The architecture of modern cloud applications often relies on event-driven programming, where actions in one service automatically trigger responses in others. At the heart of this paradigm lies the ability to connect services seamlessly. This guide explores the mechanism of triggering AWS Lambda functions in response to events within an Amazon S3 bucket, a fundamental technique in building scalable and responsive cloud solutions.
The discussion will delve into the technical intricacies, from setting up event notifications to crafting effective error handling strategies, providing a robust understanding of the process.
This guide will navigate through the core components, examining the event types that initiate Lambda execution, configuring the S3 bucket for event notifications, and crafting Lambda functions to process the incoming data. We will dissect the event data structure, detailing how to access and interpret the information provided by S
3. Furthermore, we’ll cover crucial aspects like IAM permissions, ensuring the secure and reliable operation of the entire system.
Finally, we will explore advanced configurations, including parallel processing and versioning, to optimize performance and manage deployments effectively.
Introduction: Serverless Architecture and Event-Driven Processing
Serverless computing represents a paradigm shift in cloud architecture, abstracting away the underlying infrastructure management responsibilities from developers. This allows for a focus on writing and deploying code without the need to provision, manage, or scale servers. This approach enhances agility, reduces operational overhead, and can optimize costs, particularly for workloads with fluctuating demands.This content explores how Amazon S3 (Simple Storage Service) and AWS Lambda, core components of the serverless ecosystem, can be integrated to create event-driven workflows.
These workflows react automatically to changes in data stored in S3, triggering custom logic defined within Lambda functions. This integration offers a powerful and cost-effective method for processing data in real-time.
Fundamental Concepts: Amazon S3 and AWS Lambda
Amazon S3 is a highly scalable, durable, and cost-effective object storage service. It provides a reliable platform for storing virtually any amount of data, including images, videos, documents, and backups. S3’s object-based storage allows for data organization using buckets and objects, each identified by a unique key. S3’s inherent scalability and durability make it an ideal choice for data lakes, content distribution, and archival storage.AWS Lambda is a serverless compute service that executes code in response to events.
These events can originate from various AWS services, including S3, DynamoDB, and API Gateway, as well as from custom applications. Lambda automatically manages the compute resources required to run the code, eliminating the need for server provisioning or management. Developers simply upload their code, configure triggers, and Lambda handles the rest, providing automatic scaling, high availability, and pay-per-use pricing.
Common Use Cases: S3 Event Triggers for Lambda Functions
The integration of S3 and Lambda creates a potent combination for automating data processing tasks. S3 events, such as object creation, deletion, or modification, can trigger Lambda functions, enabling a variety of use cases. These use cases often revolve around data transformation, validation, and analysis.
- Image Processing: When a new image is uploaded to an S3 bucket, a Lambda function can be triggered to resize, optimize, or apply watermarks. This automated processing ensures images are correctly formatted and optimized for different platforms and uses. For instance, a photo-sharing website can automatically generate thumbnails of uploaded images using this approach. This eliminates the need for manual intervention and ensures consistent image presentation.
- Data Validation and Transformation: When a data file (e.g., CSV, JSON) is uploaded, a Lambda function can validate its format, transform the data into a usable format, and load it into a database or data warehouse. This automated process is critical for ensuring data quality and consistency. For example, a company could automatically convert CSV files uploaded by vendors into a standardized format before importing them into its data analytics platform.
- Data Archiving and Backup: Lambda functions can be triggered by S3 events to archive data, create backups, or move data between storage tiers based on lifecycle policies. This automation ensures data is protected and managed according to regulatory requirements and business needs. A healthcare provider, for instance, could use this to automatically move patient records from a frequently accessed storage tier to a lower-cost archival tier after a specific period.
- Real-time Notifications: Lambda functions can be triggered to send notifications (e.g., emails, SMS messages) to users or administrators when specific events occur in S3, such as the upload of a new document or the deletion of a file. This can be used to alert users of completed tasks or to notify administrators of potential issues. For example, a file-sharing service could send an email notification to a user when a file they requested is available for download.
- Log Processing and Analysis: Lambda functions can process log files stored in S3, extracting valuable insights and generating reports. This helps to identify trends, detect anomalies, and monitor system performance. For example, a website operator can use this to analyze web server logs, identify performance bottlenecks, and improve user experience.
S3 Events
Amazon S3’s event notification system is a cornerstone of serverless architectures, enabling responsive and automated workflows. It allows for real-time processing of data uploaded to or modified within an S3 bucket. This capability hinges on the different event types S3 emits, the configuration options available for these events, and the filtering mechanisms that allow for precise control over which actions trigger a Lambda function.
Understanding these components is crucial for designing efficient and scalable serverless applications.
S3 Event Types
S3 events are the triggers that initiate actions in response to specific operations performed on objects within an S3 bucket. Each event type corresponds to a particular action, providing granular control over the events that trigger Lambda functions.The key event types include:
- ObjectCreated: Triggered when a new object is created in the bucket. This includes uploads via PUT requests, POST requests, and multipart uploads. This is a commonly used event for processing newly uploaded files, such as images, videos, or data files.
- ObjectRemoved: Triggered when an object is deleted from the bucket. This includes both DELETE requests and object lifecycle transitions that result in deletion. This is useful for cleanup tasks, such as removing associated metadata or deleting related resources.
- ObjectRestore: Triggered when an object is restored from Glacier. This event is important when working with archived data.
- ObjectTiering: Triggered when an object’s storage class is changed. This can be used to monitor or react to lifecycle policies moving objects between storage tiers.
- ObjectAccess: Triggered when an object is accessed. This event can be used for auditing or logging object access patterns.
- Lifecycle Events: These encompass events related to lifecycle rules, such as transitions to different storage classes (e.g., Standard to Infrequent Access) or deletion. They offer control over data management based on defined policies.
