Serverless computing, with its promise of scalability and reduced operational overhead, has revolutionized application development. However, the inherent complexities of serverless architectures can lead to unexpected cost overruns if not carefully managed. Understanding and controlling these expenses requires a proactive approach, and at the heart of effective cost management lies the strategic application of tagging. This exploration delves into the intricacies of analyzing serverless application costs using tagging, providing a comprehensive guide to optimizing resource utilization and maintaining financial control.
This analysis encompasses a broad spectrum of cloud platforms, including AWS, Azure, and Google Cloud Platform, examining how tagging can be implemented to dissect cost drivers across various serverless services such as Lambda, Functions, and Cloud Run. The focus will be on practical strategies, from setting up robust monitoring dashboards and automating cost data analysis to implementing cost optimization techniques and leveraging automation for consistent governance.
This framework empowers organizations to not only understand their serverless spending but also to proactively manage and reduce costs.
Understanding Serverless Cost Drivers

Serverless computing, while offering significant advantages in terms of scalability and operational efficiency, introduces a distinct cost model. Understanding the key factors that drive expenses is crucial for optimizing serverless application budgets. These cost drivers are primarily related to resource consumption and usage patterns, which directly influence the overall financial outlay.
Code Execution Time
Code execution time is a fundamental cost driver in serverless environments. The longer a function runs, the more resources it consumes, leading to higher charges. This is often measured in milliseconds or seconds, depending on the provider.Consider the following scenario:
- A serverless function processes image thumbnails.
- Function A, with optimized code, processes an image in 200ms.
- Function B, with less efficient code, takes 800ms.
- Both functions are invoked 10,000 times.
Assuming a hypothetical cost of $0.0000002 per millisecond, the cost breakdown would be:
Function A
200ms
- 10,000 invocations
- $0.0000002/ms = $0.40
- 10,000 invocations
- $0.0000002/ms = $1.60
Function B
800ms
This illustrates that Function B, despite performing the same task, is significantly more expensive due to its longer execution time. Code optimization, therefore, is paramount.
Number of Invocations
The number of times a serverless function is invoked directly impacts costs. Each invocation, regardless of its duration, incurs a charge. This is particularly relevant for applications with high traffic or those that trigger functions frequently.The billing model typically charges a small fee per invocation, and this fee is added to the execution time costs. For example:
- A serverless function costs $0.0000002 per millisecond and $0.0000004 per invocation.
- The function runs for 500ms per invocation.
If the function is invoked 100,000 times, the total cost would be:
Execution Time Cost
500ms
- 100,000 invocations
- $0.0000002/ms = $10
- $0.0000004/invocation = $4
Invocation Cost
100,000 invocations
Total Cost
$10 + $4 = $14
Therefore, the more frequently a function is triggered, the higher the overall cost. Optimizing the application to minimize unnecessary invocations can lead to substantial cost savings. This can be achieved through techniques such as caching, event aggregation, and efficient event handling.
Memory Allocation
The amount of memory allocated to a serverless function also affects its cost. Serverless providers typically offer different memory tiers, each with associated pricing. Allocating more memory can improve performance, as it allows the function to execute faster, but it also increases the cost per execution. The optimal memory allocation depends on the function’s resource requirements and the trade-off between performance and cost.The following is a scenario to illustrate: A serverless function is used to process large datasets.
Scenario 1
128MB memory allocation. Execution time: 1.2 seconds. Cost per execution: $0.0002
Scenario 2
1024MB memory allocation. Execution time: 0.4 seconds. Cost per execution: $0.0008If the function is invoked 10,000 times:
Scenario 1 Total Cost
10,000$0.0002 = $2
Scenario 2 Total Cost
10,000
- $0.0008 = $8
While Scenario 2 offers faster execution, the increased memory allocation makes it more expensive overall. Careful consideration of memory requirements is critical.
