes.
Strategies for Handling Network Partitions
Several strategies exist to handle network partitions and ensure data integrity. One approach is to use eventual consistency. In this case, data consistency is not guaranteed immediately after a partition but rather over time as the network recovers and nodes re-synchronize. Another strategy involves allowing different partitions to operate independently and to later reconcile the differences when the partitions reunite.
This can be done by using techniques such as conflict resolution algorithms. Finally, data replication across multiple geographically diverse locations can also aid in achieving partition tolerance. By distributing data across various locations, the system is less susceptible to network failures that isolate a particular node or region. This ensures the system remains available, even during a partition.
Data Replication Strategies in Partition-Tolerant Systems
Data replication plays a crucial role in creating partition-tolerant systems. Different replication strategies offer various trade-offs in terms of consistency and availability. A key consideration is the choice between strong consistency and eventual consistency. Strong consistency guarantees that all nodes see the same data at the same time, while eventual consistency guarantees that the data will eventually be consistent across all nodes, even if there is a delay.
Choosing the right replication strategy depends on the specific requirements of the application. For instance, a system requiring immediate data consistency would opt for strong consistency, whereas a system with less stringent requirements might favor eventual consistency.
CAP Theorem in Different Database Types

The CAP theorem, a cornerstone of distributed systems design, highlights the inherent trade-offs between consistency, availability, and partition tolerance. Understanding how different database types navigate these trade-offs is crucial for selecting the right database for a given application. This section delves into the application of the CAP theorem across relational and NoSQL databases, analyzing their respective approaches to managing these crucial attributes.
Relational Databases and the CAP Theorem
Relational databases, traditionally designed for strong consistency, often prioritize consistency over availability and partition tolerance. This design choice stems from the need for predictable data integrity and accuracy, critical in transactional applications where data consistency is paramount. However, this prioritization may lead to reduced availability during periods of high load or network partitions.
- Consistency is generally a high priority in relational databases, as it ensures data accuracy and reliability. Transactions are meticulously managed to maintain data integrity across multiple operations.
- Availability, while desirable, is often considered secondary. The focus is on maintaining consistency, which might result in temporary unavailability during complex transactions or failures.
- Partition Tolerance is a consideration, though it may not be the primary focus in the design. Relational databases often include mechanisms to handle partitions, though these mechanisms may not be as sophisticated as those in NoSQL systems.
NoSQL Databases and the CAP Theorem
NoSQL databases, in contrast to relational systems, often prioritize availability and partition tolerance over strong consistency. This architectural choice is motivated by the need for high scalability and performance in large-scale applications. Consequently, consistency in NoSQL databases is often relaxed or implemented in a manner that allows for greater flexibility and performance.
- Consistency can vary significantly depending on the specific NoSQL database type. Some NoSQL databases offer strong consistency, while others embrace eventual consistency, allowing for faster updates and retrieval of data at the cost of potential inconsistencies.
- Availability is typically a high priority for NoSQL databases, especially those designed for high-traffic applications. The emphasis on rapid data access and updates contributes to the system’s overall availability.
- Partition Tolerance is often a core design principle in NoSQL databases. The distributed nature of these systems necessitates robust mechanisms to handle network partitions and data distribution.
Comparing Relational and NoSQL Databases
The contrasting approaches of relational and NoSQL databases to the CAP theorem are evident in their design choices. Relational databases emphasize consistency, while NoSQL systems prioritize availability and partition tolerance. This difference is reflected in the way they handle data integrity and scalability.
| Database Type | Consistency | Availability | Partition Tolerance |
|---|---|---|---|
| Relational | Strong | Medium | Medium |
| NoSQL (e.g., Document, Key-Value) | Eventual (often) | High | High |
Practical Examples of CAP Theorem in Action
The CAP theorem, while theoretical, provides a valuable framework for understanding the trade-offs inherent in designing distributed systems. Real-world systems often demonstrate the challenges and choices associated with prioritizing consistency, availability, and partition tolerance. These systems reveal the intricate balance required to ensure robust and reliable operation in dynamic network environments.By examining how these systems address the CAP theorem, we gain insights into the design decisions and trade-offs involved in building scalable and resilient applications.
These examples highlight the specific scenarios where consistency is sacrificed for availability, or vice versa, showcasing the nuanced nature of distributed database design.
Examples of Real-World Systems
Various real-world systems demonstrate the application of the CAP theorem. These systems, ranging from social media platforms to e-commerce websites, face the challenges of maintaining data integrity and responsiveness across geographically dispersed users and data centers.
