The ability to automate tasks is crucial in modern cloud environments, and scheduling Lambda functions to run periodically is a fundamental building block for this automation. This guide delves into the core concepts, exploring the “how to schedule lambda functions to run periodically” to optimize resources and streamline operations. From simple scheduled tasks to complex, orchestrated workflows, we will examine the various AWS services that facilitate this capability, offering insights into their strengths, weaknesses, and practical applications.
We will navigate the landscape of AWS services, comparing and contrasting options like CloudWatch Events (now EventBridge) and Step Functions. This journey includes configuring schedules, managing permissions, and implementing robust monitoring and error handling strategies. The goal is to empower readers with the knowledge to design, implement, and maintain efficient, automated solutions using periodic Lambda function execution.
Introduction to Periodic Lambda Function Execution
Scheduling Lambda functions to execute periodically is a fundamental concept in serverless computing, enabling automated task execution without the need for dedicated servers. This approach leverages the event-driven nature of Lambda, triggering functions based on defined schedules. It streamlines operations, improves resource utilization, and reduces operational overhead.Periodic Lambda execution is achieved through the integration of AWS Lambda with services like Amazon CloudWatch Events (now Amazon EventBridge) or AWS Step Functions.
These services act as schedulers, initiating Lambda function invocations at specified intervals or times. This allows developers to automate a wide range of tasks, from data processing and reporting to system maintenance and application integration.
Core Concept of Scheduling Lambda Functions
The core concept involves the creation of a schedule, which is then linked to a specific Lambda function. This schedule defines the frequency and timing of function invocations. The scheduler, typically EventBridge, monitors the defined schedule and, when the scheduled time arrives, triggers the Lambda function. The Lambda function then executes its predefined code, performing the intended task. The entire process is managed by AWS, eliminating the need for users to manage the underlying infrastructure.
Scenarios Where Periodic Lambda Execution is Beneficial
Periodic Lambda execution offers significant advantages across various application domains. These benefits are especially pronounced in scenarios demanding automation and efficient resource management.
- Data Processing and Transformation: Lambda functions can be scheduled to process and transform data on a regular basis. For instance, a Lambda function could be triggered daily to aggregate and summarize data from a database, generating reports or updating dashboards.
- System Maintenance and Monitoring: Automated system maintenance tasks, such as log rotation, database backups, and system health checks, can be scheduled to run periodically. This proactive approach ensures system stability and reduces the risk of manual intervention.
- Application Integration: Periodic execution facilitates the integration of applications and services. For example, a Lambda function could be scheduled to synchronize data between different databases or cloud services at predefined intervals.
- Resource Optimization: Regularly scheduled tasks can optimize resource utilization. For example, a Lambda function can be used to automatically scale compute resources based on demand, ensuring optimal performance while minimizing costs.
Common Use Cases for Automated Tasks with Periodic Triggers
Automated tasks that benefit from periodic triggers span various business and technical requirements. These use cases showcase the versatility and applicability of scheduled Lambda functions.
- Data Backup and Archiving: Regularly backing up databases, files, and other data is crucial for data integrity and disaster recovery. A Lambda function can be scheduled to automatically create backups at specified intervals, storing them securely in services like Amazon S3.
- Report Generation and Delivery: Automating the generation and delivery of reports saves time and ensures timely information delivery. Lambda functions can be triggered to generate reports from data sources, and then send these reports via email or other channels. For example, a daily sales report could be automatically generated and emailed to the sales team.
- Batch Processing of Data: Large datasets often require batch processing for tasks such as data cleaning, transformation, and analysis. Lambda functions can be scheduled to process data in batches, improving efficiency and scalability. For instance, processing log files for security analysis can be automated.
- Website Maintenance Tasks: Website maintenance tasks, such as sitemap generation, cache clearing, and content updates, can be automated. A Lambda function can be scheduled to perform these tasks periodically, ensuring website performance and content freshness.
AWS Services for Scheduling Lambda Functions
The ability to schedule Lambda functions is crucial for automating tasks, managing resources, and responding to events in a timely manner. AWS offers several services that facilitate the periodic execution of Lambda functions, each with its own strengths and weaknesses. Understanding these services and their capabilities allows developers to choose the most appropriate solution for their specific needs, optimizing both performance and cost.
AWS Services for Scheduling Lambda Functions: Overview
AWS provides several services that can be leveraged to schedule Lambda function invocations. Each service offers a different approach to scheduling, catering to various use cases and requirements. These services include CloudWatch Events (now EventBridge), EventBridge (specifically, its Scheduler), and AWS Step Functions. The choice of service depends on factors such as the complexity of the scheduling requirements, the need for event-driven architectures, and the desired level of control and flexibility.
CloudWatch Events (EventBridge)
CloudWatch Events, now largely superseded by EventBridge, was an early offering for scheduling Lambda functions based on a cron-like expression. EventBridge has evolved to offer enhanced features and greater flexibility.
- Features: CloudWatch Events (and EventBridge) uses rules that define when and how to trigger a Lambda function. Rules are based on a schedule expression (using cron or rate expressions) or on events occurring in the AWS ecosystem. These events can include changes in resources, service-specific events, or custom events. The service provides a wide range of target types, including Lambda functions, SQS queues, SNS topics, and more.
- Scheduling Capabilities: Scheduling is primarily achieved through cron or rate expressions. Cron expressions offer precise control over the execution time, while rate expressions allow for scheduling at regular intervals (e.g., every 5 minutes, every hour).
- Use Cases: CloudWatch Events (EventBridge) is suitable for scheduling tasks such as log analysis, data processing, report generation, and automating infrastructure tasks.
EventBridge Scheduler
EventBridge Scheduler is a dedicated scheduling service within EventBridge, providing more advanced scheduling capabilities than the original CloudWatch Events.
- Features: EventBridge Scheduler provides a more robust scheduling engine, allowing for complex schedules, including recurring schedules with flexible recurrence patterns. It supports different time zones and offers features like dead-letter queues for handling failed invocations.
- Scheduling Capabilities: The scheduler supports various schedule types, including cron and rate expressions, as well as flexible schedules that allow for more complex recurring patterns, such as schedules based on specific days of the week or month. It offers features for handling time zones and can be configured to retry failed invocations.
- Use Cases: EventBridge Scheduler is well-suited for scheduling tasks that require more precise control over execution times, such as financial reporting, data synchronization, and periodic backups.
AWS Step Functions
AWS Step Functions enables the orchestration of multiple AWS services, including Lambda functions, into workflows. While not a dedicated scheduler, Step Functions can be used to create sophisticated scheduled tasks.
- Features: Step Functions defines workflows as state machines. These state machines can include various states, such as Lambda function invocations, decision states, and wait states. Step Functions provides features for handling errors, retries, and parallel execution.
- Scheduling Capabilities: Step Functions can be scheduled using CloudWatch Events (EventBridge). A CloudWatch Events rule triggers a Step Functions state machine, which then executes the workflow.
- Use Cases: Step Functions is ideal for orchestrating complex workflows that involve multiple Lambda functions and other AWS services. Examples include data pipelines, ETL processes, and automated deployments.