Region Selection
The geographical region where a serverless function is deployed influences its cost. Serverless providers often have different pricing structures for different regions, with some regions being more expensive than others. Choosing the right region is essential for cost optimization, but it is also crucial to consider factors such as latency and data residency requirements.* Consider two hypothetical regions, Region A and Region B.
Region A
Function execution costs $0.0000002 per millisecond.
Region B
Function execution costs $0.0000003 per millisecond.
A function runs for 1 second (1000ms) and is invoked 1,000,000 times.
The cost comparison:
Region A
1000ms
- 1,000,000
- $0.0000002 = $200
- 1,000,000
- $0.0000003 = $300
Region B
1000ms
Deploying in Region A saves $100 in this scenario. The difference can be significant for large-scale applications.
The Role of Tagging in Cost Allocation
Tagging is a critical practice in serverless environments, enabling precise cost allocation and granular expense tracking. It facilitates the organization and categorization of cloud resources, providing the necessary data for understanding and managing serverless spending effectively. This granular control is crucial for optimizing resource utilization and minimizing unnecessary costs, ultimately leading to more efficient cloud operations.
Purpose of Tagging in Serverless Environments
Tagging in serverless environments serves the primary purpose of organizing and categorizing cloud resources, which allows for improved cost management and resource allocation. Tags act as metadata labels, allowing for the association of key-value pairs with individual resources or groups of resources. This association facilitates the grouping of resources based on various criteria such as project, department, environment (e.g., development, production), or application.
The strategic use of tags allows for detailed cost analysis, resource optimization, and the ability to identify cost drivers.
Categorizing Resources for Expense Tracking
Tags provide a powerful mechanism for categorizing resources, enabling detailed expense tracking and reporting. By applying relevant tags to serverless components like Lambda functions, API Gateways, and DynamoDB tables, it is possible to track costs associated with specific projects, teams, or applications. This level of detail allows for a deeper understanding of where cloud spending is concentrated.Consider the following scenario: an organization deploys a serverless application comprising several Lambda functions, an API Gateway, and a DynamoDB database.
To track costs effectively, the following tags might be applied:
- Project: The name of the project (e.g., “CustomerPortal”, “InventoryManagement”).
- Environment: The deployment environment (e.g., “Development”, “Staging”, “Production”).
- Team: The development team responsible for the application (e.g., “FrontendTeam”, “BackendTeam”).
- Application: The name of the application (e.g., “UserAuthentication”, “OrderProcessing”).
By leveraging these tags, the organization can generate cost reports that break down expenses by project, environment, team, and application. This granular view enables the identification of cost anomalies, resource inefficiencies, and areas for optimization. For example, a report might reveal that the “CustomerPortal” project in the “Production” environment is consuming a disproportionate amount of resources, prompting an investigation into potential bottlenecks or inefficient code.
Best Practices for Implementing Tagging Strategies
Implementing a robust tagging strategy is essential for effective cost management in serverless environments. Adhering to best practices ensures consistency, accuracy, and usability of cost data.
- Establish a Tagging Policy: Develop a comprehensive tagging policy that defines the standard tags to be used across the organization. This policy should specify tag names, allowed values, and required tags for different resource types.
- Standardize Tag Names and Values: Maintain consistency in tag names and values to facilitate accurate reporting and analysis. Use a controlled vocabulary and avoid variations in spelling or capitalization.
- Automate Tagging: Implement automation to apply tags automatically during resource creation. This can be achieved through infrastructure-as-code (IaC) tools, such as Terraform or AWS CloudFormation, or by using scripting and automation tools.
- Enforce Tagging: Enforce tagging compliance to ensure that all resources are tagged correctly. This can be achieved through the use of cost management tools or by creating custom scripts that check for missing or incorrect tags.
- Regularly Review and Update Tags: Periodically review and update tags to ensure they remain relevant and accurate. This includes updating tag values as projects evolve and applications are modified.
- Use Tags for Access Control: Utilize tags to control access to resources. For example, you can create IAM policies that grant access to resources based on their tags.