- Social Media Platforms: Platforms like Twitter or Facebook prioritize availability and partition tolerance. Data consistency is often relaxed. If a user posts a message, other users might see it slightly delayed, or even not at all, if a network partition temporarily isolates a user. The system prioritizes user experience by keeping the platform up and operational during network issues.
Data consistency is maintained through batch processing and eventual consistency mechanisms. This allows for the fastest possible dissemination of content, despite some potential inconsistencies.
- E-commerce Websites: E-commerce platforms like Amazon or eBay prioritize availability. A user placing an order should not experience a site outage due to a network issue. Consistency might be relaxed by using techniques like eventual consistency for order updates. This approach ensures that users can interact with the system quickly, while order details might be updated across a wider range of systems over time, with eventual consistency.
The system balances the need for immediate order processing with data integrity by making consistency eventual.
- Cloud Storage Services: Services like Google Drive or Dropbox prioritize availability and partition tolerance. The system must ensure that users can access their files regardless of network partitions. Consistency is maintained through eventual consistency, where updates are replicated across multiple servers, with updates eventually propagating to all nodes. This model ensures high availability, even if a portion of the system is temporarily unavailable.
Design Choices and Prioritization
The design choices for these systems reflect the prioritization of CAP attributes. The specific choice often depends on the specific use case and the acceptable level of consistency and availability.
- Data Replication: A critical aspect of achieving availability and partition tolerance. Data replication across multiple servers ensures redundancy and allows for continued operation even during network partitions. The specific replication strategy employed directly impacts the consistency guarantees. Asynchronous replication, for example, allows for faster availability but potentially introduces consistency delays.
- Consistency Models: Systems utilize different consistency models to manage the trade-offs between consistency and availability. Strong consistency, as in traditional relational databases, ensures immediate updates across all nodes. Eventual consistency, often used in distributed databases, ensures updates propagate eventually, prioritizing availability over immediate consistency.
- Partition Tolerance Handling: The handling of network partitions is crucial for ensuring high availability. Systems employ techniques like redundant data centers, load balancing, and automatic failover mechanisms. This allows them to route traffic to functioning nodes, even if a portion of the system is isolated.
Trade-offs
Prioritizing availability over consistency, as in many real-world systems, introduces trade-offs. The degree of acceptable inconsistency depends on the specific application.
- Performance Impact: Implementing eventual consistency can improve performance and scalability, but it also introduces potential delays in data updates and inconsistencies for short periods. Users might see stale data, but the system can remain operational during these periods.
- Data Integrity: Maintaining data integrity can be challenging in systems prioritizing availability. Users may need to accommodate eventual consistency in their applications to avoid inconsistencies. Techniques like conflict resolution mechanisms can mitigate this risk.
- Application Design: Applications need to be designed to accommodate the chosen consistency model. Applications need to handle potential inconsistencies in data updates, such as data discrepancies or delayed updates.
Simplified Architecture
A simplified architecture illustrating CAP theorem application involves a distributed key-value store. Data is replicated across multiple nodes. Reads are performed from the closest available node. Writes are asynchronously replicated to all nodes.
| Component | Description |
|---|---|
| Client | Initiates read/write requests. |
| Data Node 1 | Stores data, participates in replication. |
| Data Node 2 | Stores data, participates in replication. |
| Data Node 3 | Stores data, participates in replication. |
| Replication Manager | Coordinates asynchronous replication. |
The architecture prioritizes availability over strict consistency. Data is eventually consistent, but not immediately. This architecture emphasizes the ability of the system to function under network partitions, with eventual data reconciliation.
Choosing the Right Strategy for Distributed Systems
The CAP theorem presents a fundamental trade-off in designing distributed systems. Understanding which attribute—consistency, availability, or partition tolerance—is most critical for a given application is paramount. This involves careful evaluation of the application’s requirements and potential risks. The optimal choice isn’t always obvious and requires a systematic approach.
Evaluating Application Requirements
To determine the appropriate CAP strategy, a thorough assessment of the application’s needs is essential. This involves analyzing the impact of each CAP attribute on the application’s functionality and user experience. Factors such as data sensitivity, user expectations, and potential downtime should be considered.