Configuring S3 Event Notifications
Configuring S3 event notifications is performed through the AWS Management Console, the AWS CLI, or via Infrastructure as Code (IaC) tools like AWS CloudFormation or Terraform. The process involves specifying the event types to monitor and the destination for those events, typically a Lambda function.The configuration process within the S3 console generally involves the following steps:
- Navigate to the S3 bucket: In the AWS Management Console, navigate to the S3 service and select the bucket you want to configure event notifications for.
- Access the Properties tab: Within the bucket’s details, go to the “Properties” tab.
- Configure Event Notifications: Scroll down to the “Event notifications” section and click “Create event notification.”
- Define Event Name and Prefix/Suffix Filters: Provide a descriptive name for the event notification. Configure the prefix and suffix filters (discussed later) to narrow down the events that trigger the function.
- Choose Event Types: Select the specific event types you want to trigger your Lambda function. Multiple event types can be selected.
- Choose Destination: Select the destination for the event notifications. This is typically a Lambda function.
- Select Lambda Function: If a Lambda function is selected as the destination, choose the appropriate function from the dropdown menu.
- Grant Permissions (if necessary): If the Lambda function does not already have permission to be invoked by S3, the console will guide you through granting the necessary permissions.
- Save Configuration: Save the event notification configuration.
After saving, S3 will begin sending event notifications to the specified Lambda function when the configured events occur. Monitoring the function’s logs in CloudWatch is essential to verify correct event triggering and troubleshoot any issues.
Specifying Event Filters
Event filters provide a mechanism to refine the events that trigger a Lambda function, allowing for more targeted and efficient processing. They enable developers to specify criteria based on object prefixes and suffixes.Prefix and suffix filters are configured within the event notification settings:
- Prefix Filter: This filter specifies a prefix that an object’s key (the full path to the object within the bucket) must match to trigger the event. For example, a prefix of “images/” would only trigger the function for objects whose keys start with “images/”. This is useful for processing files within a specific directory or folder structure.
- Suffix Filter: This filter specifies a suffix that an object’s key must match to trigger the event. For example, a suffix of “.jpg” would only trigger the function for objects whose keys end with “.jpg”. This is useful for processing specific file types, such as images or documents.
Filters are applied to the object key, and both prefix and suffix filters can be used together to narrow down the scope of events.For example, to trigger a Lambda function only when a new JPEG image is uploaded to an “images/thumbnails/” directory, the following filters could be used:
- Prefix: images/thumbnails/
- Suffix: .jpg
This ensures that only new JPEG files uploaded to the specified directory trigger the function, improving efficiency and reducing unnecessary invocations.
Lambda Function Setup: The Processor
To effectively process S3 events, a Lambda function acts as the core component. This function, written in a chosen programming language, receives event data from S3, performs necessary operations, and provides the serverless architecture’s processing capabilities. The design and implementation of this Lambda function are critical for handling various S3 event types and ensuring proper data processing.
Designing a Lambda Function for S3 Event Data
The Lambda function design must consider the diverse range of S3 event types. A robust design anticipates potential errors, implements efficient resource utilization, and provides logging and monitoring capabilities for effective troubleshooting. The function’s logic should be modular and testable, with clear separation of concerns.
- Event Type Handling: The function must be capable of identifying and responding to different S3 event types, such as `ObjectCreated:Put`, `ObjectCreated:Post`, `ObjectRemoved:Delete`, etc. Each event type necessitates a specific processing strategy. For instance, an `ObjectCreated:Put` event might trigger image resizing, while an `ObjectRemoved:Delete` event could initiate data archiving.
- Data Extraction: The function needs to extract relevant information from the event data, including the bucket name, object key, and potentially the object’s metadata. This data is essential for performing the desired actions, such as retrieving the object from S3 or accessing its properties.
- Error Handling: Implementing robust error handling is crucial. The function should include `try-except` blocks (in Python) or equivalent mechanisms in other languages to catch exceptions that may occur during processing, such as network errors, file format issues, or permission problems. Log errors appropriately to CloudWatch for debugging.
- Resource Management: Efficient resource management is critical to avoid exceeding Lambda function limits. This includes optimizing code for memory usage, choosing appropriate execution times, and utilizing asynchronous processing where applicable to prevent long-running operations from blocking the function’s execution.
- Security Considerations: Secure access to S3 resources and other AWS services is paramount. Use IAM roles with the least privilege principle, granting the function only the necessary permissions. Encrypt sensitive data, and follow best practices for securing the function’s environment.
Organizing Lambda Function Code for Event Handling
Organizing the Lambda function code for graceful event handling improves readability, maintainability, and scalability. A structured approach facilitates the addition of new event types and the modification of existing processing logic without impacting the entire codebase.
- Event Dispatcher: Implement an event dispatcher that routes incoming events to the appropriate handler functions. This dispatcher analyzes the event type and directs the processing to the relevant code section. This approach promotes modularity and simplifies adding support for new event types.
- Handler Functions: Create dedicated handler functions for each S3 event type. Each handler function should focus on processing a specific event type, such as image resizing or object archiving. This separation of concerns enhances code clarity and makes debugging easier.
- Utility Functions: Develop utility functions for common tasks such as retrieving objects from S3, parsing metadata, or generating thumbnails. These functions should be reusable and testable, reducing code duplication and promoting consistency.
- Configuration Management: Externalize configuration settings, such as bucket names, API keys, and processing parameters, using environment variables or configuration files. This approach allows for easy modification of the function’s behavior without changing the code.
- Logging and Monitoring: Implement robust logging and monitoring capabilities using CloudWatch Logs and Metrics. Log important events, errors, and performance metrics to monitor the function’s health and identify potential issues.
Example Lambda Function for Logging Event Details to CloudWatch (Python)
This example demonstrates a Python Lambda function that logs the event details received from S3 to CloudWatch. This basic example provides a foundation for more complex processing tasks. The function’s primary function is to receive an S3 event, extract relevant information, and log it.“`pythonimport jsonimport boto3s3 = boto3.client(‘s3’)def lambda_handler(event, context): “”” Lambda function to process S3 events and log details.