Designing a Tagging System to Identify Cost Centers
Designing a tagging system to identify cost centers within an organization is crucial for allocating cloud costs accurately and assigning responsibility. A well-designed tagging system should capture the relevant organizational structure and provide visibility into spending patterns.Consider the following tagging system, incorporating the following tags:
- CostCenter: Identifies the organizational unit responsible for the cost (e.g., “Marketing”, “Engineering”, “Sales”).
- Project: Identifies the specific project or initiative associated with the cost (e.g., “WebsiteRedesign”, “MobileAppDevelopment”).
- Environment: Specifies the environment where the resources are deployed (e.g., “Development”, “Staging”, “Production”).
- Application: Identifies the application or service consuming the resources (e.g., “WebApp”, “APIGateway”).
- Owner: Identifies the individual or team responsible for the resource.
By implementing this tagging system, an organization can generate detailed cost reports that allocate expenses to specific cost centers. For instance, a report could show the total cost incurred by the “Marketing” cost center for the “WebsiteRedesign” project in the “Production” environment, broken down by application. This level of detail allows cost center managers to understand their spending patterns, identify areas for optimization, and make informed decisions about resource allocation.
Advantages of Using Tags for Cross-Functional Team Expense Management
Utilizing tags for cross-functional team expense management offers significant advantages in terms of cost allocation, accountability, and collaboration. This approach enables organizations to gain a comprehensive understanding of cloud spending across different teams and projects.
- Improved Cost Allocation: Tags enable accurate allocation of cloud costs to specific teams, projects, or applications, providing a clear picture of spending patterns.
- Enhanced Accountability: By associating costs with specific teams and individuals, tags promote accountability and encourage responsible resource usage.
- Better Collaboration: Tags facilitate collaboration between teams by providing a common language for discussing and managing cloud costs.
- Simplified Budgeting and Forecasting: Tags enable organizations to forecast cloud spending more accurately by tracking costs associated with specific projects and initiatives.
- Increased Cost Awareness: Tags increase cost awareness across the organization, encouraging teams to optimize resource usage and reduce unnecessary spending.
- Faster Issue Resolution: When cost issues arise, tags help quickly identify the responsible team or project, accelerating the resolution process.
For example, a company might have a cross-functional team working on a new mobile application. By using tags to track the costs associated with this project, the team can monitor spending, identify potential cost overruns, and make adjustments as needed. This collaborative approach to cost management fosters transparency, improves communication, and ensures that cloud resources are used efficiently.
AWS Services and Cost Management
Effective cost management is paramount for optimizing serverless application performance and financial efficiency. Understanding the cost drivers within various AWS serverless services allows for informed decision-making, resource allocation optimization, and proactive mitigation of potential cost overruns. This section delves into the cost implications of specific AWS services, focusing on how to track and manage expenses using tagging and other cost-optimization strategies.
AWS Lambda Cost Contributors
AWS Lambda functions contribute to serverless expenses primarily through invocation duration, memory allocation, and the number of invocations. These factors directly impact the cost incurred.The cost of a Lambda function is calculated using the following formula:
Cost = (Number of Requests
- Request Price) + (Duration in Milliseconds
- Price per GB-Second)
- GB-Memory
* Invocation Duration: The time your code runs, measured in milliseconds. Longer durations lead to higher costs.
Memory Allocation
The amount of RAM allocated to your function. Increasing memory can improve performance but also increases cost.
Number of Invocations
Each time your function is triggered, it counts as an invocation, incurring a cost.For example, consider a Lambda function configured with 128MB of memory that runs for 500 milliseconds and is invoked 10,000 times per month. Assuming a price of $0.000000002083 per GB-second and $0.0000002 per request (prices vary by region), the approximate monthly cost can be calculated. This example assumes prices for the US East (N.
Virginia) region.