Factors Influencing CAP Choice
Several factors significantly influence the decision regarding which CAP attribute to prioritize. These include:
- Data Sensitivity: Highly sensitive data, such as financial records or personal information, often necessitates strong consistency, even at the expense of availability during periods of high demand or network partitions. Examples include banking applications or healthcare systems.
- User Expectations: Applications with high user expectations, such as e-commerce platforms or social media sites, often require high availability to maintain a seamless user experience. Downtime can lead to significant revenue loss or user frustration.
- Network Reliability: The reliability of the network infrastructure significantly impacts the feasibility of achieving high availability and consistency. In environments with frequent network partitions, systems may need to prioritize partition tolerance, even if it means sacrificing some degree of consistency or availability.
- Potential Downtime Impact: The cost and consequences of downtime are crucial factors. If downtime has a high financial impact or leads to critical consequences, prioritizing consistency and availability is more important.
- System Complexity: The complexity of the distributed system itself influences the choice. A simple system might permit stronger consistency and availability, while a complex system may need to prioritize partition tolerance.
Steps to Choose the Right Strategy
A structured approach to choosing the right CAP strategy can lead to a more informed decision.
- Identify the Critical Attributes: Carefully define the application’s most critical attributes. Consider the trade-offs between consistency, availability, and partition tolerance. For example, a critical banking application would prioritize consistency over availability, even in the presence of network partitions.
- Assess Potential Risks: Evaluate the potential risks associated with each CAP attribute. Consider the impact of inconsistencies, outages, and network partitions on the application’s functionality and user experience. For example, an e-commerce platform might prioritize availability to maintain user experience, even if it means sacrificing strong consistency in some situations.
- Determine the Optimal Balance: Identify the optimal balance of CAP attributes that aligns with the application’s requirements. This involves carefully weighing the factors discussed above. For instance, a social media platform might choose a strategy that balances availability and consistency, while maintaining acceptable levels of partition tolerance.
- Select the Appropriate Database: Choose a distributed database system that supports the chosen CAP strategy. Consider the specific needs of the application and the available database technologies.
Summary Table: Choosing the Right CAP Strategy
| Application | Critical Attributes | Optimal Balance | Database Type |
|---|---|---|---|
| E-commerce Platform | High Availability, User Experience | Prioritize Availability, Accept some Consistency Tradeoffs | NoSQL (e.g., Cassandra) |
| Banking Application | Data Integrity, Strong Consistency | Prioritize Consistency, Accept Limited Availability during Partitions | Relational Database (e.g., PostgreSQL) |
| Social Media Platform | High Availability, Real-time Updates | Balance Availability and Consistency, Moderate Partition Tolerance | NoSQL (e.g., MongoDB) |
Emerging Trends in Distributed Databases
Distributed databases are evolving rapidly, driven by the need for scalability, performance, and resilience in modern applications. These advancements often grapple with the complexities of the CAP theorem, necessitating innovative approaches to data management. This section explores current trends and their implications for future distributed systems.
Serverless Computing in Database Services
Serverless architectures are gaining traction in distributed database deployments. Instead of managing servers, developers focus on deploying functions and code triggered by events. This approach simplifies administration and reduces operational overhead. This shift also allows for more dynamic scaling based on demand. The serverless nature of these solutions often aligns well with the availability aspect of the CAP theorem, as scaling is automatic and transparent.
However, ensuring consistency across these dynamic environments requires sophisticated design patterns and efficient data synchronization strategies.
Federated Databases and Data Mesh
Federated databases and data meshes are emerging as powerful tools for managing diverse data sources in distributed environments. Federated databases allow for the integration of data from multiple, potentially disparate, systems. Data meshes take this further, providing a more comprehensive framework for organizing, managing, and accessing data from various sources within an organization. This approach can address the challenges of data consistency across multiple data stores by implementing sophisticated data governance policies and data integration pipelines.
The decentralized nature of data meshes is aligned with the concept of partition tolerance. Data consistency is achieved through careful design of the integration processes.
Graph Databases and Knowledge Graphs
Graph databases are becoming increasingly popular for managing relationships between data. The relational model often struggles to represent complex interconnected data efficiently. Graph databases excel in modeling these relationships, leading to more intuitive and efficient queries. The use of knowledge graphs builds on this by integrating data from multiple sources to create a holistic understanding. This approach is not necessarily tied to any specific CAP theorem consideration but can influence the choice of consistency model.
The emphasis is on enabling fast, meaningful query operations over the connected data.