Comparison of AWS Services for Scheduling Lambda Functions
The following table summarizes the advantages and disadvantages of each scheduling service:
| Service | Pros | Cons |
|---|---|---|
| CloudWatch Events (EventBridge) |
|
|
| EventBridge Scheduler |
|
|
| AWS Step Functions |
|
|
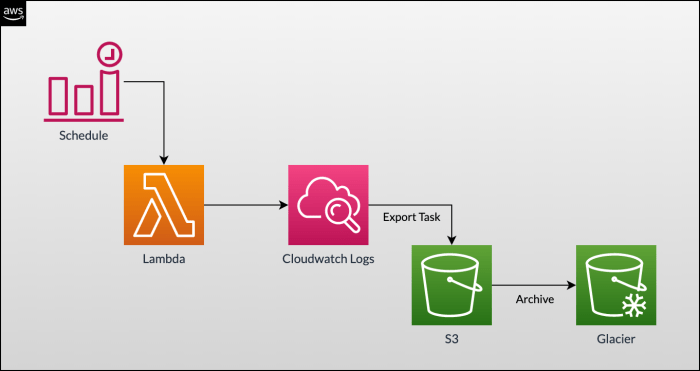
Scheduling with CloudWatch Events (EventBridge)
CloudWatch Events (now known as EventBridge) offers a powerful and flexible mechanism for scheduling Lambda function executions. This service allows you to define rules that trigger Lambda functions based on time-based schedules, event patterns, or specific service events within your AWS environment. EventBridge provides a highly scalable and reliable solution for automating tasks and processes.
Configuring CloudWatch Events (EventBridge) to Trigger a Lambda Function
Configuring EventBridge to trigger a Lambda function involves several key steps. The process involves defining a rule, specifying the event source, and setting the target to be the Lambda function. This configuration enables EventBridge to monitor for specific events or adhere to scheduled times and then invoke the target Lambda function.The following Artikels the key steps involved in configuring EventBridge to trigger a Lambda function:
- Access the AWS Management Console: Navigate to the EventBridge service in the AWS Management Console.
- Create a Rule: Click on “Rules” in the left-hand navigation pane and then click “Create rule.”
- Define the Rule:
- Name and Description: Provide a descriptive name and description for the rule.
- Define the Event Source: Choose the event source. This can be a schedule, event pattern, or AWS service event. For time-based scheduling, select “Schedule.”
- Configure the Schedule: If choosing “Schedule,” specify the schedule type (e.g., cron expression or rate).
- Select Targets: Add a target to the rule, selecting “Lambda function” from the list of available targets.
- Select the Lambda Function: Choose the specific Lambda function that you want to invoke.
- Configure Input (Optional): Configure the input for the Lambda function. You can choose to pass a fixed JSON payload, or use the event data if the rule is triggered by an event pattern.
- Configure Settings (Optional): Configure any additional settings, such as retry attempts or dead-letter queues, as needed.
- Review and Create: Review the configuration and click “Create” to create the rule.
Demonstrating the Process of Creating a Scheduled Rule within CloudWatch Events
Creating a scheduled rule in EventBridge requires defining the schedule and associating it with a target Lambda function. The process involves specifying the frequency of execution using either a rate expression (e.g., every 5 minutes) or a cron expression, which offers more flexibility. The following illustrates a step-by-step guide for creating a scheduled rule:
- Access the EventBridge Service: Log in to the AWS Management Console and navigate to the EventBridge service.
- Navigate to Rules: In the left-hand navigation pane, click on “Rules.”
- Create a New Rule: Click the “Create rule” button.
- Provide Rule Details:
- Name and Description: Enter a name (e.g., “MyScheduledLambdaRule”) and a description for the rule.
- Define Event Source: Select “Schedule” as the event source.
- Configure the Schedule:
- Schedule Type: Choose either “Rate” or “Cron expression.”
- Rate Example: To run every 5 minutes, select “Rate” and enter “5” in the “Minutes” field and choose “Minutes” as the interval.
- Cron Expression Example: To run at 10:00 AM UTC every day, select “Cron expression” and enter the cron expression:
0 10.
-
- ?
-
- Select Targets: In the “Targets” section, click “Add target.”
- Choose Lambda Function: Select “Lambda function” from the target list.
- Select Lambda Function: Choose the specific Lambda function you want to trigger from the dropdown.
- Configure Input (Optional): You can optionally configure the input to the Lambda function. For example, you can pass a fixed JSON payload.
- Configure Additional Settings: Configure any additional settings as needed (e.g., retry attempts, dead-letter queue).
- Create the Rule: Click “Create” to create the rule.
Providing Examples of Different Cron Expressions for Various Scheduling Frequencies
Cron expressions provide a highly flexible way to schedule Lambda functions. They allow precise control over the execution time, including specifying the minute, hour, day of the month, month, and day of the week. Understanding how to use cron expressions is essential for effectively scheduling Lambda functions for various use cases.Here are several examples of cron expressions and their corresponding scheduling frequencies:
- Every Minute:
- Cron Expression:
*
-
-
- ?
-
This expression triggers the Lambda function every minute of every hour, every day.
- Cron Expression:
- Every Hour:
- Cron Expression:
0
-
-
- ?
-
This expression runs the Lambda function at the beginning of every hour (e.g., 00:00, 01:00, 02:00, etc.).
- Cron Expression:
- Daily at Midnight (UTC):
- Cron Expression:
0 0
-
- ?
-
This expression schedules the Lambda function to run at midnight (00:00) UTC every day.
- Cron Expression:
- Daily at 8:00 AM (UTC):
- Cron Expression:
0 8
-
- ?
-
This expression triggers the Lambda function at 8:00 AM UTC every day.
- Cron Expression:
- Weekly on Monday at 9:00 AM (UTC):
- Cron Expression:
0 9 ?
- 1
-
This expression schedules the Lambda function to run every Monday at 9:00 AM UTC.
- Cron Expression:
- Monthly on the 1st day at 10:00 AM (UTC):
- Cron Expression:
0 10 1
- ?
-
This expression runs the Lambda function on the 1st day of every month at 10:00 AM UTC.
- Cron Expression:
- Every 15 minutes:
- Cron Expression:
0/15
-
-
- ?
-
This expression triggers the Lambda function every 15 minutes of every hour.
- Cron Expression:
- On the last day of the month at 11:00 PM (UTC):
- Cron Expression:
0 23 L
- ?
-
This expression schedules the Lambda function to run on the last day of every month at 11:00 PM UTC.
- Cron Expression:
Scheduling with EventBridge – Advanced Techniques
EventBridge offers sophisticated capabilities beyond basic scheduling, enabling complex event-driven architectures. These advanced techniques allow for precise control over event processing and the orchestration of intricate workflows, significantly enhancing the flexibility and power of periodic Lambda function execution. By leveraging filtering and input transformation, EventBridge empowers developers to create highly tailored and efficient solutions.
Filtering Events to Trigger Specific Lambda Functions
Event filtering allows for selective triggering of Lambda functions based on the content of the events. This capability is crucial for building modular and scalable applications, ensuring that only relevant events initiate function execution. Instead of a single Lambda function handling all scheduled events, filtering enables the routing of specific event types to dedicated functions, improving code organization and reducing unnecessary processing.To effectively utilize event filtering, the following points are critical:
- Event Pattern Definition: EventBridge uses event patterns, which are JSON objects, to define the criteria for matching events. These patterns specify the properties of the event that must match for the rule to trigger the associated Lambda function.