“”” for record in event[‘Records’]: bucket = record[‘s3’][‘bucket’][‘name’] key = record[‘s3’][‘object’][‘key’] event_name = record[‘eventName’] size = record[‘s3’][‘object’][‘size’] print(f”Event Name: event_name”) print(f”Bucket: bucket”) print(f”Key: key”) print(f”Size: size bytes”) try: response = s3.get_object(Bucket=bucket, Key=key) # You can add further processing here, e.g., analyze object content print(f”Object retrieved successfully from bucket: bucket, key: key”) except Exception as e: print(f”Error retrieving object: e”) raise e # Re-raise the exception to trigger a retry or failure return ‘statusCode’: 200, ‘body’: json.dumps(‘Successfully processed S3 events!’) “`This code example demonstrates the essential components of a Lambda function designed to handle S3 events.
The function begins by importing the necessary libraries: `json` for handling JSON data and `boto3` for interacting with AWS services, specifically S3. The `s3` client is initialized to interact with S3. The core logic resides within the `lambda_handler` function, which is the entry point for all Lambda function invocations. The `event` parameter contains the event data from S3. The function iterates through each record in the `event[‘Records’]` list.
For each record, it extracts key details such as the bucket name, object key, event name, and object size. These details are then printed to the CloudWatch logs. A `try-except` block is used to handle potential errors when retrieving the object. The `get_object` method retrieves the object from S3. If the retrieval is successful, a success message is logged.
If an error occurs, an error message is logged, and the exception is re-raised to trigger potential retries or failures. Finally, the function returns a JSON response indicating successful processing.
IAM Permissions: The Authorizations
Implementing a serverless architecture requires careful consideration of security, particularly concerning access control and resource permissions. Securely integrating S3 events with Lambda functions necessitates a robust and well-defined IAM (Identity and Access Management) policy. This ensures that the Lambda function can be triggered by S3 events and can access and process the data within the specified S3 bucket without unauthorized access or privilege escalation.
Proper IAM configuration is crucial for maintaining the integrity and confidentiality of data stored in S3.
Necessary IAM Permissions for S3 and Lambda
To enable the seamless interaction between S3 and Lambda, specific permissions must be granted to both resources. These permissions dictate the actions that each service is authorized to perform. The following permissions are essential for a functional S3 event trigger setup:
- S3 Bucket Permissions: The S3 bucket requires a policy that grants permission to allow S3 to invoke the Lambda function. This is typically achieved by specifying the `s3:ObjectCreated:*` event (or a more specific event like `s3:ObjectCreated:Put`) and the ARN (Amazon Resource Name) of the Lambda function in the bucket policy. Without this, S3 will not be able to trigger the Lambda function.
- Lambda Function Permissions: The Lambda function’s execution role requires permissions to access the S3 bucket. This typically involves granting the `s3:GetObject` permission (or other relevant permissions based on the function’s requirements) on the specific S3 bucket and optionally the `s3:ListBucket` permission. These permissions enable the Lambda function to retrieve the object from the S3 bucket upon receiving an event. The function also requires permission to log to CloudWatch for monitoring and debugging purposes, typically via the `logs:CreateLogGroup`, `logs:CreateLogStream`, and `logs:PutLogEvents` permissions.
The Role of the Lambda Execution Role and Its Permissions
The Lambda execution role is a crucial component of the security model. It defines the permissions that the Lambda function assumes when it is executed. This role acts as the identity of the function, dictating what actions the function is authorized to perform. The principle of least privilege should be applied when defining the Lambda execution role. This means granting only the minimum set of permissions necessary for the function to operate.
This approach minimizes the potential impact of a security breach.
- Key Permissions within the Execution Role: The execution role requires the following core permissions:
- s3:GetObject: Allows the Lambda function to retrieve objects from the S3 bucket. This is essential if the function needs to process the content of the uploaded objects.
- s3:ListBucket: Allows the Lambda function to list the objects within the S3 bucket. This permission is sometimes required, especially if the function needs to iterate through multiple objects or perform operations that require listing the bucket contents.
- logs:CreateLogGroup, logs:CreateLogStream, logs:PutLogEvents: Permits the Lambda function to write logs to CloudWatch. These logs are critical for monitoring the function’s execution, debugging issues, and gaining insights into its performance.
- Principle of Least Privilege in Practice: Consider a scenario where the Lambda function only needs to process text files uploaded to a specific S3 bucket. In this case, the execution role should only grant `s3:GetObject` permission on the bucket and the `s3:ListBucket` permission, along with the necessary CloudWatch logging permissions. This prevents the function from accessing other resources or performing unauthorized actions, such as deleting objects.
If the function is intended to only read files with a specific prefix, the policy can be further refined to only allow access to objects with that prefix.
Creating an IAM Role with Required Permissions
Creating an IAM role with the appropriate permissions can be accomplished through the AWS console or the AWS CLI (Command Line Interface). The process involves defining the trust relationship (who can assume the role) and the permissions policy (what actions the role is allowed to perform).
- Creating the Role via the AWS Console:
- Navigate to the IAM service in the AWS console.
- Select “Roles” and then click “Create role.”
- Choose “Lambda” as the trusted entity, as this will allow the Lambda service to assume this role.
- Attach the necessary policies to the role. You can either select existing managed policies (such as `AWSLambdaBasicExecutionRole` for basic logging) or create a custom policy. For S3 access, create a custom policy with the required S3 permissions, specifying the bucket and the allowed actions. For example, to grant read access to all objects in a bucket named `my-bucket`, the policy would include a statement like:
- Provide a role name and description, and then create the role.
