Embarking on a serverless project signifies a shift in how applications are conceived, built, and deployed. Serverless computing, at its core, abstracts away the need to manage underlying infrastructure, allowing developers to focus solely on writing code. This paradigm shift offers a compelling alternative to traditional server-based architectures, promising increased agility, reduced operational overhead, and cost optimization. The following discussion will provide a comprehensive overview of the essential steps required to launch and manage a serverless project, from the initial conceptualization to the final deployment.
The Artikel presented serves as a structured guide, beginning with a foundational understanding of serverless principles and extending to practical implementation. It navigates the critical aspects of cloud provider selection, programming language choice, development environment setup, function creation, triggering mechanisms, data handling, and storage. Each section builds upon the previous, providing a cohesive framework for understanding and successfully executing a serverless project.
The aim is to empower readers with the knowledge and tools necessary to embrace serverless computing and leverage its inherent advantages.
Introduction to Serverless Computing
Serverless computing represents a paradigm shift in cloud computing, abstracting away the underlying infrastructure management traditionally associated with server-based applications. This allows developers to focus on writing and deploying code without the need to provision, manage, or scale servers. This approach leverages the “pay-as-you-go” model, optimizing resource utilization and reducing operational overhead.Serverless architecture is a cloud computing execution model where the cloud provider dynamically manages the allocation of machine resources.
This includes server provisioning, scaling, and maintenance. Developers deploy code as functions that are triggered by events, such as HTTP requests, database updates, or scheduled tasks.
Core Concept of Serverless Computing
Serverless computing, at its core, allows developers to execute code without managing servers. The cloud provider handles all the underlying infrastructure, including servers, operating systems, and scaling. This enables developers to concentrate on writing and deploying code, leading to faster development cycles and reduced operational costs.
Definition of Serverless Architecture
Serverless architecture is a design approach where applications are built and run without managing servers. Instead of provisioning and managing virtual machines or containers, developers deploy individual functions, often referred to as “functions as a service” (FaaS), which are triggered by events. These functions are executed on-demand, and the cloud provider automatically scales the resources as needed.
Benefits of Serverless Compared to Traditional Server-Based Approaches
Serverless computing offers several advantages over traditional server-based approaches. These benefits contribute to increased efficiency, reduced costs, and improved scalability.
- Reduced Operational Overhead: Serverless eliminates the need for server provisioning, management, and maintenance. Cloud providers handle all infrastructure-related tasks, freeing up developers to focus on code.
- Automatic Scaling: Serverless platforms automatically scale resources based on demand. This ensures optimal performance and availability, even during periods of high traffic. The system dynamically adjusts resources, such as CPU and memory, to handle the incoming requests without manual intervention.
- Cost Efficiency: Serverless follows a “pay-as-you-go” pricing model. Developers only pay for the compute time their code consumes. This can lead to significant cost savings, especially for applications with intermittent or unpredictable workloads. For instance, consider a web application that processes image uploads. With a traditional server, you would pay for the server resources even when no uploads are occurring.
In a serverless environment, you only pay for the compute time when the image processing function is triggered.
- Faster Development Cycles: Serverless allows developers to deploy code quickly and iterate rapidly. The focus shifts from infrastructure management to code development, accelerating the development process. The elimination of server setup and configuration streamlines the deployment process.
- Improved Scalability and Availability: Serverless applications are inherently scalable and highly available. The cloud provider manages the infrastructure and automatically scales resources to handle increased demand. The distributed nature of serverless platforms enhances fault tolerance and reduces the risk of downtime.
Understanding the ‘Why’ of Serverless

Serverless computing presents a paradigm shift in how applications are built and deployed in the cloud. Moving beyond traditional server management, serverless allows developers to focus on writing code without the operational overhead of provisioning, scaling, and managing servers. This section explores the core motivations behind adopting serverless, examining scenarios where it excels and comparing it with alternative cloud models.
Optimal Project Scenarios for Serverless
Serverless architecture is not a one-size-fits-all solution. Certain project characteristics make it particularly well-suited. Projects with variable workloads, event-driven architectures, and those prioritizing rapid development cycles often benefit most.
- Event-Driven Applications: Serverless excels in event-driven scenarios, such as processing image uploads, responding to database changes, or reacting to API calls. The “pay-per-use” model is highly efficient here, as functions are triggered only when an event occurs. For example, a platform that processes user-uploaded images can trigger a serverless function to resize and optimize each image, incurring costs only when a new image is uploaded.
- Microservices Architectures: Serverless aligns perfectly with microservices, enabling the development and deployment of small, independent services. Each microservice can be implemented as a serverless function, allowing for independent scaling and deployment. This modular approach improves development agility and reduces the impact of failures. Consider an e-commerce platform; different serverless functions could handle order processing, payment verification, and inventory updates.