- Filtering based on Event Source: Filtering can be based on the source of the event. For example, you can trigger a Lambda function only when events originate from a specific AWS service, such as Amazon S3 or AWS CloudTrail. This is accomplished by specifying the `source` field in the event pattern.
- Filtering based on Event Detail: The `detail` field within the event pattern allows for filtering based on the specific content of the event. This enables fine-grained control over which events trigger the Lambda function. For instance, you can filter events based on the status of a resource, the type of operation performed, or any other relevant data contained within the event’s detail section.
- Use of Wildcards: Event patterns support wildcard characters (`*` and `?`) for flexible matching. The asterisk (`*`) matches any sequence of characters, while the question mark (`?`) matches a single character. This allows for creating patterns that match a range of event values.
- Example Scenario: Consider an application monitoring system. A Lambda function could be triggered by an EventBridge rule with an event pattern that filters for events originating from Amazon CloudWatch. The event pattern could be configured to only trigger the Lambda function when a specific metric exceeds a predefined threshold, ensuring that only critical alerts initiate the function’s execution. The `detail` section of the event pattern would contain the criteria for the metric, such as `”metricName”: “CPUUtilization”, “value”: “greaterThanOrEqualTo”: 90 `.
Detailing the Use of Input Transformers to Modify Event Data Before It Reaches the Lambda Function
Input transformers provide a mechanism to modify the event data before it is passed to the Lambda function. This transformation capability is essential for adapting event data to the specific requirements of the Lambda function, streamlining data processing, and reducing the need for complex parsing within the function code. EventBridge allows for the creation of custom payloads, ensuring that the Lambda function receives only the necessary data in a format that is easy to process.Input transformers work through the following:
- Transformation of Event Data: Input transformers use a set of key-value pairs to map and modify event data. The key represents the output field in the payload, and the value specifies how to extract and transform the data from the incoming event.
- JSONPath Expressions: JSONPath expressions are used to extract data from the event payload. These expressions allow for navigating the JSON structure and selecting specific elements or values. For example, `$$.detail.instanceId` extracts the `instanceId` value from the `detail` section of the event.
- Template Strings: Input transformers support template strings, which allow for combining static text with extracted event data. This enables the creation of custom payloads that include both constant values and dynamic data from the event.
- Predefined Transformers: EventBridge offers a set of predefined transformers for common use cases, such as extracting the event time, the event source, or the event ID.
- Example Scenario: Consider a system that receives events from an Amazon S3 bucket. The Lambda function needs to process only the file name from each event. An input transformer can be configured to extract the file name using a JSONPath expression (`$$.detail.object.key`) and create a payload containing only the file name. This eliminates the need for the Lambda function to parse the entire event object, simplifying the function’s logic and improving its performance.
Designing a Solution Using EventBridge for Complex Scheduling Scenarios, Including Multiple Triggers and Dependencies
EventBridge facilitates the orchestration of complex scheduling scenarios involving multiple triggers and dependencies. This capability allows for creating sophisticated workflows that automate tasks based on various schedules, event patterns, and conditional logic. The ability to chain events and manage dependencies is crucial for building robust and scalable applications that require precise control over task execution.Designing a solution for complex scheduling involves the following:
- Multiple EventBridge Rules: Utilize multiple EventBridge rules to define different schedules and event patterns. Each rule can trigger a different Lambda function or the same function with different input data.
- Chaining Events: One Lambda function can trigger another Lambda function by publishing a custom event to EventBridge. This allows for chaining events and creating a sequence of tasks. The first Lambda function can, for instance, process an event, transform its data, and then publish a new event that triggers a second Lambda function.
- Conditional Logic: Implement conditional logic within the Lambda functions to determine the next steps in the workflow. This can involve checking the status of a resource, evaluating data, or making decisions based on the results of previous tasks.
- Dependency Management: Establish dependencies between tasks by using EventBridge to trigger tasks in a specific order. Ensure that tasks are executed in the correct sequence by controlling the timing and event patterns.
- Example Scenario: Consider a system that processes financial transactions. The system requires multiple steps: data validation, fraud detection, and fund transfer. A complex schedule could be implemented using EventBridge as follows:
- Rule 1: Trigger a Lambda function every hour to validate transaction data.
- Rule 2: After data validation, the first Lambda function publishes a custom event to EventBridge containing the validated transaction data.
- Rule 3: This custom event triggers a second Lambda function, which performs fraud detection using the validated data.
- Rule 4: If the fraud detection is successful, the second Lambda function publishes another custom event with the validated data and fraud detection results.
- Rule 5: This final event triggers a third Lambda function, which executes the fund transfer.
This design allows for independent execution of each step while maintaining the necessary dependencies.
Scheduling with Step Functions
")
Step Functions provide a robust and flexible mechanism for orchestrating periodic Lambda function executions. They allow for the creation of state machines that define complex workflows, incorporating error handling, retries, and parallel execution, all of which are crucial for reliable and resilient applications. Unlike CloudWatch Events, which primarily trigger Lambda functions, Step Functions offer a more comprehensive solution, enabling the coordination of multiple AWS services and the management of intricate execution logic.
This approach enhances the control and monitoring capabilities for scheduled tasks.
Orchestrating Periodic Lambda Function Executions with Step Functions
Step Functions orchestrate periodic Lambda function executions by leveraging a combination of their workflow capabilities and integration with scheduling services like CloudWatch Events. A state machine is designed to invoke a Lambda function, and this invocation is triggered by a schedule defined in CloudWatch Events. This setup allows for the execution of complex workflows triggered by periodic events. Step Functions excel in scenarios requiring error handling, retries, and the coordination of multiple services.The integration operates as follows:
- A CloudWatch Events rule triggers the Step Function state machine.
- The state machine begins execution, initiating the workflow defined within.
- A specific state within the state machine invokes a Lambda function.
- The Lambda function performs its designated task.
- The state machine then processes the Lambda function’s output, which may influence the next state transition or the execution of other services.
- Error handling and retry mechanisms are incorporated within the state machine to manage failures and ensure the workflow’s robustness.
This method provides a structured approach to managing periodic tasks, offering enhanced control and monitoring compared to direct Lambda function scheduling.
Creating a Step Function with a Lambda Function and a Schedule
Creating a Step Function that includes a Lambda function and a schedule involves several steps, from defining the state machine to setting up the CloudWatch Events rule. This procedure provides a structured approach to implementing periodic executions.
- Define the Lambda Function: First, create the Lambda function that will perform the desired task. This function should be designed to execute the core logic of the scheduled operation.
- Design the State Machine: Create a Step Function state machine. This involves defining the states, transitions, and error handling logic. The state machine will include a state that invokes the previously created Lambda function.
- Create a CloudWatch Events Rule: Set up a CloudWatch Events rule to trigger the Step Function. This rule defines the schedule (e.g., every hour, every day) using a cron expression or rate expression.
- Configure Permissions: Ensure that the Step Function has the necessary permissions to invoke the Lambda function and that the CloudWatch Events rule has permissions to trigger the Step Function. This involves creating IAM roles and policies.