- Creating the Role via the AWS CLI:
- Use the `aws iam create-role` command to create the role. The command requires specifying the role name and a trust relationship policy document (in JSON format). The trust relationship policy defines which service can assume the role. For Lambda, the trust relationship policy will allow the Lambda service to assume the role.
- Use the `aws iam put-role-policy` command to attach a policy to the role. This command requires the role name, policy name, and a policy document (in JSON format). The policy document specifies the permissions that the role grants. For instance, to create a role named “lambda-s3-access-role” with access to an S3 bucket named “my-bucket” (and basic logging), the following CLI commands could be used:
- The policy document should specify the actions (e.g., `s3:GetObject`, `s3:ListBucket`) and the resources (e.g., the ARN of the S3 bucket) that the role is allowed to access.
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::my-bucket",
"arn:aws:s3:::my-bucket/*"
]
aws iam create-role --role-name lambda-s3-access-role --assume-role-policy-document file://trust-policy.json
aws iam put-role-policy --role-name lambda-s3-access-role --policy-name s3-access-policy --policy-document file://s3-policy.json
where `trust-policy.json` and `s3-policy.json` contain the appropriate JSON policy documents. The `trust-policy.json` would specify the Lambda service as the principal. The `s3-policy.json` would specify the S3 permissions.
Configuring the Trigger

Configuring the trigger is the crucial step in establishing the event-driven architecture. It connects the S3 bucket to the Lambda function, specifying which S3 events should initiate the function’s execution. This configuration is the linchpin that enables the serverless workflow, automatically processing data uploads and other bucket events.
Configuring S3 Bucket Events
To configure an S3 bucket to trigger a Lambda function, the following steps are necessary. This process involves accessing the S3 console, selecting the target bucket, and defining the event notifications.
- Accessing the S3 Console and Selecting the Bucket: Navigate to the Amazon S3 console in the AWS Management Console. Select the specific S3 bucket that will generate the events. This bucket is the source of the events that will trigger the Lambda function.
- Navigating to the Properties Tab: Within the selected bucket, go to the “Properties” tab. This tab provides configuration options for the bucket, including event notifications.
- Configuring Event Notifications: Scroll down to the “Event notifications” section and click “Create event notification.” This initiates the process of defining the event trigger.
- Defining Event Types: Specify the event types that will trigger the Lambda function. Common event types include:
s3:ObjectCreated:*: Triggers when a new object is created in the bucket. This is the most common use case for data processing upon upload.s3:ObjectRemoved:*: Triggers when an object is deleted from the bucket.s3:ObjectRestore:Completed: Triggers when an object is restored from Glacier.
- Specifying Object Prefix and Suffix (Optional): Refine the event trigger by specifying object prefixes and suffixes. This filters events based on the object’s key (filename or path). For example, a prefix of “images/” will only trigger the function for objects uploaded to the “images/” directory. A suffix of “.jpg” will trigger the function only for JPG image uploads.
- Selecting the Destination: Choose “Lambda function” as the destination. This indicates that the event should trigger a Lambda function.
- Selecting the Lambda Function: In the “Lambda function” dropdown, select the Lambda function’s ARN.
- Saving the Configuration: Save the event notification configuration. After saving, the S3 bucket is configured to trigger the Lambda function based on the defined events.
Role of the Lambda Function’s ARN
The Lambda function’s ARN (Amazon Resource Name) plays a critical role in the trigger configuration. It uniquely identifies the Lambda function within the AWS ecosystem. The ARN is used by the S3 bucket to target the correct function for invocation upon an event.
The ARN follows a specific format:
arn:aws:lambda:[region]:[account-id]:function:[function-name]
The region specifies the AWS region where the Lambda function is deployed. The account ID is the AWS account number, and the function name is the name given to the Lambda function.
Using the correct ARN is essential. Incorrect ARNs will result in the event not triggering the intended Lambda function, causing processing failures.
Testing the Trigger Configuration
Testing the trigger configuration validates that the S3 bucket is correctly configured to invoke the Lambda function. This is done by uploading a sample object to the S3 bucket and observing the function’s execution.
- Uploading a Sample Object: Upload a sample object (e.g., a text file, an image) to the S3 bucket. Ensure that the object’s key (filename) and location within the bucket match any prefix or suffix filters defined in the event notification configuration.
- Monitoring the Lambda Function’s Execution: After the object is uploaded, monitor the Lambda function’s execution logs in the CloudWatch console. This console is accessible through the AWS Management Console.
- Checking the Logs: Examine the function’s logs for any errors. Successful execution will show log entries generated by the Lambda function, indicating that the function was triggered by the S3 event. The logs will also show the details of the event, including the object key, bucket name, and other relevant information.
- Verifying the Processed Output (If Applicable): If the Lambda function processes the uploaded object (e.g., resizing an image), verify that the processed output is available in the designated location (e.g., another S3 bucket).
- Troubleshooting if Necessary: If the Lambda function is not triggered or fails, review the following:
- The event notification configuration in the S3 bucket for any errors.
- The Lambda function’s permissions (IAM role) to ensure it has the necessary permissions to access the S3 bucket.
- The Lambda function’s code for any errors.
Event Data Structure

The interaction between an S3 event and a Lambda function is facilitated by a structured event payload. This payload is a JSON document that provides comprehensive information about the S3 event that triggered the Lambda function. Understanding the structure and content of this payload is crucial for correctly parsing the data and implementing the desired functionality within the Lambda function.
Proper handling of the event data allows the function to access the necessary information, such as the object’s location and metadata, and to perform actions based on the specific event that occurred.
Key Components of the Event Payload
The event payload contains various key-value pairs that provide context about the S3 event. These components are essential for the Lambda function to identify the specific event, locate the affected object, and retrieve relevant metadata.
- Records Array: The root element of the event payload is a JSON array named “Records.” This array contains one or more event objects, each representing a single S3 event. In most cases, when an S3 event triggers a Lambda function, the “Records” array will contain a single event object. However, in certain scenarios, such as bulk operations, multiple events may be included.