- Web and Mobile Backends: Serverless functions are ideal for creating APIs and backend logic for web and mobile applications. They can handle authentication, data retrieval, and business logic, abstracting the complexities of server management. For example, a mobile app retrieving user data can use serverless functions to query a database and format the results.
- Data Processing Pipelines: Serverless can streamline data processing tasks. Data can be ingested from various sources and transformed using serverless functions, allowing for efficient data cleaning, enrichment, and analysis. Consider a real-time data streaming pipeline; serverless functions can be triggered to process data as it arrives, enabling immediate insights.
- IoT Applications: Serverless is well-suited for IoT applications that generate data from connected devices. Functions can be triggered by device events, such as sensor readings, and process the data in real-time. This is particularly beneficial for handling a large number of devices and data points. For instance, a smart home system can utilize serverless functions to process data from various sensors and control connected devices.
Serverless vs. Other Cloud Computing Models
Understanding the differences between serverless, Infrastructure-as-a-Service (IaaS), and Platform-as-a-Service (PaaS) is crucial for making informed architectural decisions. Each model offers a different level of abstraction and control, impacting the development process, operational overhead, and cost structure.
- Infrastructure-as-a-Service (IaaS): IaaS provides access to fundamental computing resources like virtual machines, storage, and networks. Users have complete control over the operating system, middleware, and applications. IaaS offers maximum flexibility and control but requires significant operational effort for server management, patching, and scaling. This model is suitable for applications requiring specific hardware configurations or high levels of customization.
- Platform-as-a-Service (PaaS): PaaS offers a platform for developing, running, and managing applications without the complexity of managing the underlying infrastructure. PaaS provides pre-built environments and services, simplifying deployment and scaling. PaaS offers greater ease of use than IaaS but can limit flexibility and customization. It’s best suited for applications that can leverage the platform’s features and services.
- Serverless Computing: Serverless abstracts away server management entirely. Developers only write and deploy code, and the cloud provider handles the underlying infrastructure, scaling, and resource allocation. Serverless offers the highest level of abstraction and reduces operational overhead. The pay-per-use model often leads to significant cost savings, especially for applications with variable workloads. However, serverless may impose limitations on customization and control.
| Feature | IaaS | PaaS | Serverless |
|---|---|---|---|
| Infrastructure Management | User-managed | Provider-managed | Provider-managed |
| Scalability | User-managed | Provider-managed | Automatic |
| Control | High | Medium | Low |
| Flexibility | High | Medium | Low |
| Cost Model | Pay-per-use of resources | Pay-per-use of platform services | Pay-per-execution |
Common Use Cases Highlighting Serverless Advantages
Serverless computing is being successfully deployed across various industries, demonstrating its versatility and benefits. Examining these use cases reveals the advantages of serverless in practice.
- Web Application Backends: Serverless functions can efficiently handle API requests, user authentication, and data retrieval for web applications. This model allows for rapid scaling based on traffic demands. For example, a social media platform can use serverless functions to process user profile updates, manage friend requests, and serve personalized content.
- Mobile Application Backends: Serverless simplifies backend development for mobile apps. Functions can manage user authentication, data storage, and push notifications. This allows mobile developers to focus on the user interface and experience. For instance, a food delivery app can use serverless functions to process orders, track drivers, and manage payments.
- Real-time Data Processing: Serverless functions can process data streams in real-time, enabling immediate insights and actions. This is valuable for applications requiring immediate response to events. For example, a financial trading platform can use serverless functions to analyze market data and trigger automated trading strategies.
- Chatbots and Conversational AI: Serverless provides a scalable and cost-effective platform for building chatbots and conversational AI applications. Functions can handle natural language processing, user interactions, and integrations with other services. For instance, a customer service chatbot can use serverless functions to answer customer inquiries and resolve issues.
- Image and Video Processing: Serverless can automate image and video processing tasks, such as resizing, optimization, and transcoding. This streamlines content delivery and improves user experience. For example, an e-commerce website can use serverless functions to automatically resize product images for different devices.
Choosing a Cloud Provider
Selecting a cloud provider is a pivotal decision when embarking on a serverless project. This choice significantly impacts development workflows, cost structures, and the overall capabilities available for building and deploying applications. The market offers several robust options, each with its own strengths and weaknesses. Careful consideration of these factors is crucial for maximizing the benefits of serverless computing.
Popular Cloud Providers and Serverless Offerings
The serverless landscape is dominated by three major players: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Each provider offers a comprehensive suite of serverless services, designed to cater to a wide range of application requirements. Understanding the core offerings of each is essential for making an informed decision.
- Amazon Web Services (AWS): AWS is a pioneer in the cloud computing space and boasts a mature and extensive serverless ecosystem.