- Test the Implementation: Thoroughly test the setup by manually triggering the CloudWatch Events rule or by waiting for the scheduled execution to occur. Monitor the execution logs and ensure the Lambda function is executing as expected.
The use of AWS Management Console, AWS CLI, or Infrastructure as Code (IaC) tools such as AWS CloudFormation or Terraform can automate this process.
Handling Retries and Error Handling within a Step Function Scheduled Workflow
Error handling and retries are critical for ensuring the reliability of scheduled workflows. Step Functions provide built-in mechanisms for managing errors and retrying failed tasks. This section explores how to configure retries and error handling within a Step Function scheduled workflow.
- Retry Configuration: Configure retry behavior within the state machine definition. This includes specifying the number of retries, the interval between retries, and the error codes or exceptions to trigger retries.
- Error Handling States: Implement error handling states to manage failures gracefully. These states can perform actions such as logging errors, sending notifications, or executing alternative workflows.
- Catching Specific Errors: Define specific error codes or exception types to catch and handle differently. This allows for targeted error management, such as retrying certain errors while triggering alerts for others.
- Dead-Letter Queues (DLQs): Configure DLQs to capture failed executions that cannot be retried. This allows for investigation and analysis of persistent failures.
- Monitoring and Logging: Implement comprehensive monitoring and logging to track execution status, errors, and retry attempts. This includes using CloudWatch Logs and CloudWatch Metrics.
Example: Consider a Step Function that calls a Lambda function to process data every hour. The state machine is designed to retry the Lambda function three times if it encounters a `Timeout` or `ServiceException`. If the Lambda function fails after the retries, an error handling state sends a notification via SNS. This ensures that transient failures are automatically handled while persistent errors are flagged for manual intervention.
The following code provides an example in JSON format:“`json “StartAt”: “InvokeLambda”, “States”: “InvokeLambda”: “Type”: “Task”, “Resource”: “arn:aws:lambda:REGION:ACCOUNT_ID:function:YOUR_LAMBDA_FUNCTION”, “Retry”: [ “ErrorEquals”: [ “Lambda.Timeout”, “Lambda.ServiceException” ], “IntervalSeconds”: 3, “MaxAttempts”: 3, “BackoffRate”: 2 ], “Catch”: [ “ErrorEquals”: [ “States.TaskFailed” ], “Next”: “HandleFailure” ], “Next”: “SuccessState” , “HandleFailure”: “Type”: “Task”, “Resource”: “arn:aws:lambda:REGION:ACCOUNT_ID:function:HandleFailureFunction”, “Next”: “SuccessState” , “SuccessState”: “Type”: “Succeed” “`In this example:
- The `Retry` section defines the retry behavior for `Lambda.Timeout` and `Lambda.ServiceException` errors, specifying the number of retries, interval, and backoff rate.
- The `Catch` section defines how to handle `States.TaskFailed` errors, transitioning to a `HandleFailure` state.
- The `HandleFailure` state, in turn, would invoke a Lambda function (HandleFailureFunction) to perform error handling tasks.
This structure ensures that the workflow is robust and can gracefully handle transient failures while providing a mechanism for addressing persistent errors.
IAM Permissions and Security Considerations

Implementing periodic Lambda function execution necessitates meticulous attention to security. Granting appropriate permissions and adhering to security best practices are crucial to prevent unauthorized access, accidental executions, and data breaches. Neglecting these aspects can expose sensitive resources and lead to significant operational and financial consequences.
Necessary IAM Permissions for Lambda Functions and Scheduling Services
Effective scheduling and execution of Lambda functions require specific IAM permissions for both the Lambda function itself and the scheduling service employed (CloudWatch Events/EventBridge or Step Functions). These permissions define the actions each service or function is authorized to perform.
- Lambda Function Permissions: The Lambda function itself needs permissions to perform its intended tasks. This includes permissions to access any AWS resources it interacts with, such as:
- Read/Write access to S3 buckets: If the function reads from or writes to an S3 bucket.
- Access to DynamoDB tables: If the function interacts with a DynamoDB table (e.g., read, write, update, delete).
- Permissions to invoke other AWS services: If the function triggers or interacts with other AWS services.
- Logging permissions (CloudWatch Logs): The function needs permissions to write logs to CloudWatch Logs for monitoring and debugging.
- Scheduling Service Permissions (CloudWatch Events/EventBridge): When using CloudWatch Events/EventBridge, the service needs permissions to invoke the Lambda function. This is typically achieved through a resource-based policy attached to the Lambda function, allowing CloudWatch Events/EventBridge to trigger it.
- `lambda:InvokeFunction` permission: The most critical permission for the EventBridge service. This grants EventBridge the ability to invoke the specified Lambda function.
- Scheduling Service Permissions (Step Functions): When using Step Functions, the Step Function execution role needs permissions to invoke the Lambda function.
- `lambda:InvokeFunction` permission: The Step Function execution role requires this permission to invoke the Lambda function.
- Permissions for any other AWS services used within the Step Function workflow: If the Step Function workflow interacts with other services (e.g., S3, DynamoDB), the execution role needs appropriate permissions for those services.
- IAM Role Creation and Management: Proper IAM role creation is crucial for managing these permissions. It is best practice to create specific roles with the least privilege necessary.
Best Practices for Securing Lambda Functions and Scheduling Configurations
Adhering to security best practices significantly reduces the risk of unauthorized access and accidental executions. A proactive approach to security is essential for maintaining the integrity and availability of your applications.
- Principle of Least Privilege: Grant only the necessary permissions to each Lambda function and scheduling service. Avoid overly permissive IAM policies.
- Use Resource-Based Policies: For CloudWatch Events/EventBridge, utilize resource-based policies on the Lambda function to explicitly allow the EventBridge service to invoke it. This helps restrict access to only the intended scheduler.
- Network Security: Configure Lambda functions to run within a VPC (Virtual Private Cloud) if they need to access resources within a private network. This adds an extra layer of security.
- Encryption: Encrypt sensitive data at rest and in transit. Utilize AWS Key Management Service (KMS) for managing encryption keys.
- Input Validation: Implement robust input validation within the Lambda function to prevent malicious code injection or data manipulation.
- Regular Security Audits: Conduct regular security audits of your Lambda functions and scheduling configurations to identify and address potential vulnerabilities. Utilize tools like AWS IAM Access Analyzer to assess your IAM configurations.
- Monitoring and Logging: Implement comprehensive monitoring and logging to track function invocations, errors, and other relevant metrics. This enables you to quickly detect and respond to security incidents. Utilize CloudWatch Logs, CloudWatch Metrics, and AWS X-Ray for detailed monitoring.
- Version Control: Use version control (e.g., Git) for your Lambda function code and infrastructure-as-code (IaC) configurations. This enables you to track changes, revert to previous versions, and collaborate effectively.
- Security Best Practices for Code: Implement secure coding practices, such as sanitizing user inputs, preventing SQL injection, and handling secrets securely.
Preventing Unauthorized Access and Accidental Executions
Preventing unauthorized access and accidental executions is critical to maintaining the security and reliability of scheduled Lambda functions. Implementing specific measures can significantly reduce the risk of these issues.