- Event Source: Within each event object, the “eventSource” field specifies the service that originated the event. For S3 events, this field will always contain the value “aws:s3.”
- Event Name: The “eventName” field describes the type of event that occurred. Common event names include “ObjectCreated:Put” (for object creation via PUT), “ObjectCreated:Post” (for object creation via POST), “ObjectRemoved:Delete” (for object deletion), and “ObjectCreated:CompleteMultipartUpload” (for completion of a multipart upload).
- Event Time: The “eventTime” field provides the timestamp of when the event occurred, formatted according to the ISO 8601 standard. This timestamp is crucial for determining the sequence of events and for any time-sensitive operations within the Lambda function.
- S3 Object Details: The “s3” field contains a nested object that provides details about the S3 object involved in the event. Key sub-fields include:
- Bucket: The “bucket” field contains information about the S3 bucket, including its name (“name”) and Amazon Resource Name (ARN) (“arn”).
- Object: The “object” field contains details about the S3 object, including its key (“key,” which is the object’s path within the bucket), size (“size” in bytes), and any version ID (“versionId” if versioning is enabled).
Accessing and Parsing Event Data in Lambda Function Code
Accessing and parsing the event data within the Lambda function code is straightforward, regardless of the programming language used. The event payload is passed as an argument to the function’s handler. The structure of the event object remains consistent, allowing for easy access to the necessary data.
Example (Python):“`pythonimport jsondef lambda_handler(event, context): for record in event[‘Records’]: bucket_name = record[‘s3’][‘bucket’][‘name’] object_key = record[‘s3’][‘object’][‘key’] event_time = record[‘eventTime’] event_name = record[‘eventName’] print(f”Bucket: bucket_name”) print(f”Object Key: object_key”) print(f”Event Time: event_time”) print(f”Event Name: event_name”) # Example: Processing the object # In a real-world scenario, you’d perform operations # on the object here, such as downloading it, processing it, etc.
# This example only demonstrates how to extract the data. # # To download the object using boto3, the following could be used: # import boto3 # s3 = boto3.client(‘s3’) # try: # response = s3.get_object(Bucket=bucket_name, Key=object_key) # # Process the object’s content here # object_content = response[‘Body’].read().decode(‘utf-8’) # print(f”Object Content: object_content”) # except Exception as e: # print(f”Error downloading object: e”)“`
Example (Node.js):“`javascriptexports.handler = async (event) => for (const record of event.Records) const bucketName = record.s3.bucket.name; const objectKey = record.s3.object.key; const eventTime = record.eventTime; const eventName = record.eventName; console.log(`Bucket: $bucketName`); console.log(`Object Key: $objectKey`); console.log(`Event Time: $eventTime`); console.log(`Event Name: $eventName`); // Example: Processing the object // In a real-world scenario, you’d perform operations // on the object here, such as downloading it, processing it, etc.
// This example only demonstrates how to extract the data. // // To download the object using the AWS SDK for JavaScript, the following could be used: // const AWS = require(‘aws-sdk’); // const s3 = new AWS.S3(); // try // const params = // Bucket: bucketName, // Key: objectKey, // ; // const data = await s3.getObject(params).promise(); // // Process the object’s content here // const objectContent = data.Body.toString(‘utf-8’); // console.log(`Object Content: $objectContent`); // catch (err) // console.error(`Error downloading object: $err`); // return statusCode: 200, body: JSON.stringify(‘Successfully processed the events!’), ;;“`The examples above demonstrate how to extract the bucket name, object key, event time, and event name from the event payload.
The code then prints these values to the function’s logs. The commented-out sections in each example illustrate how to use the AWS SDK to interact with S3 and download the object’s content, providing a practical demonstration of how to process the object after the event is triggered. These examples show the core components of the event payload, allowing the developer to adapt them for various processing requirements, such as image resizing, data transformation, or data analysis.
Error Handling and Monitoring: Ensuring Reliability
Reliable serverless architectures necessitate robust error handling and comprehensive monitoring. These practices are crucial for maintaining system stability, identifying and resolving issues promptly, and ensuring data integrity. Implementing effective error handling strategies and leveraging monitoring tools allows for proactive management and optimization of Lambda function performance.
Error Handling Strategies Within Lambda Functions
Handling errors effectively within a Lambda function is critical for preventing cascading failures and maintaining the overall health of the application. Different error types require specific handling mechanisms to ensure resilience and data integrity. Consider the following approaches to address potential issues:
- Exception Handling: Implementing `try-except` blocks within the function code allows for the graceful handling of exceptions. This prevents the function from crashing due to unexpected errors. The `except` block can log the error, take corrective action (e.g., retrying an operation), or return a meaningful error response. For instance, in Python:
“`python
try:
# Code that might raise an exception
result = some_operation()
except Exception as e:
# Handle the exception
print(f”An error occurred: e”)
# Log the error to CloudWatch
logger.error(f”Error details: e”)
# Potentially retry the operation or take other actions
“` - Input Validation: Validate the input data received from the S3 event before processing it. This prevents errors caused by malformed or unexpected data. Implement checks to ensure data types, formats, and ranges are as expected. For example, if the function expects a specific file type, check the file extension before attempting to process the file content. If input validation fails, the function should log the error and potentially return an error response or discard the invalid data.
- Idempotency: Design functions to be idempotent, meaning that running the same operation multiple times has the same effect as running it once. This is crucial when dealing with retries. For instance, when writing data to a database, use unique identifiers or other mechanisms to prevent duplicate entries. This helps ensure data consistency in the face of failures and retries.
- Circuit Breakers: For operations that interact with external services, implement circuit breakers. If a service becomes unavailable or unreliable, the circuit breaker prevents the function from repeatedly attempting to connect, which could lead to cascading failures. After a certain number of failures, the circuit breaker opens, and subsequent requests are rejected until the service recovers. Libraries like `pybreaker` (for Python) can be used to implement circuit breakers.