- AWS Lambda: The flagship compute service, AWS Lambda allows developers to run code without provisioning or managing servers. It supports various programming languages, including Node.js, Python, Java, Go, and .NET. Lambda functions are triggered by events from various AWS services, such as Amazon S3, Amazon DynamoDB, and Amazon API Gateway.
- Amazon API Gateway: This service enables developers to create, publish, maintain, monitor, and secure APIs at any scale. It supports RESTful APIs, WebSocket APIs, and HTTP APIs, making it a versatile tool for building backend services.
- Amazon DynamoDB: A fully managed NoSQL database service that provides high performance and scalability. It’s well-suited for serverless applications due to its pay-per-request pricing model and automatic scaling capabilities.
- Amazon S3: An object storage service offering scalability, data availability, security, and performance. It’s frequently used to store static assets, data backups, and media files for serverless applications.
- Microsoft Azure: Azure provides a compelling serverless platform deeply integrated with the Microsoft ecosystem.
- Azure Functions: Similar to AWS Lambda, Azure Functions allows developers to execute code in a serverless environment. It supports multiple programming languages, including C#, JavaScript, Python, and Java. Azure Functions can be triggered by various events, such as HTTP requests, timer triggers, and events from Azure services like Azure Blob Storage and Azure Event Hubs.
- Azure API Management: A fully managed service that enables developers to publish, secure, transform, and monitor APIs. It offers features like API gateway functionality, access control, and analytics.
- Azure Cosmos DB: A globally distributed, multi-model database service that supports various data models, including document, key-value, graph, and column-family. It’s designed for high availability and scalability.
- Azure Blob Storage: An object storage service for storing large amounts of unstructured data. It’s suitable for storing images, videos, backups, and other types of data.
- Google Cloud Platform (GCP): GCP offers a robust serverless platform with a strong focus on data analytics and machine learning.
- Google Cloud Functions: Google Cloud Functions is a serverless execution environment that allows developers to run event-driven functions. It supports languages like Node.js, Python, Go, Java, and .NET. Functions can be triggered by events from services such as Cloud Storage, Cloud Pub/Sub, and HTTP requests.
- Google Cloud API Gateway: A fully managed service for creating, securing, and monitoring APIs. It supports various API formats, including RESTful APIs and gRPC APIs.
- Cloud Firestore: A NoSQL document database designed for automatic scaling, high performance, and ease of development. It’s suitable for building mobile, web, and serverless applications.
- Cloud Storage: An object storage service that provides a highly durable and scalable storage solution. It’s ideal for storing various data types, including images, videos, and backups.
Comparing Pricing Models for a Basic Function
Pricing models for serverless services can vary significantly across providers. Understanding these differences is crucial for optimizing costs. This comparison focuses on a basic function that executes a simple “Hello, World!” program, triggered by an HTTP request, and processes 100,000 invocations per month. Note that pricing is subject to change and may vary depending on region and specific configurations. This is a simplified comparison to illustrate key differences.
| Cloud Provider | Free Tier (approximate) | Pricing Model (per invocation, after free tier) | Example Cost (100,000 invocations/month) |
|---|---|---|---|
| AWS Lambda | 1 million free requests per month | Approximately $0.0000002 per invocation (based on execution time and memory allocation) | Variable, depending on function execution time and memory. For example, with 128MB memory and 100ms execution time: approximately $0.20 |
| Azure Functions | 1 million free executions per month | Approximately $0.000016 per execution (based on execution time and memory) | Variable, depending on execution time and memory. For example, with 128MB memory and 100ms execution time: approximately $1.60 |
| Google Cloud Functions | 2 million free invocations per month | Approximately $0.0000004 per invocation (based on execution time and memory) | Variable, depending on function execution time and memory. For example, with 128MB memory and 100ms execution time: approximately $0.40 |
The table above provides a simplified view. Factors like data transfer, storage usage, and the specific services used within the function can significantly impact the overall cost. It is essential to carefully analyze the pricing models of each provider based on the expected workload and resource consumption of the serverless application. For example, an application heavily reliant on database operations might find that the cost of the database service, such as DynamoDB or Cosmos DB, is more significant than the compute cost of the Lambda or Function invocations.
Similarly, applications transferring large amounts of data in and out of the cloud will need to consider data transfer costs. Therefore, a thorough cost analysis, considering all relevant service charges, is crucial for making informed decisions.
Selecting a Programming Language and Runtime
Choosing the right programming language and runtime environment is a critical decision in serverless development. This selection directly impacts development speed, performance, cost, and the overall maintainability of your serverless applications. The ideal choice depends on the specific project requirements, the cloud provider’s supported languages, and the developer’s familiarity with the available options. Careful consideration ensures efficient resource utilization and optimal application performance within the serverless framework.