In-Memory Databases and Hybrid Approaches
In-memory databases are experiencing a resurgence. These systems store data in RAM, enabling extremely fast read and write operations. The consistency of these databases often needs to be carefully managed, as they rely heavily on the memory’s availability. Hybrid approaches combine the speed of in-memory databases with the durability of disk-based systems, providing a balance between performance and resilience.
These approaches are particularly relevant for applications where high throughput is paramount.
Table
| Emerging Trend | Description | CAP Theorem Considerations | Example |
|---|---|---|---|
| Serverless Databases | Database services without server management, scaling automatically. | Prioritizes availability; consistency requires sophisticated mechanisms. | AWS DynamoDB |
| Federated Databases/Data Mesh | Integrate data from multiple sources. | Facilitates partition tolerance by allowing distributed data. Consistency managed through data integration. | Apache Kafka, Apache Cassandra |
| Graph Databases | Efficiently manage relationships between data. | Consistency model depends on the specific use case. | Neo4j |
| In-Memory Databases | Store data in RAM for extremely fast access. | Availability and consistency need careful balancing; high potential for data loss if power is lost. | Redis |
Scalability and the CAP Theorem
Scalability is a crucial aspect of distributed databases, aiming to handle increasing data volumes and user traffic without performance degradation. Understanding how scalability interacts with the CAP theorem is vital for designing robust and efficient distributed systems. A system’s ability to scale impacts its consistency, availability, and tolerance to partitions, and these attributes are directly linked to the CAP theorem.The CAP theorem dictates a fundamental trade-off in distributed systems.
Attempting to maximize all three properties (consistency, availability, and partition tolerance) simultaneously is impossible. Scalability strategies must consider these inherent limitations and prioritize the properties that are most crucial for a given application. The impact of scaling on these properties is not uniform; different scaling techniques will affect consistency, availability, and partition tolerance in distinct ways.
Impact of Scaling on CAP Theorem Properties
Scaling a distributed database can significantly influence the system’s ability to maintain consistency, availability, and partition tolerance. Increased data volume and user load can strain the system, potentially leading to inconsistencies or unavailability if the system is not designed appropriately. The choice of scaling technique directly impacts the balance between these properties.
Strategies for Achieving Scalability in Distributed Databases
Various strategies exist to achieve scalability in distributed databases. Understanding the strengths and weaknesses of each strategy in relation to the CAP theorem is essential.
- Horizontal Scaling: This strategy involves adding more nodes to the system. By distributing the workload across multiple machines, horizontal scaling improves availability and partition tolerance. However, it can lead to more complex consistency management and potentially increase the risk of data inconsistencies if not properly managed.
- Vertical Scaling: This method focuses on increasing the resources (CPU, memory, storage) of existing nodes. While simple to implement, it has limitations in handling large-scale growth. It may improve performance for a specific workload but ultimately reaches a point of diminishing returns. It may also not scale effectively for a highly partitioned environment.
- Database Sharding: This technique involves partitioning the data across multiple databases (shards). Sharding enhances scalability by distributing data evenly across the shards, thus improving read and write performance. Proper sharding strategies are essential to maintain consistency across shards and handle partitions gracefully. However, this can lead to increased complexity in data management and consistency enforcement.
- Data Replication: This strategy involves creating copies of data across multiple nodes. This enhances availability, as queries can be processed from any available replica. Data replication can be complex, as maintaining consistency across replicas is critical. This approach can be beneficial in scaling for availability, but it may not directly address partition tolerance issues.
Correlation between Scalability and CAP Theorem Properties
The choice of scalability strategy significantly impacts the system’s CAP theorem attributes. A system prioritizing availability might employ replication, potentially sacrificing consistency in the face of high write load. Conversely, a system emphasizing consistency might opt for vertical scaling, potentially limiting its overall scalability.
Effect of Scaling Techniques on CAP Theorem Attributes
| Scaling Technique | Consistency | Availability | Partition Tolerance |
|---|---|---|---|
| Horizontal Scaling | Potentially reduced, requires careful design | Improved | Improved |
| Vertical Scaling | Improved | Limited improvement | Limited improvement |
| Database Sharding | Potentially reduced, needs sharding strategy | Improved | Improved |
| Data Replication | Reduced (depending on replication strategy) | Improved | Improved (but may require additional strategies for partitions) |
Fault Tolerance and the CAP Theorem
Fault tolerance is a critical aspect of distributed database systems, enabling them to continue operating even when some components fail. The CAP theorem, while not directly addressing fault tolerance, provides a framework for understanding the trade-offs involved in designing resilient systems. This section explores the intricate relationship between fault tolerance and the CAP theorem, analyzing the impact of failures on the properties of consistency, availability, and partition tolerance.Understanding how failures influence CAP properties is essential for creating robust distributed systems.