- Retry Mechanisms: Implement retry logic for operations that might temporarily fail due to transient issues, such as network problems or service unavailability. Use exponential backoff to avoid overwhelming the service. Limit the number of retries to prevent infinite loops. AWS SDKs often include built-in retry mechanisms that can be configured.
Importance of Logging and Monitoring with CloudWatch
Effective monitoring is paramount for understanding the behavior of Lambda functions, identifying performance bottlenecks, and detecting errors. AWS CloudWatch provides a comprehensive suite of tools for monitoring and analyzing Lambda function executions. Leveraging CloudWatch enables real-time insights into function performance, error rates, and resource utilization. This information is crucial for troubleshooting issues, optimizing performance, and ensuring the overall health of the serverless application.
- CloudWatch Logs: CloudWatch Logs automatically collects logs from Lambda function executions. These logs provide detailed information about function invocations, including timestamps, function input, output, and any errors that occurred. Analyze logs to identify the root causes of errors, track function performance, and debug issues. Structure logs consistently (e.g., using JSON format) to facilitate easier analysis.
- CloudWatch Metrics: CloudWatch Metrics provides pre-built and custom metrics to monitor function performance. Key metrics include invocation count, duration, errors, throttled invocations, and concurrent executions. Create custom metrics to track specific aspects of function behavior. Set up alarms based on metric thresholds to be notified of potential issues.
- CloudWatch Alarms: CloudWatch Alarms can be configured to trigger notifications or automated actions when specific metrics exceed predefined thresholds. For example, an alarm can be set to trigger an email notification if the error rate of a Lambda function exceeds a certain percentage. Alarms can also be used to trigger automated scaling actions or other corrective measures.
- CloudWatch Dashboards: Create CloudWatch Dashboards to visualize function performance and other relevant metrics. Dashboards provide a centralized view of the application’s health, allowing for quick identification of trends and anomalies. Customize dashboards to display the most important metrics and logs for a specific function or application.
- Tracing with AWS X-Ray: Integrate AWS X-Ray to trace requests as they flow through the application. X-Ray provides insights into the performance of each component of the application, including Lambda functions, API Gateway, and other AWS services. Use X-Ray to identify performance bottlenecks and optimize the overall application performance.
Error Types and Handling Strategies
The following table summarizes common error types encountered in Lambda functions triggered by S3 events and suggests appropriate handling strategies.
| Error Type | Description | Common Causes | Handling Strategy |
|---|---|---|---|
| Input Validation Errors | Errors that occur when the input data is invalid or malformed. | Incorrect file format, missing data, unexpected data types. |
|
| Resource Access Errors (Permissions) | Errors that occur when the Lambda function lacks the necessary permissions to access required resources. | Insufficient IAM permissions, incorrect resource ARNs. |
|
| Service Integration Errors | Errors that occur when interacting with other AWS services (e.g., S3, DynamoDB, etc.). | Service unavailability, throttling, network issues. |
|
| Code Errors | Errors that originate from the function code itself. | Bugs in the code, incorrect logic, unhandled exceptions. |
|
Advanced Configurations
To optimize the performance, reliability, and manageability of your S3-triggered Lambda functions, several advanced configuration options are available. These configurations enable fine-grained control over function invocation, object processing, and deployment strategies. This section delves into these advanced configurations, offering insights into synchronous and asynchronous invocation, parallel object processing, and versioning/aliasing strategies.
Synchronous and Asynchronous Invocation Models
Lambda functions triggered by S3 events can be invoked in two primary modes: synchronous and asynchronous. Understanding the differences between these models is crucial for optimizing performance and managing error handling.The key differences can be summarized as follows:
- Synchronous Invocation: In this model, the Lambda function is invoked directly by the S3 service. S3 waits for the function to complete execution and returns the result (success or failure) to the client. This model is suitable for tasks where the outcome of the function execution is immediately required. However, it can introduce latency if the function takes a long time to execute, and S3 might timeout if the function runs longer than the configured timeout.
- Asynchronous Invocation: In this model, S3 adds the invocation request to a queue. The Lambda service then retrieves the request from the queue and invokes the function. S3 does not wait for the function to complete. This approach is ideal for tasks where immediate results are not critical, such as background processing or data transformations. It offers better scalability and fault tolerance, as failures are handled through retries and dead-letter queues.
The invocation model is implicitly determined by the service triggering the Lambda function. S3, by default, uses asynchronous invocation. This means that S3 sends the event to Lambda, and Lambda handles the execution asynchronously.Consider this example to illustrate the difference. Imagine processing a large number of image files uploaded to an S3 bucket.
- Synchronous Approach (Not Directly Applicable): If S3 used synchronous invocation, it would wait for each image to be processed before acknowledging the upload. This could lead to delays and potentially timeout errors, especially for large files or a high volume of uploads.
- Asynchronous Approach: With asynchronous invocation, S3 immediately acknowledges the upload. Lambda then processes the images in the background. If a processing error occurs, Lambda’s built-in retry mechanism attempts to reprocess the image. Failed events can be sent to a dead-letter queue for further analysis.
The asynchronous model offers advantages in terms of scalability and resilience.
Designing a Solution for Parallel Object Processing
Processing objects in parallel can significantly reduce the overall processing time, especially when dealing with a large number of files or objects. This involves strategies to invoke multiple Lambda functions concurrently.Here’s how to design a parallel processing solution:
- Event-Driven Architecture: The foundation is an event-driven architecture. S3 events trigger Lambda functions. Each event corresponds to an object upload or modification.
- Fan-Out Pattern: Implement a fan-out pattern to process objects in parallel. This involves the following steps:
- Trigger: An S3 event triggers a single “orchestrator” Lambda function.