Programming Languages Supported by Serverless Platforms
Serverless platforms offer a variety of programming languages, allowing developers to leverage their existing skills and choose the best tool for the job. The specific support varies slightly between providers, but common languages include:
- JavaScript/Node.js: Widely supported due to its lightweight nature and vast ecosystem of packages. Node.js is particularly popular for building APIs and handling event-driven architectures.
- Python: Python is a strong choice for serverless applications, especially those involving data science, machine learning, and scripting. Its readability and extensive libraries make it attractive for various tasks.
- Java: Java is a performant language suitable for enterprise-grade applications. Serverless Java applications often utilize frameworks like Spring Boot to streamline development.
- Go: Go’s speed and efficiency make it an excellent choice for performance-critical serverless functions. Its built-in concurrency features are well-suited for handling multiple requests simultaneously.
- C#: C# is a popular choice for developers familiar with the .NET ecosystem. It allows seamless integration with other Microsoft services within a serverless context.
- Ruby: While less common than the others, Ruby is supported on some platforms, offering developers a familiar environment for building serverless applications.
Each cloud provider has its own specific set of supported languages. For instance, AWS Lambda supports JavaScript (Node.js), Python, Java, Go, C#, and Ruby. Azure Functions supports C#, JavaScript, Python, Java, PowerShell, and others. Google Cloud Functions supports Node.js, Python, Go, Java, .NET, and Ruby. The availability of languages and their supported versions may change over time.
It is crucial to consult the latest documentation from the cloud provider for the most up-to-date information.
Considerations for Choosing a Programming Language for Serverless Development
Selecting the appropriate programming language involves evaluating several factors to optimize development efficiency and application performance. These considerations include:
- Performance Requirements: For computationally intensive tasks, languages like Go or Java, known for their speed, might be preferable. Node.js and Python are often suitable for tasks where speed is less critical.
- Developer Expertise: Utilizing a language with which the development team is already proficient can significantly reduce the learning curve and accelerate development time.
- Ecosystem and Libraries: The availability of relevant libraries and frameworks is crucial. Python’s extensive data science libraries, for example, make it ideal for machine learning applications. Node.js’s npm package manager offers a vast selection of modules.
- Cold Start Time: Cold start time, the delay before a function begins executing after an invocation, varies between languages. Java generally has longer cold start times than languages like Node.js or Python.
- Cost Implications: The runtime environment’s resource consumption affects costs. Optimized code and efficient language choices can minimize resource usage and, therefore, reduce expenses.
- Cloud Provider Support: Verify that the chosen language is supported by your selected cloud provider. Also, check the version support and any associated limitations.
Best Practices for Selecting Runtimes in Serverless Environments
Choosing the right runtime environment alongside the programming language is critical for efficient serverless application development. Following these best practices can improve performance, reduce costs, and enhance maintainability:
- Use the Latest Supported Runtimes: Cloud providers regularly update runtimes with performance improvements, security patches, and new features. Using the most recent version ensures optimal performance and security.
- Optimize Dependencies: Minimize the size of dependencies by only including the necessary packages. Larger dependencies can increase cold start times and deployment package sizes.
- Utilize Native Image Compilation (where applicable): Languages like Java can benefit from native image compilation (e.g., GraalVM) to reduce cold start times and improve performance.
- Monitor and Profile Performance: Regularly monitor function performance and use profiling tools to identify bottlenecks. This allows for targeted optimizations.
- Choose Appropriate Memory Allocation: Allocate the appropriate memory for your function based on its requirements. Under-allocating can lead to performance issues, while over-allocating can increase costs.
- Consider Containerization: For complex applications or when needing more control over the runtime environment, consider containerizing your functions using tools like Docker. This allows for greater portability and consistency across environments.
- Leverage Runtime Configuration: Use environment variables and configuration files to manage runtime settings. This allows you to modify behavior without redeploying code.
Setting Up Your Development Environment
Establishing a robust development environment is critical for efficient serverless project creation and testing. A well-configured environment minimizes debugging time and facilitates rapid iteration. This section details the essential tools and processes necessary to set up a productive local serverless development workflow.
Tools Needed for Local Serverless Development
Effective serverless development necessitates a suite of tools designed for coding, debugging, and deployment. These tools streamline the development lifecycle, improving productivity and ensuring code quality.
- Integrated Development Environments (IDEs): IDEs provide comprehensive support for code editing, debugging, and project management. The choice of IDE often depends on the selected programming language. For example:
- Visual Studio Code (VS Code): A versatile and widely-used IDE with extensive support for various languages through extensions. It offers robust debugging capabilities and integrates seamlessly with cloud providers.