- Restrict IAM Role Access: Limit the users and roles that can modify the IAM roles associated with Lambda functions and scheduling services.
- Use EventBridge Filtering: When using EventBridge, utilize event patterns to filter events and trigger Lambda functions only when specific conditions are met. This prevents the function from being invoked unnecessarily. For example, you could filter events based on a specific source, detail type, or content.
- Implement Concurrency Limits: Set concurrency limits on your Lambda functions to prevent them from being overwhelmed by excessive invocations, which could be caused by accidental triggers or malicious attacks.
- Use Dead-Letter Queues (DLQs): Configure DLQs for your Lambda functions to handle failed invocations. This allows you to examine and troubleshoot errors, preventing them from going unnoticed. DLQs are particularly useful when using EventBridge, as they can catch errors that might otherwise go unreported.
- Protect Secrets: Store sensitive information, such as API keys and database credentials, securely using AWS Secrets Manager or AWS Systems Manager Parameter Store. Do not hardcode secrets directly into your Lambda function code.
- Disable Unused Triggers: Regularly review and disable any unused or unnecessary scheduling triggers to minimize the attack surface.
- Implement Two-Factor Authentication (2FA): Enforce 2FA for all users with access to the AWS console and CLI to protect against unauthorized access to your AWS resources.
- Regularly Review and Update Security Configurations: Continuously monitor and update your security configurations to adapt to evolving threats and vulnerabilities. This includes reviewing IAM policies, monitoring logs, and patching any identified security flaws.
Monitoring and Logging
Effectively monitoring and logging scheduled Lambda functions is crucial for ensuring their reliability, performance, and cost-effectiveness. Comprehensive monitoring allows for proactive identification and resolution of issues, while detailed logging provides valuable insights into function behavior and potential areas for optimization. Proper implementation of these practices is essential for maintaining a robust and scalable serverless architecture.
Monitoring Execution of Scheduled Lambda Functions
Monitoring the execution of scheduled Lambda functions involves tracking various metrics to understand their performance and identify potential problems. This includes monitoring invocation counts, duration, errors, and throttles. The goal is to gain insights into the overall health and efficiency of the scheduled tasks.The primary tool for monitoring Lambda functions is Amazon CloudWatch. CloudWatch automatically collects and provides several key metrics:* Invocations: The number of times the function was invoked.
A sudden drop in invocations could indicate a problem with the scheduler or the function itself.
Errors
The number of times the function returned an error. High error rates require immediate investigation to identify and resolve the root cause.
Throttles
The number of times the function was throttled due to exceeding concurrency limits. Throttling can impact the timely execution of scheduled tasks.
Duration
The time it takes for the function to execute. Long durations can indicate performance bottlenecks or inefficient code.
ConcurrentExecutions
The number of function instances running simultaneously. This metric helps to understand resource utilization.
IteratorAge (for Event Source Mappings)
For functions triggered by event sources like SQS or Kinesis, this metric indicates the age of the oldest record being processed, which can help identify processing delays.CloudWatch provides several features for monitoring:* Dashboards: Create custom dashboards to visualize key metrics and track function performance over time. Dashboards allow for a consolidated view of the health of your scheduled Lambda functions.
Alarms
Set up alarms to automatically trigger notifications or actions when specific thresholds are exceeded. For example, you can create an alarm to notify you if the error rate exceeds a certain percentage.
Metrics
CloudWatch provides a wide range of metrics that can be used to monitor the performance of Lambda functions. These metrics are automatically collected and can be used to create dashboards and alarms.To effectively monitor your Lambda functions, you should establish baseline performance metrics and regularly review them. Regularly reviewing these metrics is essential to ensure the proper functioning of the scheduled tasks.
Setting Up Logging and Error Tracking
Setting up robust logging and error tracking mechanisms is critical for troubleshooting issues and gaining insights into function behavior. Effective logging provides detailed information about function executions, including input parameters, execution steps, and any errors encountered. This detailed information is crucial for debugging and optimizing your Lambda functions.Lambda functions automatically integrate with CloudWatch Logs. Each function invocation generates a log stream containing the function’s output and any error messages.
However, it’s important to configure your functions to provide sufficient logging information.Key aspects of setting up logging and error tracking:* Structured Logging: Use structured logging formats, such as JSON, to make logs easier to parse and analyze. Structured logs allow you to include key-value pairs for data, making it easier to search and filter logs.
Logging Levels
Utilize different logging levels (e.g., DEBUG, INFO, WARN, ERROR) to control the verbosity of your logs. This helps to filter out unnecessary information and focus on critical events.
Error Handling
Implement proper error handling within your function code to catch exceptions and log detailed error messages. This includes capturing stack traces and relevant context information.
Contextual Information
Include contextual information in your logs, such as the function’s request ID, timestamps, and any relevant input parameters. This helps to correlate logs with specific function invocations.
Exception Tracking Services
Consider integrating with exception tracking services like AWS X-Ray or third-party tools such as Sentry or Rollbar. These services can help you automatically capture and analyze errors, providing insights into the frequency and impact of errors.For example, in Python, you can use the `logging` module to write structured logs:“`pythonimport loggingimport jsonlogger = logging.getLogger()logger.setLevel(logging.INFO)def lambda_handler(event, context): try: # Your function logic here result = process_data(event) logger.info(json.dumps( ‘message’: ‘Data processed successfully’, ‘result’: result, ‘event’: event )) return ‘statusCode’: 200, ‘body’: json.dumps(result) except Exception as e: logger.error(json.dumps( ‘message’: ‘Error processing data’, ‘error’: str(e), ‘stack_trace’: traceback.format_exc(), ‘event’: event )) return ‘statusCode’: 500, ‘body’: json.dumps(‘error’: str(e)) “`This example demonstrates how to log informative messages, include the event data, and capture error information with stack traces.
Using CloudWatch Logs to Analyze Function Invocations and Troubleshoot Issues
CloudWatch Logs is a powerful tool for analyzing function invocations and troubleshooting issues. By effectively utilizing CloudWatch Logs, you can gain valuable insights into function behavior and identify the root cause of problems. The log data is stored in log groups, with each function having its own log group. Within a log group, there are log streams, representing individual function invocations.Here’s how to use CloudWatch Logs for analysis and troubleshooting:* Log Search: Use the CloudWatch Logs search functionality to search for specific log events based on s, patterns, or time ranges.
This allows you to quickly find relevant log entries related to a specific issue.
Log Insights
CloudWatch Logs Insights allows you to run queries on your log data to extract specific information, such as the number of errors, the average duration of invocations, or the distribution of log events. This provides advanced analytical capabilities.
Filter Patterns
Create filter patterns to automatically filter log events based on specific criteria. For example, you can create a filter to identify all log events with the word “ERROR” or “timeout.”
Metric Filters
Create metric filters to extract metrics from log events and publish them to CloudWatch metrics. This allows you to create custom metrics based on your log data. For example, you could create a metric to track the number of failed login attempts.
Analyzing Error Logs
When troubleshooting errors, examine the error messages, stack traces, and any relevant context information in the logs. This will help you identify the source of the error and understand how to fix it.