- Event Transformation: The orchestrator function receives the S3 event and transforms it into multiple smaller events, each representing a portion of the work. For example, if processing a large log file, the orchestrator might split the file into smaller chunks.
- Invocation: The orchestrator function invokes multiple “worker” Lambda functions, each processing a specific chunk or object. This can be done asynchronously.
- Aggregation (Optional): If necessary, a final function can aggregate the results from the worker functions. This function could be triggered by a mechanism like a CloudWatch Events rule that monitors for completion signals from the workers or by polling the worker functions.
- Considerations:
- Concurrency Limits: Be mindful of the Lambda function’s concurrency limits. Configure the concurrency settings to prevent overloading the system.
- Error Handling: Implement robust error handling and retry mechanisms. Use dead-letter queues to capture failed events.
- Object Locking (if needed): If the processing involves modifying the original objects, implement object locking mechanisms to prevent race conditions. This might involve using a database or a distributed lock manager.
For example, consider the processing of video files uploaded to S3.
- Orchestrator Function: Triggered by the S3 event for a new video upload.
- Event Transformation: The orchestrator function determines the number of worker functions needed based on the video’s size and complexity. It might extract metadata like the video’s resolution and codec.
- Worker Functions: Multiple worker functions are invoked asynchronously. Each worker function might perform a specific task, such as:
- Transcoding the video into different formats and resolutions.
- Generating thumbnails.
- Extracting audio.
- Adding watermarks.
- Aggregation (Optional): A final function could be responsible for aggregating the results from the worker functions, such as compiling a manifest file listing all the generated outputs, and updating the original object’s metadata.
This parallel approach significantly reduces the time required to process each video, improving the overall user experience.
Using Lambda Function Versions and Aliases for Deployment and Testing
Lambda function versions and aliases provide a robust mechanism for managing deployments, testing, and rolling back changes.
- Function Versions:
- Each time you publish a new version of your Lambda function, you create a numbered version (e.g., $LATEST, v1, v2).
- Versions are immutable. Once created, they cannot be changed.
- Versions are useful for preserving specific code snapshots.
- Function Aliases:
- Aliases are pointers to specific function versions.
- Aliases provide a stable reference to a function, even when the underlying version changes.
- Common aliases include “production,” “staging,” and “development.”
- You can configure the S3 trigger to invoke a specific alias, such as the “production” alias.
- Deployment Strategy:
- Development/Testing: Deploy new code to a development alias (e.g., “development”). Test the function thoroughly in this environment.
- Staging: Once testing is complete, promote the code to a staging alias (e.g., “staging”). This can be used for user acceptance testing (UAT).
- Production: After successful testing in staging, promote the code to the production alias. This can be done by updating the alias to point to the new version.
- Traffic Shifting (Canary Deployments): For more advanced deployments, you can gradually shift traffic from one version to another using weighted aliases. This allows you to test the new version with a small percentage of production traffic before fully rolling it out.
- Rollback Strategy:
- If a new version introduces issues, you can quickly roll back by updating the alias to point to the previous version.
- This is much faster than deploying a new version and updating the trigger.
Consider an example of a data processing Lambda function.
- v1: The initial production version.
- development alias: Points to v2, which includes new features and bug fixes.
- staging alias: Points to v2, used for testing and validation.
- production alias: Points to v1.
During the deployment, the following steps would be taken:
- Development: Developers update the code and publish v2. The development alias is updated to point to v2.
- Testing: Testers validate v2 by triggering the function through the development and staging aliases.
- Staging: If testing is successful, the staging alias is updated to point to v2.
- Production: The production alias is updated to point to v2.
If v2 introduces problems, you can quickly revert the production alias to v1. This allows for faster, safer deployments and enables continuous integration and continuous delivery (CI/CD) pipelines.
Code Examples

This section provides practical examples to solidify understanding of triggering a Lambda function from an S3 event. It includes a Python code example for image processing, a workflow diagram illustrating the process, and steps for achieving a similar solution using Node.js. These examples demonstrate the practical application of the concepts discussed previously, enabling a hands-on understanding of the serverless architecture.
Python Lambda Function for Image Processing
This example showcases a Python Lambda function that resizes an image uploaded to an S3 bucket. It utilizes the `Pillow` library for image manipulation. The function retrieves the image from S3, resizes it, and saves the resized image back to S3.“`pythonimport boto3from PIL import Imageimport ioimport oss3_client = boto3.client(‘s3’)def lambda_handler(event, context): “”” Resizes an image uploaded to S3.
Args: event: Event data from S
3. context
Lambda context. Returns: None “”” try: bucket = event[‘Records’][0][‘s3’][‘bucket’][‘name’] key = event[‘Records’][0][‘s3’][‘object’][‘key’] # Download the image from S3 response = s3_client.get_object(Bucket=bucket, Key=key) image_data = response[‘Body’].read() img = Image.open(io.BytesIO(image_data)) # Resize the image width, height = img.size max_size = 500 if width > max_size or height > max_size: img.thumbnail((max_size, max_size)) # Save the resized image to a new buffer buffer = io.BytesIO() img.save(buffer, format=img.format) buffer.seek(0) # Upload the resized image to S3 resized_key = ‘resized_’ + key s3_client.put_object(Bucket=bucket, Key=resized_key, Body=buffer, ContentType=response[‘ContentType’]) print(f”Resized image saved to s3://bucket/resized_key”) return ‘statusCode’: 200, ‘body’: f”Image resized successfully.
Resized image saved to s3://bucket/resized_key” except Exception as e: print(f”Error processing image: e”) return ‘statusCode’: 500, ‘body’: f”Error processing image: str(e)” “`This Python code is structured to handle image resizing.
The code includes the necessary import statements for `boto3`, `PIL` (Pillow), `io`, and `os`. The `lambda_handler` function is the entry point for the Lambda function. It retrieves the bucket name and object key from the S3 event. The code then downloads the image from S3, resizes it using the `thumbnail` method of the `PIL` library, saves the resized image to a new buffer, and uploads the resized image back to S3 with a modified key.