- IntelliJ IDEA: A powerful IDE, particularly well-suited for Java-based serverless projects. It offers advanced code completion, refactoring, and debugging features.
- AWS Cloud9: A cloud-based IDE provided by AWS, offering a pre-configured environment for serverless development, including AWS SDKs and CLI tools.
- Command-Line Interface (CLI) Tools: CLIs are indispensable for interacting with cloud provider services and managing serverless applications. Common CLI tools include:
- AWS CLI: Allows interaction with AWS services, including deploying, managing, and testing serverless functions. It simplifies the deployment process and provides access to AWS resources.
- Azure CLI: Enables interaction with Azure services, including deploying and managing Azure Functions. It provides a command-line interface for managing Azure resources.
- Google Cloud SDK (gcloud): Used for interacting with Google Cloud services, including deploying and managing Cloud Functions. It facilitates the management of Google Cloud resources.
- Serverless Framework: A popular framework that simplifies the deployment and management of serverless applications across different cloud providers. It uses a declarative approach to define infrastructure and functions, reducing boilerplate code.
- Local Testing Frameworks: These frameworks enable developers to test serverless functions locally before deploying them to the cloud. Examples include:
- LocalStack: Provides a local AWS cloud environment for testing serverless applications. It emulates various AWS services, enabling developers to test their functions without deploying them to the cloud.
- Serverless Offline: A plugin for the Serverless Framework that allows local invocation of serverless functions. It simulates the behavior of the cloud provider’s event triggers.
- Debugging Tools: Debugging tools are crucial for identifying and resolving issues in serverless functions. These include:
- IDE Debuggers: Most IDEs provide built-in debuggers that allow developers to step through code, inspect variables, and identify errors.
- Cloud Provider Debugging Tools: Cloud providers offer debugging tools, such as AWS X-Ray, for tracing and analyzing serverless functions’ execution.
Organizing Steps for Local Serverless Function Testing Environment
Setting up a local testing environment involves configuring the necessary tools and configurations to execute and debug serverless functions locally. This process mirrors the cloud environment as closely as possible, facilitating accurate testing and debugging.
- Install Required Tools: Install the chosen IDE, CLI tools, and any necessary local testing frameworks, such as LocalStack or Serverless Offline. Ensure the CLI tools are configured with the appropriate cloud provider credentials.
- Configure Local Testing Framework: Set up the local testing framework to emulate the cloud provider’s environment. This typically involves configuring the framework to listen on specific ports and providing access to cloud provider resources. For example, when using LocalStack, ensure it is running and configured with the required AWS services.
- Set Up Function Code: Create or obtain the serverless function code. Ensure the code is compatible with the selected programming language and runtime.
- Configure Event Triggers: Define the event triggers that will invoke the function. This might involve configuring an HTTP endpoint, a scheduled event, or a database trigger. For example, configure an API Gateway endpoint to trigger an HTTP function.
- Test Function Locally: Invoke the function locally using the local testing framework or CLI tools. This allows for testing the function’s behavior without deploying it to the cloud.
- Debug Function Locally: Utilize the IDE debugger or debugging tools to step through the function code, inspect variables, and identify any errors. This facilitates efficient debugging.
- Iterate and Refactor: Based on the test results, iterate on the function code, fix any errors, and refactor the code for improved performance and maintainability. Repeat the testing and debugging steps until the function behaves as expected.
Configuring a Basic Serverless Project Structure
A well-defined project structure promotes code organization, maintainability, and scalability. This structure helps in managing the serverless function code, configuration files, and dependencies.
- Project Root Directory: This directory serves as the top-level container for the entire project. It typically contains the configuration files and subdirectories.
- Function Directories: Each serverless function should reside in its own directory. This structure allows for better organization and easier management of individual functions. For example:
/my-project/functions/hello-world/index.js/my-project/functions/process-data/main.py
- Configuration Files: These files define the project’s configuration, including the cloud provider, function names, event triggers, and resource settings.
- serverless.yml (or serverless.js): This file defines the configuration for the Serverless Framework. It specifies the function’s runtime, handler, event triggers, and resource definitions.
- package.json: This file lists the project’s dependencies and scripts for building, testing, and deploying the application.
- Dependencies: The project’s dependencies should be managed using a package manager like npm or pip.
- node_modules: This directory contains the project’s Node.js dependencies.
- requirements.txt: This file lists the project’s Python dependencies.
- Supporting Files: These files include supporting code, libraries, and documentation.
- utils/: A directory to store utility functions and modules.
- tests/: A directory to store unit and integration tests.
- README.md: A file to document the project’s purpose, usage, and dependencies.