Analyzing Performance Logs
Analyze the logs to identify performance bottlenecks or inefficiencies. Look for long-running invocations, excessive resource consumption, or other performance-related issues.For example, you could use CloudWatch Logs Insights to query for the average duration of your function invocations:“`sqlfields @timestamp, @message| filter @message like /”Duration”:/| parse @message ‘”Duration”:*’ as duration| stats avg(duration) by bin(1h, @timestamp)“`This query extracts the duration from the log messages, calculates the average duration for each hour, and visualizes the results.By effectively using CloudWatch Logs, you can quickly diagnose and resolve issues with your scheduled Lambda functions, ensuring their reliability and performance.
Scaling and Concurrency
The periodic execution of Lambda functions introduces unique challenges related to scaling and concurrency. Understanding and managing these aspects is crucial for ensuring that scheduled tasks run reliably, efficiently, and without being throttled. Effective scaling strategies prevent bottlenecks and maintain application performance, particularly as workloads increase.
Implications of Scaling Lambda Functions for Periodic Tasks
The scaling behavior of Lambda functions for periodic tasks directly impacts their ability to handle varying workloads and maintain consistent execution times. Several factors contribute to the complexity of scaling these functions.
- Concurrency Limits: AWS Lambda has concurrency limits, which define the maximum number of function instances that can execute simultaneously within an account or a specific region. When a scheduled event triggers a function, Lambda attempts to invoke it. If the number of concurrent executions exceeds the configured limit, new invocations are throttled, leading to delayed or failed task executions.
- Cold Starts: Lambda functions experience cold starts when a new function instance needs to be provisioned to handle an invocation. Cold starts can introduce latency, particularly if the function’s initialization code is resource-intensive. This latency can be problematic for time-sensitive periodic tasks.
- Resource Allocation: The memory and CPU resources allocated to a Lambda function influence its performance and ability to handle the workload. Insufficient resources can lead to slower execution times and increased risk of timeouts.
- Cost Considerations: Scaling Lambda functions impacts the associated costs. More frequent or concurrent executions increase the number of function invocations and execution time, which directly translates to higher charges. Therefore, optimizing scaling strategies to minimize costs is essential.
Strategies for Managing Concurrency Limits
Managing concurrency limits is paramount for ensuring that scheduled Lambda functions execute reliably, even during periods of high demand. Several techniques can be employed to mitigate the risks associated with exceeding concurrency limits.
- Increasing Concurrency Limits: AWS allows you to request an increase in your account’s concurrency limits. This can be a straightforward solution if the function’s workload is consistently high and you can justify the increased cost. However, be aware that excessive concurrency can strain other resources within your account.
- Reserved Concurrency: Reserve a specific amount of concurrency for a Lambda function. This ensures that the function always has a guaranteed number of concurrent executions available, preventing it from being throttled by other functions or tasks. This approach is beneficial for critical, time-sensitive periodic tasks.
- Provisioned Concurrency: Provisioned concurrency pre-initializes a specified number of execution environments for a Lambda function. This drastically reduces cold start times and ensures that the function is ready to handle invocations immediately. This is particularly valuable for periodic tasks with strict latency requirements.
- Batching and Parallelization: If the periodic task processes a large dataset, consider batching the data and processing it in parallel across multiple function invocations. This distributes the workload and reduces the likelihood of exceeding concurrency limits. However, be mindful of the increased complexity of managing parallel executions.
- Retry Mechanisms: Implement retry mechanisms to handle throttled invocations gracefully. If a function invocation is throttled, the retry mechanism can resubmit the invocation after a delay, allowing the function to execute once resources become available. This enhances the resilience of the scheduled tasks.
Handling Large Workloads and Preventing Throttling
Effectively managing large workloads is crucial for the smooth operation of periodic Lambda functions. Various strategies can be employed to prevent throttling and ensure that the tasks are completed efficiently.
- Optimize Function Code: Optimize the function’s code to improve its performance and reduce its execution time. This can involve optimizing database queries, reducing the size of dependencies, and streamlining the logic within the function. Faster execution times reduce the demand on concurrency.
- Use Asynchronous Invocation: When invoking other services or functions from your Lambda function, use asynchronous invocation where possible. This allows the Lambda function to quickly return and avoids blocking while waiting for the invoked service to complete.
- Implement Circuit Breakers: Implement circuit breakers to prevent cascading failures. If a downstream service is experiencing issues, the circuit breaker can prevent the Lambda function from repeatedly attempting to invoke it, which could lead to excessive throttling.
- Monitor and Alert: Set up monitoring and alerting to track function performance, concurrency usage, and error rates. This allows you to proactively identify potential issues and take corrective action before they impact the scheduled tasks. AWS CloudWatch can be utilized to monitor and create alarms.
- Implement Rate Limiting: If the periodic task interacts with external APIs or services, implement rate limiting to prevent exceeding their usage quotas. This helps to avoid being throttled by those services and ensures that the task can continue to run.
- Consider Step Functions for Complex Workflows: For tasks involving multiple steps or dependencies, consider using AWS Step Functions to orchestrate the workflow. Step Functions can manage concurrency and retry logic more effectively, reducing the risk of throttling.
Error Handling and Retries
Implementing robust error handling and retry mechanisms is crucial for the reliable execution of scheduled Lambda functions. These mechanisms ensure that transient failures do not result in data loss or incomplete processing, and that the overall system remains resilient. This section details various error handling strategies, including retry policies, and provides a flowchart illustrating the error handling process.
Error Handling Mechanisms for Scheduled Lambda Functions
Several mechanisms are available to handle errors in scheduled Lambda functions, each addressing different failure scenarios. These methods, used individually or in combination, increase the reliability of the function.
- Lambda Function Configuration: The Lambda function itself can be configured to handle errors. This includes defining the function’s timeout, which prevents it from running indefinitely, and configuring dead-letter queues (DLQs) for failed invocations. The DLQ can be an SQS queue or an SNS topic, allowing for inspection and potential reprocessing of failed events.
- CloudWatch Alarms: CloudWatch alarms can monitor metrics related to the Lambda function’s execution, such as errors, throttles, and invocations. These alarms can trigger actions, like sending notifications or invoking other Lambda functions for remediation.
- EventBridge Retry Policies: EventBridge (formerly CloudWatch Events) offers built-in retry policies that can be configured for scheduled events. These policies specify the number of retries, the backoff strategy (e.g., exponential backoff), and the maximum retry interval.
- Step Functions: Step Functions can be used to orchestrate the execution of Lambda functions, providing more sophisticated error handling and retry capabilities. Step Functions allow for defining retry and catch blocks to handle errors gracefully.
- Application-Level Error Handling: Within the Lambda function code itself, developers can implement error handling logic to catch exceptions, log errors, and potentially retry operations. This can include using try-catch blocks and logging errors to CloudWatch Logs.
Implementing Retry Strategies
Retry strategies are essential for handling transient errors, such as temporary network issues or service unavailability. The choice of a retry strategy depends on the nature of the errors and the desired level of resilience.
- Fixed Delay: A fixed delay retry strategy waits a fixed amount of time between retries. This is suitable for errors that might resolve quickly, such as temporary service overload.