A distributed system’s ability to handle failures directly affects its ability to adhere to the principles Artikeld in the CAP theorem. This section will explore the design principles of fault-tolerant systems and illustrate how these strategies influence the CAP theorem.
Relationship Between Fault Tolerance and CAP Theorem Properties
Fault tolerance, in the context of distributed databases, aims to maintain system operation even when components or connections fail. This directly impacts the CAP theorem properties. For example, a system prioritizing availability might tolerate temporary failures, potentially sacrificing strict consistency. Conversely, a system focused on consistency might exhibit lower availability during periods of failure. Partition tolerance, as a given, ensures the system remains operational even if network partitions occur.
Impact of Failures on CAP Theorem Properties
Failures can significantly impact the CAP theorem properties. Network partitions, for instance, can lead to temporary unavailability. Node failures can disrupt data consistency. A database prioritizing availability might temporarily return stale data during a node failure to ensure ongoing service, potentially sacrificing strict consistency. Conversely, a database prioritizing consistency might temporarily block access until the system can guarantee the consistency of the data.
The choice of strategy directly influences the CAP theorem trade-offs.
Methods for Building Fault-Tolerant Distributed Systems
Various methods exist for building fault-tolerant distributed systems. Redundancy is a fundamental strategy, where multiple copies of data and/or services are maintained across different nodes. This redundancy allows the system to continue operating even if some nodes fail. Replication and clustering are specific forms of redundancy that are commonly used in distributed databases. Moreover, proactive monitoring and recovery mechanisms are crucial for swift detection and resolution of failures, thereby minimizing downtime and data loss.
Fault Tolerance Strategies and their Influence on the CAP Theorem
The choice of fault tolerance strategy directly impacts the CAP theorem properties. A strategy emphasizing redundancy often leads to increased availability and consistency, potentially at the cost of reduced performance or increased complexity. Conversely, a strategy emphasizing low redundancy, such as in highly available but not necessarily consistent systems, prioritizes availability. The table below illustrates the common fault tolerance strategies and their corresponding implications on the CAP theorem.
| Fault Tolerance Strategy | Effect on Consistency | Effect on Availability | Effect on Partition Tolerance |
|---|---|---|---|
| Redundancy (Replication, Clustering) | Increased, potentially at a performance cost | Increased | Maintained |
| Active-Passive Replication | High | High | Maintained |
| Load Balancing | Moderate, depends on strategy | Increased | Maintained |
| Proactive Monitoring and Recovery | High, in combination with other strategies | High | Maintained |
| Distributed Transaction Management | High | Potentially reduced | Maintained |
Advanced Topics in CAP Theorem
The CAP theorem, while foundational, doesn’t fully capture the nuanced realities of modern distributed database design. Real-world systems often require intricate trade-offs and specialized protocols to achieve desired consistency and availability levels. This section delves into advanced concepts and their implications for database architects.Distributed systems, especially those dealing with high volumes of data and transactions, demand more sophisticated approaches to managing consistency and availability.
The complexities of ensuring a reliable and efficient system are often addressed through advanced consistency protocols and specialized algorithms.
Consistency Protocols
Various consistency protocols address the challenge of maintaining data consistency in a distributed environment. These protocols define the rules for how data is replicated and updated across multiple nodes.Different consistency protocols offer varying levels of consistency and availability, each with its own trade-offs. The choice of protocol depends heavily on the specific application requirements and the acceptable level of latency and potential for data inconsistencies.
For example, eventual consistency is often chosen for applications where rapid updates are less critical than maintaining a consistent view over time.
- Eventual Consistency: This protocol ensures that data will eventually become consistent across all nodes, but not necessarily in real-time. It’s suitable for applications where data freshness isn’t paramount, like social media feeds or collaborative document editing, where the eventual consistency allows for faster updates and reduced latency.
- Strong Consistency: This protocol guarantees that all nodes see the same data at the same time, ensuring immediate consistency across all replicas. This is crucial in applications requiring strict consistency, such as financial transactions or banking systems.
- Sequential Consistency: Ensures that operations appear to be executed in a specific order across all nodes. This is a stronger form of consistency than eventual consistency, but weaker than strong consistency. It’s a suitable choice when the ordering of operations is critical.