Building a Simple Serverless Function
Creating a basic serverless function is the foundational step in understanding and utilizing serverless architecture. This process involves writing the code, configuring the environment, and deploying it to a cloud provider. This section will guide you through the practical steps of implementing a “Hello, World!” function, demonstrating the core concepts of serverless development.
Writing a “Hello, World!” Function
The initial function, often a “Hello, World!” program, serves as a crucial starting point. It allows developers to verify that the environment is correctly set up and that the deployment process functions as expected. This simple function provides a fundamental understanding of serverless execution.Here are code examples in Python and Node.js:
- Python Example: This example uses the `lambda_handler` function, a common entry point for serverless functions in AWS Lambda. The function receives an event and context, and returns a JSON response.
import json def lambda_handler(event, context): return 'statusCode': 200, 'body': json.dumps('Hello, World!') - Node.js Example: This example uses a similar structure to the Python example. It exports a handler function that receives an event and context, and returns a JSON response. The `exports.handler` function is the entry point for the serverless function.
exports.handler = async (event) => const response = statusCode: 200, body: JSON.stringify('Hello, World!'), ; return response; ; Deploying the Function to a Cloud Provider
Deploying the function involves packaging the code and configuration, and then uploading it to the chosen cloud provider. The deployment process varies slightly depending on the provider, but the core steps remain consistent. This section illustrates the deployment process using AWS Lambda as an example.
- AWS Lambda Deployment Steps:
- Packaging the Code: For Python, you typically zip the Python file. For Node.js, you would usually include the `index.js` file and any dependencies specified in `package.json`.
- Using the AWS Management Console: Navigate to the AWS Lambda service in the AWS Management Console.
- Creating a New Function: Click the “Create function” button. Choose “Author from scratch.”
- Configuring the Function:
- Provide a function name.
- Select the runtime (e.g., Python 3.9 or Node.js 16.x).
- Choose an execution role (IAM role) that grants the function the necessary permissions. If creating a new role, ensure it has permissions for basic Lambda execution and CloudWatch logging.
- Uploading the Code: Upload the zipped code package.
- Configuring the Handler: Specify the handler (e.g., `lambda_function.lambda_handler` for Python, or `index.handler` for Node.js).
- Testing the Function: Configure a test event (e.g., a simple JSON object). Then, click the “Test” button to execute the function. The output, including the “Hello, World!” message, will be displayed in the execution results.
The specific commands or steps will differ slightly for other providers like Google Cloud Functions or Azure Functions, but the underlying principle of uploading the code and configuring the handler remains the same. Successful deployment and execution of the “Hello, World!” function confirm the setup and functionality of the serverless environment.
Triggering and Invoking Functions
Serverless functions, by their very nature, are designed to be reactive. They are not constantly running, but rather, they are triggered by specific events. This event-driven architecture is a cornerstone of serverless computing, enabling efficient resource utilization and scalability. Understanding the various triggering mechanisms and invocation methods is crucial for building robust and responsive serverless applications.
Triggering Mechanisms
The methods for initiating the execution of a serverless function are diverse, reflecting the broad range of use cases serverless computing addresses. These triggers act as the entry points, initiating function execution in response to predefined events.
- HTTP Requests via API Gateway: This is a common trigger for web applications and APIs. An API Gateway, provided by cloud providers like AWS API Gateway, Azure API Management, or Google Cloud API Gateway, acts as a front-end for your serverless functions. When an HTTP request (GET, POST, PUT, DELETE, etc.) is received by the API Gateway, it routes the request to the appropriate serverless function.
The gateway handles tasks such as authentication, authorization, rate limiting, and request transformation, allowing the function to focus on the core business logic.
- Events from Cloud Services: Many cloud services emit events that can trigger serverless functions. For example:
- Object Storage Events: Uploading or deleting a file in cloud storage (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage) can trigger a function to process the file, generate thumbnails, or perform other operations.
- Database Events: Changes in a database (e.g., new entries, updates, deletions) can trigger functions to perform data validation, send notifications, or update related data.
- Message Queue Events: Messages placed in a message queue (e.g., AWS SQS, Azure Service Bus, Google Cloud Pub/Sub) can trigger functions to process those messages. This is useful for asynchronous processing, decoupling different parts of an application, and handling high volumes of data.
- Scheduled Events (Cron Jobs): Serverless functions can be triggered on a schedule, similar to traditional cron jobs. Cloud providers offer services like AWS CloudWatch Events (formerly CloudWatch Events), Azure Logic Apps, and Google Cloud Scheduler to define and manage these schedules. This allows functions to perform tasks at regular intervals, such as generating reports, cleaning up data, or sending automated emails.
- Direct Function Invocation: Functions can be invoked directly from other functions or services within the same cloud environment. This is useful for breaking down complex tasks into smaller, reusable functions. This is often done using SDKs or APIs provided by the cloud provider.