- Exponential Backoff: Exponential backoff is a more sophisticated strategy where the delay between retries increases exponentially. This is particularly useful for handling errors that might take longer to resolve. The delay typically starts small and doubles with each retry, preventing the function from overwhelming a potentially overloaded service.
- Randomized Exponential Backoff: This is an improvement on exponential backoff. It adds a random factor to the delay, which can help to avoid a “thundering herd” problem, where multiple retries occur simultaneously and potentially overload the target service.
- Circuit Breaker Pattern: The circuit breaker pattern monitors the success and failure rates of a function. When the failure rate exceeds a threshold, the circuit breaker “opens,” preventing further calls to the function for a certain period. This prevents cascading failures and gives the underlying service time to recover.
Example of an exponential backoff retry strategy implemented in Python:“`pythonimport timeimport randomdef execute_with_retry(function,
args, max_retries=3, base_delay=1, max_delay=60, jitter=0.2)
“”” Executes a function with exponential backoff retry. Args: function: The function to execute.
args
Arguments to pass to the function. max_retries: The maximum number of retries. base_delay: The initial delay in seconds. max_delay: The maximum delay in seconds. jitter: The amount of random jitter to apply (as a percentage).
Returns: The result of the function, or None if all retries fail. “”” for attempt in range(max_retries + 1): try: return function(*args) except Exception as e: if attempt == max_retries: print(f”Function failed after max_retries retries: e”) raise # Re-raise the exception to indicate failure delay = min(base_delay
- (2
- * attempt), max_delay)
delay_with_jitter = delay
(1 + random.uniform(-jitter, jitter))
print(f”Attempt attempt + 1 failed. Retrying in delay_with_jitter:.2f seconds…”) time.sleep(delay_with_jitter)“`
Flowchart: Error Detection, Handling, and Retries
This flowchart Artikels the process of error detection, handling, and retries in a scheduled Lambda function.
The flowchart begins with the “Scheduled Event Triggered” start point.
1. Scheduled Event Triggered
The Lambda function is invoked by the scheduler (EventBridge or similar).
2. Function Execution
The Lambda function starts to execute its code.
3. Error Occurs?
A decision point. If an error occurs during execution, the process moves to the “Yes” branch; otherwise, it moves to the “No” branch.
4. Yes (Error Occurs)
The “Yes” branch handles the error.
5. Error Handling Logic
The error is handled based on the implemented error handling mechanisms (try-catch blocks, EventBridge retry policies, Step Functions error handling, etc.).
6. Retry Allowed?
A decision point based on the retry policy. If retries are allowed, the process moves to the “Yes” branch; otherwise, it moves to the “No” branch.
7. Yes (Retry Allowed)
The “Yes” branch executes the retry.
8. Apply Retry Strategy
The retry strategy (fixed delay, exponential backoff, etc.) is applied.
9. Retry Function
The Lambda function is retried.
1
0. Return to Function Execution
The process loops back to function execution.
1
1. No (Retry Not Allowed)
The “No” branch is taken if retries are not allowed.
1
2. Log Error
The error is logged to CloudWatch Logs.
1
3. Send to Dead Letter Queue (DLQ)
The failed event is sent to a DLQ (if configured).
1
4. Function Ends (Failure)
The function execution ends with a failure.
1
5. No (Error Does Not Occur)
The “No” branch is taken if no error occurs.
1
6. Function Executes Successfully
The function executes successfully.
1
7. Function Ends (Success)
The function execution ends with success.
This flowchart provides a visual representation of the error handling and retry process. It ensures that transient errors are handled effectively, minimizing the impact on the scheduled tasks.
Common Scheduling Challenges and Solutions
Scheduling Lambda functions for periodic execution presents a unique set of challenges, ranging from time zone complexities to performance optimization and cost management. Addressing these challenges effectively ensures the reliable and efficient operation of scheduled tasks.
Time Zone Issues and Daylight Saving Time
Managing time zones and Daylight Saving Time (DST) is critical for ensuring scheduled Lambda functions run at the intended times. Incorrect handling can lead to tasks running at unexpected times or not at all, particularly when dealing with global deployments or applications sensitive to specific time windows.
- Understanding the Impact: Time zone discrepancies arise because different regions observe different time zones and DST schedules. A schedule defined in UTC may appear to run at the correct time in one location but at an offset in another. DST adds another layer of complexity, as clocks shift forward or backward during specific periods of the year, further complicating scheduling.
- Solutions and Best Practices: Several strategies can mitigate these issues:
- Use UTC: Whenever possible, schedule Lambda functions using Coordinated Universal Time (UTC). This eliminates time zone conversions and DST complications, providing a consistent time reference. All AWS services support UTC, which simplifies scheduling.
- EventBridge Time Zones: AWS EventBridge (formerly CloudWatch Events) allows you to specify a time zone for your schedule. This feature translates the schedule to UTC, taking into account the specified time zone and DST rules. This simplifies scheduling for specific local times. However, be mindful of DST transitions, as the schedule’s behavior may change during these periods.
- Leverage AWS Time Zone Support: AWS services often provide built-in support for time zones. For instance, in EventBridge, the `cron` expressions can be defined using a specific time zone, and the service handles the conversions.
- Custom Logic with Lambda: If EventBridge’s time zone support doesn’t meet your needs, you can implement custom logic within your Lambda function. This might involve retrieving the current time in a specific time zone using libraries like `pytz` (Python) or `moment-timezone` (JavaScript) and adjusting the function’s behavior accordingly. However, this approach adds complexity and increases the potential for errors.
- Consider Region-Specific Schedules: For applications targeting users in specific regions, consider deploying separate schedules for each region. This allows for tailoring schedules to local time zones and DST rules, ensuring that functions run at the desired times.
Optimizing Performance and Cost
Efficiently managing performance and cost is crucial for any scheduled Lambda function. Unoptimized functions can lead to unnecessary costs and performance bottlenecks.
- Resource Allocation:
- Memory and CPU: Allocate the appropriate memory and CPU resources to your Lambda function. Over-provisioning leads to higher costs, while under-provisioning can cause performance issues, such as increased execution times or timeouts. Monitor function performance and adjust memory settings accordingly.
- Concurrency Limits: Set appropriate concurrency limits to prevent your Lambda functions from being throttled. Throttling occurs when the number of concurrent executions exceeds the configured limit, causing delays and potential errors. AWS provides metrics for monitoring concurrency and offers ways to increase limits if needed.
- Code Optimization:
- Efficient Code: Write efficient code that minimizes execution time. Optimize database queries, reduce the size of dependencies, and avoid unnecessary operations.
- Cold Starts: Minimize cold start times. Cold starts occur when a Lambda function is invoked for the first time or after a period of inactivity. Use techniques such as keeping the function “warm” by pre-warming them, or using provisioned concurrency, to reduce cold start latency.
- Caching: Implement caching mechanisms where appropriate to reduce the load on external resources, such as databases or APIs.
- Cost Optimization Techniques:
- Right-Sizing Resources: As mentioned, right-sizing memory and CPU is crucial. Monitor the function’s resource usage and adjust settings accordingly.
- Duration and Frequency: Optimize the duration of your Lambda function’s execution. Shorter execution times reduce costs. Also, review the frequency of the scheduled tasks. Ensure that tasks run only as often as necessary.