Impact on Distributed Database Design
The selection of a consistency protocol directly impacts the design of a distributed database. For instance, strong consistency requires more complex mechanisms for data replication and validation, potentially leading to higher latency and resource consumption.Choosing the right protocol necessitates careful consideration of the application’s requirements, the expected data volume, and the acceptable level of latency. Databases designed for eventual consistency will often feature simpler replication strategies, whereas those demanding strong consistency will require more sophisticated synchronization protocols.
Advanced CAP Theorem Applications
The CAP theorem is not just theoretical; it guides the practical design of numerous distributed systems.
- Cloud-based databases: Cloud providers leverage various consistency protocols to ensure data availability and consistency for their customers, while also optimizing for scalability and cost-effectiveness. For example, Amazon DynamoDB utilizes eventual consistency to offer high availability and scalability, while Google Cloud Spanner prioritizes strong consistency, albeit at a higher cost.
- Distributed key-value stores: These systems often use eventual consistency to maintain high availability and performance. The trade-off between consistency and availability is a critical design decision, affecting the functionality and performance of the system.
- Microservices architectures: The CAP theorem’s principles influence the design of data access and synchronization within a microservices environment. Appropriate consistency protocols are essential for managing data consistency and ensuring that changes are reflected across different services.
Achieving Balance in Modern Systems
Striking the perfect balance between consistency, availability, and partition tolerance in modern systems is a constant challenge.
A perfect balance is often unattainable; rather, the focus is on selecting the appropriate trade-offs based on the specific needs of the application.
The complexity stems from the ever-increasing scale and complexity of distributed systems. Modern systems need to handle massive amounts of data and transactions while ensuring high availability, often in the face of network partitions. Advanced algorithms and techniques are continuously being developed to optimize performance and consistency in these challenging environments.
Summary Table
| Advanced Topic | Impact on CAP Theorem |
|---|---|
| Consistency Protocols | Directly influence the choice between consistency and availability levels, affecting database design and performance. |
| Distributed Database Design | Database architecture must accommodate the chosen consistency protocol, impacting replication strategies, synchronization protocols, and overall system complexity. |
| Advanced Applications | Practical implementations of the CAP theorem principles in cloud-based databases, distributed key-value stores, and microservices architectures highlight the trade-offs and design considerations. |
| Balance in Modern Systems | Achieving a perfect balance is often a trade-off; the focus is on selecting the best trade-offs based on application needs. |
Ending Remarks

In conclusion, understanding CAP theorem is essential for any developer working with distributed databases. The core concepts of consistency, availability, and partition tolerance provide a framework for evaluating and choosing the appropriate strategy for a given application. The trade-offs involved in balancing these attributes are crucial, and this guide has highlighted the importance of carefully considering these factors to achieve optimal system performance and resilience in distributed environments.
The diverse range of database types, practical examples, and emerging trends presented showcase the breadth and depth of the CAP theorem’s impact on modern data management.
Detailed FAQs
What are the common pitfalls in choosing a CAP theorem strategy?
Often, developers may prioritize one attribute over others without fully understanding the potential consequences. A critical pitfall is neglecting to consider the specific needs of the application, leading to inefficiencies and performance issues. Thorough analysis and planning are essential to achieving the best possible balance of CAP attributes.
How does the CAP theorem relate to data consistency?
The CAP theorem highlights that you cannot simultaneously guarantee consistency, availability, and partition tolerance in a distributed system. Choosing a consistency model, like strong or eventual consistency, directly impacts the trade-offs between these attributes. Strong consistency, for instance, often prioritizes data integrity over responsiveness, whereas eventual consistency may sacrifice some data consistency for improved availability.
What are some emerging trends in distributed database design that address CAP theorem considerations?
Emerging trends like the use of hybrid architectures, sophisticated replication strategies, and advanced consistency protocols aim to mitigate the trade-offs inherent in the CAP theorem. These developments seek to provide a better balance between data consistency, system availability, and resilience to network partitions.
How can I evaluate the optimal balance of CAP attributes for a specific use case?
Evaluating the optimal balance requires a thorough understanding of the application’s specific requirements and constraints. Consider factors like expected data volume, read/write frequency, tolerance for data inconsistencies, and acceptable latency. This careful analysis helps determine which attribute (consistency, availability, or partition tolerance) should be prioritized.