Invoking Functions
Invoking a serverless function involves initiating its execution, often passing it data or context required for its operation. The method of invocation depends on the trigger and the relationship between the invoking service and the function.
- Synchronous Invocation: In synchronous invocation, the invoker waits for the function to complete its execution and receive a response. This is common when a function is part of a web API, where the client expects an immediate response. API Gateway typically handles synchronous invocation.
- Asynchronous Invocation: In asynchronous invocation, the invoker does not wait for the function to complete. The function is triggered, and the invoker can continue with other tasks. This is often used for background processing, where immediate results are not required. Message queues and event-driven architectures often utilize asynchronous invocation.
- Invocation from Other Services: Functions can be invoked from other cloud services, such as databases, storage services, or other serverless functions. This can be achieved using:
- Cloud Provider SDKs: Using the cloud provider’s Software Development Kit (SDK) to invoke functions. The SDK provides APIs for triggering functions and managing the invocation process.
- HTTP Requests: If the function is exposed via an API Gateway, other services can invoke it by sending HTTP requests.
- Event-Driven Systems: Services can publish events that trigger functions, enabling a decoupled and scalable architecture.
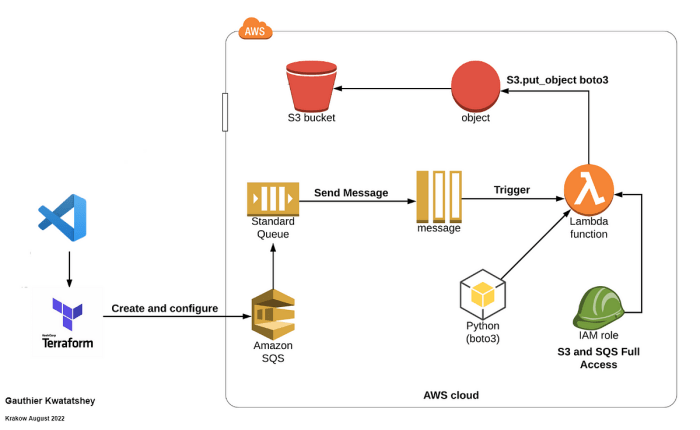
Illustration: API Gateway Trigger and Database Storage
This illustration demonstrates a common serverless pattern: a function triggered by an API Gateway and storing data in a database.
Description of the illustration:
The diagram depicts the flow of data from a user to a database, mediated by serverless components.
- User Interface (UI): A user interacts with a web or mobile application (UI). The UI sends an HTTP POST request containing data to the API Gateway.
- API Gateway: The API Gateway receives the HTTP request. It handles authentication, authorization, and routing. It then forwards the request to the serverless function.
- Serverless Function: The serverless function receives the request from the API Gateway. It processes the data, validates it, and transforms it if necessary.
- Database: The serverless function uses a database client library (e.g., for AWS DynamoDB, Azure Cosmos DB, or Google Cloud Firestore) to store the data in a database. The database stores the data persistently.
- Response: The serverless function sends a response back to the API Gateway. The API Gateway forwards the response to the UI.
The illustration visually represents the following:
- Trigger: The API Gateway triggers the serverless function.
- Invocation: The API Gateway invokes the function, passing the request data.
- Data Flow: The flow of data from the UI through the API Gateway, to the serverless function, to the database, and back to the UI.
- Technology Stack: It indirectly implies the use of serverless technologies such as API Gateway, Function-as-a-Service (FaaS) platform (e.g., AWS Lambda, Azure Functions, Google Cloud Functions), and a database service.
Handling Data and Storage
Serverless architectures necessitate a shift in how data is managed. Traditional stateful servers with persistent storage are often replaced with stateless functions interacting with various data storage services. This section explores common data storage options in serverless environments, providing practical examples and best practices for secure data handling.
Common Data Storage Options in Serverless Environments
The choice of data storage depends heavily on the specific application requirements, including data structure, access patterns, and scalability needs. Several options are well-suited for serverless deployments, each offering distinct advantages.
- Databases: Databases provide structured data storage, ideal for applications requiring relational or NoSQL data models. The key is to select a database that integrates well with the chosen cloud provider’s serverless offerings, such as AWS DynamoDB, Google Cloud Firestore, or Azure Cosmos DB.
- Object Storage: Object storage, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage, is designed for storing unstructured data like images, videos, and documents. It offers high scalability, durability, and cost-effectiveness, making it suitable for content delivery, data backups, and archival purposes.
- Key-Value Stores: Key-value stores, such as Redis or Memcached (often managed services), are used for caching frequently accessed data, session management, and storing simple data structures. They provide fast read and write operations, improving application performance.