Error handling is included to catch potential exceptions during the process. The function returns a success or error response with the corresponding status code.
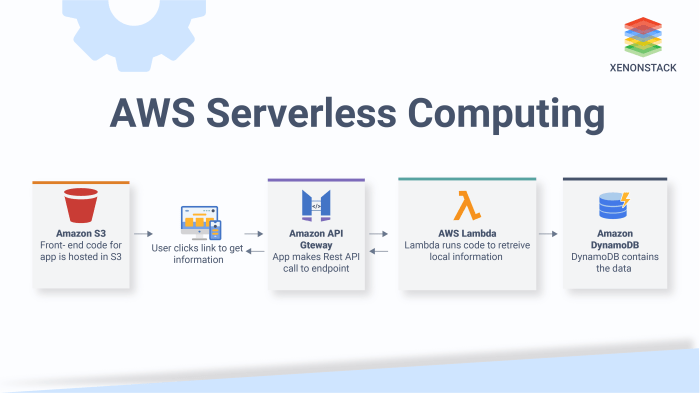
Workflow Diagram: S3 Upload to Lambda Processing
The following diagram illustrates the complete workflow, from an S3 upload event to the Lambda function processing the event. The diagram depicts the interaction between the S3 bucket, the Lambda function, and the processed output within S3.* S3 Bucket: The source of the image file. An image file is uploaded to this bucket.
S3 Event Notification
Upon a new object creation (e.g., upload) event in the S3 bucket, a notification is sent to the Lambda function. This is configured through S3 event notifications.
Lambda Function
The Python code that is triggered by the S3 event.
Input
The Lambda function receives the event data, including the bucket name and object key.
Processing
The Lambda function downloads the image, resizes it, and saves the resized image.
Output
The Lambda function uploads the processed (resized) image back to the same S3 bucket, typically with a different key.
Processed Image in S3
The resized image is stored in the same S3 bucket, identified by a new key (e.g., `resized_original_image.jpg`).The diagram visually represents the event-driven architecture, demonstrating how the S3 event triggers the Lambda function, which then processes the image and stores the result in the same S3 bucket.
Node.js Solution Implementation
Implementing a similar solution using Node.js involves a comparable set of steps. The key components include the use of the AWS SDK for JavaScript and an image processing library like `sharp`.The process of building a similar solution in Node.js involves these steps:
1. Create a Node.js Lambda Function
Create a new Lambda function using the Node.js runtime. This function will be triggered by S3 events.
2. Install Dependencies
Install the necessary dependencies within your Lambda function’s directory.
`aws-sdk`
For interacting with AWS services (S3 in this case).
`sharp`
A high-performance image processing library. “`bash npm install aws-sdk sharp “`
3. Write the Node.js Code
“`javascript const AWS = require(‘aws-sdk’); const sharp = require(‘sharp’); const s3 = new AWS.S3(); exports.handler = async (event) => try const bucket = event.Records[0].s3.bucket.name; const key = event.Records[0].s3.object.key; // Download the image from S3 const params = Bucket: bucket, Key: key, ; const data = await s3.getObject(params).promise(); const imageBuffer = data.Body; // Resize the image using sharp const resizedImageBuffer = await sharp(imageBuffer) .resize(500, 500, fit: ‘inside’, // Or ‘cover’, ‘contain’ ) .toBuffer(); // Upload the resized image to S3 const resizedKey = ‘resized_’ + key; const uploadParams = Bucket: bucket, Key: resizedKey, Body: resizedImageBuffer, ContentType: data.ContentType, ; await s3.putObject(uploadParams).promise(); console.log(`Resized image saved to s3://$bucket/$resizedKey`); return statusCode: 200, body: JSON.stringify(‘Image resized successfully!’), ; catch (error) console.error(‘Error processing image:’, error); return statusCode: 500, body: JSON.stringify(‘Error processing image: ‘ + error.message), ; ; “` This code uses the `aws-sdk` to interact with S3 and `sharp` to resize the image.
It downloads the image, resizes it, and uploads the resized image back to S
3. 4. Configure S3 Event Notification
Configure an S3 event notification to trigger the Lambda function when a new object is created in your S3 bucket. This is similar to the Python example’s setup.
5. Test the Solution
Upload an image to the S3 bucket and verify that the Lambda function is triggered and that the resized image is created in the same bucket.
Wrap-Up
In conclusion, triggering Lambda functions from S3 events offers a powerful approach to building scalable, event-driven cloud applications. By understanding the nuances of event types, configuration, IAM permissions, and data structures, developers can create highly responsive and efficient systems. The techniques discussed, from basic setups to advanced configurations, empower developers to harness the full potential of serverless computing. This detailed exploration provides a solid foundation for building robust and scalable applications that react dynamically to data changes within Amazon S3.
Commonly Asked Questions
What is the maximum execution time for a Lambda function triggered by an S3 event?
The maximum execution time for a Lambda function is configurable, with a default limit and a maximum limit. Currently, the maximum is 15 minutes.
How can I handle errors when my Lambda function fails to process an S3 event?
Error handling involves several strategies. Implement try-except blocks within the Lambda function code to catch exceptions. Utilize CloudWatch logging to record error details and monitor function executions. Implement dead-letter queues (DLQs) to store failed event data for later processing or investigation.
Can I trigger multiple Lambda functions from a single S3 event?
Yes, while S3 event notifications trigger a single Lambda function directly, you can orchestrate multiple functions using other services. For example, a single Lambda function can trigger other functions or publish messages to an SNS topic, which then triggers other functions.
What is the cost associated with triggering a Lambda function from an S3 event?
The cost is based on the number of Lambda function invocations, the duration of each invocation, and the memory allocated to the function. S3 event notifications themselves are typically free, but you pay for the Lambda function execution.