- Batch Processing: If your Lambda function processes a large number of items, consider batch processing. Processing items in batches can reduce the number of invocations and lower costs.
- Monitoring and Analysis: Regularly monitor your Lambda function’s performance and cost using AWS CloudWatch metrics. Analyze these metrics to identify areas for optimization and cost savings.
- Leveraging AWS Services:
- EventBridge Cost Optimization: Use EventBridge’s scheduling features, such as rate expressions, to efficiently trigger Lambda functions at regular intervals.
- Other AWS Services: Integrate with other AWS services to offload tasks and reduce the load on your Lambda functions. For example, use SQS for asynchronous processing or DynamoDB for storing data.
Advanced Scheduling Scenarios
Effective scheduling of Lambda functions transcends simple periodic execution, enabling sophisticated orchestration of tasks across various AWS services. This section explores advanced scheduling patterns, demonstrating how Lambda functions can be integrated into complex workflows for data processing, automated backups, and system maintenance, ultimately optimizing resource utilization and streamlining operations.
Scheduling Lambda Functions for Data Processing Pipelines
Data processing pipelines often require a series of operations performed in a specific sequence or based on certain triggers. Lambda functions, when scheduled, can act as integral components within these pipelines, orchestrating data transformation, analysis, and storage.Consider a scenario involving processing log files generated by a web server and stored in an S3 bucket.
- Data Ingestion: A scheduled Lambda function, triggered daily, identifies new log files uploaded to the S3 bucket. This function can filter files based on naming conventions (e.g., date-based prefixes) or metadata.
- Data Transformation: The identified log files are then processed by a second Lambda function, triggered by the first. This function parses the log data, extracting relevant information such as timestamps, IP addresses, and error codes. The transformation could involve cleaning the data by removing irrelevant characters or anonymizing sensitive information.
- Data Analysis and Storage: The transformed data is passed to a third Lambda function, scheduled to run immediately after the transformation function completes. This function performs analytical operations, such as calculating the number of unique visitors, identifying top-performing pages, or detecting anomalies. The results are stored in a DynamoDB table or another data store, such as Amazon Redshift, for reporting and visualization.
- Orchestration with Step Functions: To ensure robust error handling and complex workflow management, Step Functions can orchestrate the entire process. Step Functions allow for defining the order of Lambda function execution, incorporating error handling (e.g., retries, dead-letter queues), and handling complex dependencies between steps.
This pipeline exemplifies a scheduled data processing workflow. The scheduling mechanisms ensure the continuous and automated execution of the pipeline, allowing for timely data analysis and insights without manual intervention. The use of separate Lambda functions for each stage promotes modularity and scalability, allowing for individual scaling and independent updates of each function.
Scheduling for Automated Backups and Maintenance Tasks
Automated backups and system maintenance are crucial for ensuring data integrity, disaster recovery, and system stability. Lambda functions, coupled with appropriate scheduling, can be leveraged to automate these critical tasks.
- Automated Database Backups: A scheduled Lambda function can trigger database backups at regular intervals. This function might interact with services like RDS (Relational Database Service) or DynamoDB to create point-in-time snapshots. The backup function would typically involve calling the AWS SDK to initiate the backup process. For instance, to back up a DynamoDB table, the function would use the `create_backup` API call.
- Data Archival: Another scheduled function could be responsible for archiving older data from databases or storage buckets. This function might move data that has reached a certain age to a more cost-effective storage tier, such as Amazon S3 Glacier. This is particularly useful for compliance requirements and cost optimization.
- System Health Checks and Maintenance: Lambda functions can be scheduled to perform regular system health checks, such as verifying the availability of critical services, monitoring resource utilization, and identifying potential issues. These functions can send notifications (e.g., via SNS) or trigger other actions (e.g., scaling resources) based on the results of the checks.
- Maintenance Tasks: Maintenance tasks, like cleaning up temporary files, rotating logs, or updating software dependencies, can be automated using scheduled Lambda functions. These functions would be configured to run during off-peak hours to minimize disruption to normal operations.
For example, a scheduled function could check the free space on EC2 instances and, if the free space falls below a certain threshold, send a notification and potentially trigger an auto-scaling action. The function would use the AWS SDK to connect to the EC2 instances and gather information about their storage utilization. This automation significantly reduces the need for manual intervention, minimizing the risk of data loss or downtime.
Example: Using Scheduled Lambda Functions with S3 and DynamoDB
This example illustrates how a scheduled Lambda function can be used to process data stored in S3 and store the results in DynamoDB. The scenario involves aggregating website traffic data.
- Data Source (S3): Website access logs are continuously uploaded to an S3 bucket. Each log entry contains information about a user’s request, including timestamp, IP address, and requested URL.
- Scheduled Lambda Function: A Lambda function is scheduled to run every hour.
- Function Logic:
- The function retrieves the log files for the previous hour from the S3 bucket.
- It parses the log entries, extracting the relevant data (e.g., number of requests, unique visitors, top URLs).
- The function aggregates the data to generate hourly statistics.
- The aggregated statistics are then stored in a DynamoDB table.
- DynamoDB Table: The DynamoDB table stores the hourly website traffic statistics. The table’s primary key could be a combination of date and hour.
The Lambda function’s code would use the AWS SDK to interact with both S3 and DynamoDB.
For S3, it would use functions like `list_objects_v2` to retrieve the log files and `get_object` to read the file contents. For DynamoDB, it would use functions like `put_item` to write the aggregated data.
This approach provides a near real-time view of website traffic, enabling quick analysis of trends and identification of potential issues. The scheduled execution ensures that the data aggregation is performed consistently and automatically, freeing up resources for other tasks. The combination of S3 for data storage, Lambda for processing, and DynamoDB for storing aggregated results creates a scalable and cost-effective solution for analyzing website traffic data.
Ending Remarks
In conclusion, mastering the art of scheduling Lambda functions periodically opens up a world of possibilities for automating cloud-based tasks. We’ve explored the key AWS services, the intricacies of configuration, and the importance of security, monitoring, and error handling. By leveraging these techniques, developers and system administrators can create robust, scalable, and cost-effective solutions. The ability to trigger Lambda functions on a schedule allows for the seamless integration of automated processes, which is essential for the efficiency of any cloud-based application.
Question Bank
What is the difference between CloudWatch Events and EventBridge?
EventBridge is the evolution of CloudWatch Events, offering more features and enhanced capabilities, including the ability to route events to various targets and integrate with SaaS applications. While CloudWatch Events is still available, EventBridge is generally recommended for new deployments.
Can I use a different time zone for my scheduled Lambda functions?
Yes, you can specify the time zone in the cron expression when creating a schedule in EventBridge. This allows you to align your function executions with specific regional or business requirements.
How can I handle errors and retries for scheduled Lambda functions?
AWS provides built-in mechanisms for handling errors and retries, such as configuring dead-letter queues and setting retry policies in EventBridge. Step Functions also offers comprehensive error handling capabilities, including custom retry logic and error branches.
What are the cost considerations when scheduling Lambda functions?
The cost is primarily based on the number of function invocations, the duration of execution, and the memory allocated to the function. Optimize your code and resource allocation to minimize costs, and use CloudWatch metrics to monitor usage.