- File Storage: While less common than object storage, serverless functions can interact with file storage solutions like network file systems (NFS) or cloud-based file shares when necessary. However, this approach can introduce complexities in a serverless environment, and object storage is generally preferred.
Interacting with a Database from a Serverless Function
Interacting with a database from a serverless function typically involves using a Software Development Kit (SDK) provided by the cloud provider or a database-specific client library. The following example illustrates how to interact with a DynamoDB table from an AWS Lambda function using Python. This example assumes the necessary AWS credentials and permissions are configured.“`pythonimport boto3import jsondef lambda_handler(event, context): # Initialize DynamoDB client dynamodb = boto3.resource(‘dynamodb’) table_name = ‘your-table-name’ # Replace with your table name table = dynamodb.Table(table_name) try: # Example: Writing data to the table response = table.put_item( Item= ‘id’: event[‘id’], ‘name’: event[‘name’] ) print(f”Item added successfully: response”) # Example: Reading data from the table item_id = event[‘id’] response = table.get_item( Key= ‘id’: item_id ) item = response.get(‘Item’) if item: print(f”Item retrieved: item”) return ‘statusCode’: 200, ‘body’: json.dumps(item) else: return ‘statusCode’: 404, ‘body’: json.dumps(‘message’: ‘Item not found’) except Exception as e: print(f”Error: e”) return ‘statusCode’: 500, ‘body’: json.dumps(‘message’: ‘Internal Server Error’) “`In this example, the Python code uses the `boto3` library (the AWS SDK for Python) to interact with DynamoDB.
The function first initializes a DynamoDB resource and specifies the target table. It then demonstrates how to write data using `put_item` and read data using `get_item`. Error handling is included to provide informative responses. The `event` object, passed to the Lambda function, typically contains the data to be written or the identifier of the item to be retrieved. The function returns a JSON response indicating success or failure, along with the retrieved data if applicable.
This example is a basic illustration; real-world applications often involve more complex data models, error handling, and security considerations.
Best Practices for Data Security in Serverless Projects
Data security is paramount in serverless applications. Implement the following practices to protect sensitive information.
- Use Encryption: Encrypt data at rest and in transit. Cloud providers offer encryption services for storage and network traffic. For example, AWS provides KMS (Key Management Service) for managing encryption keys and encryption options for S3 buckets and DynamoDB tables.
- Implement Access Control: Employ the principle of least privilege. Grant serverless functions only the necessary permissions to access data. Use Identity and Access Management (IAM) roles and policies to control access to data storage resources.
- Validate and Sanitize Input: Sanitize all user inputs to prevent injection attacks. Validate data formats and types to ensure data integrity.
- Monitor and Audit: Enable logging and monitoring to track data access and identify potential security breaches. Use security auditing tools to review configurations and identify vulnerabilities.
- Protect Sensitive Data: Never store sensitive information (passwords, API keys, etc.) directly in code. Use environment variables, secret management services (e.g., AWS Secrets Manager, Google Cloud Secret Manager), or secure configuration files.
- Regularly Update Dependencies: Keep all dependencies, including SDKs and database client libraries, up-to-date to patch security vulnerabilities.
- Follow Security Best Practices: Adhere to security best practices provided by your cloud provider and industry standards (e.g., OWASP).
Final Summary
In conclusion, venturing into the realm of serverless computing necessitates a strategic approach, encompassing careful provider selection, proficient code development, and a thorough understanding of data management principles. The journey from a basic “Hello, World!” function to a fully functional serverless application involves a progressive series of steps, each of which is designed to simplify and optimize the development process.
By adopting the Artikeld practices and insights, developers can unlock the full potential of serverless architecture, creating scalable, cost-effective, and highly efficient applications. The serverless paradigm presents a powerful solution for modern application development, and understanding its intricacies will be essential for developers seeking to thrive in the future of cloud computing.
Common Queries
What are the key advantages of using serverless computing?
Serverless computing offers several benefits, including automatic scaling, reduced operational costs, increased developer productivity, and pay-per-use pricing. It eliminates the need for server management, allowing developers to focus on code.
What are the potential drawbacks or challenges of serverless?
Serverless can introduce complexities in debugging and monitoring, potential vendor lock-in, and cold start issues (initial function invocation latency). It also requires a shift in mindset regarding application architecture and deployment.
How do I choose the right cloud provider for my serverless project?
The choice of cloud provider depends on project requirements, existing infrastructure, and budget. Consider factors like pricing, available services, supported programming languages, and the provider’s ecosystem. AWS, Azure, and Google Cloud are popular options.
How does serverless impact the cost of running an application?
Serverless typically reduces costs through pay-per-use pricing. You only pay for the compute time and resources your functions consume. This can be more cost-effective than traditional server-based models, especially for applications with variable traffic.