Request Cost = 10,000 – $0.0000002 = $0.002Duration Cost = (500 / 1000)
- (128 / 1024)
- $0.000000002083 = $0.00001302
Total Cost = $0.002 + $0.00001302 = $0.00201302
Therefore, the total monthly cost for this function would be approximately $0.002. This simple example illustrates the interplay of invocation duration, memory allocation, and the number of invocations in determining Lambda costs. Optimizing code for efficiency (reducing duration), choosing the right memory size, and minimizing unnecessary invocations are critical for cost control.
AWS API Gateway Cost Calculation
AWS API Gateway costs are determined by the number of API calls, data transfer, and the caching configuration. API Gateway supports various pricing models, including pay-per-use and provisioned capacity, each impacting the overall cost structure.API Gateway costs are influenced by several factors:* Number of API Calls: The primary cost driver. Each API request, regardless of its success or failure, incurs a cost.
Data Transfer
Data transferred out of API Gateway to the client is charged.
Caching
Enabling caching reduces latency and the load on backend services but adds to the overall cost. The price depends on the cache size and region.
API Gateway Pricing Tiers
There are different pricing tiers for API Gateway, including pay-per-request and provisioned capacity. The pricing varies based on the selected tier.For instance, if an API receives 1 million requests per month and transfers 10GB of data, the cost can be estimated. Using the pay-per-request pricing model in the US East (N. Virginia) region, the cost would be approximately $3.50 per million requests and $0.09 per GB of data transfer.
Request Cost = 1,000,000 – $0.0000035 = $3.50Data Transfer Cost = 10 – $0.09 = $0.90Total Cost = $3.50 + $0.90 = $4.40
The total monthly cost for this API would be around $4.40. Provisioned capacity pricing allows you to pay for a fixed amount of API calls per month, providing more predictable costs. The choice between pay-per-request and provisioned capacity depends on the API’s traffic patterns and the need for cost predictability.
AWS Fargate Expense Tracking
Tracking expenses with AWS Fargate involves monitoring the vCPU and memory resources consumed by containerized applications. Detailed cost analysis can be achieved by utilizing AWS Cost Explorer and AWS Budgets.Fargate costs are primarily determined by the following factors:* vCPU and Memory Allocation: The resources allocated to each task directly impact the cost. Higher resource allocations lead to higher costs.
Task Duration
The time a task runs, from start to finish, is a key cost factor. Longer task durations result in increased costs.
Operating System and Region
The operating system and the AWS region where the task is running influence the pricing.
Storage
The storage used by the containers also incurs costs.AWS Cost Explorer and AWS Budgets can be used to monitor and analyze Fargate costs. Creating custom cost dashboards and setting up budget alerts can help you to stay within your desired spending limits. Applying tags to Fargate tasks enables you to allocate costs to specific projects or teams, facilitating granular cost analysis.For example, imagine an application running on Fargate, consuming 1 vCPU and 2GB of memory, with a task duration of 1 hour.
Assuming a price of $0.04048 per vCPU-hour and $0.004445 per GB-hour in the US East (N. Virginia) region, the approximate cost can be calculated.
vCPU Cost = 1 – $0.04048 = $0.04048Memory Cost = 2 – $0.004445 = $0.00889Total Cost = $0.04048 + $0.00889 = $0.04937
The total cost for this single task would be around $0.04937 per hour. Regularly reviewing resource utilization and optimizing container configurations can lead to significant cost savings.
AWS DynamoDB Cost Management and Tagging
Managing AWS DynamoDB costs involves optimizing provisioned capacity, leveraging on-demand capacity mode, and utilizing tagging for detailed cost allocation. Tagging enables you to categorize and track costs associated with specific DynamoDB tables or applications.DynamoDB costs are influenced by several factors:* Provisioned Capacity: The read and write capacity units (RCUs and WCUs) provisioned for your tables. Over-provisioning leads to unnecessary costs.
On-Demand Capacity Mode
This mode allows you to pay only for the reads and writes you perform, eliminating the need to manage capacity.
Storage
The amount of data stored in your DynamoDB tables impacts the cost.
Data Transfer
Data transferred out of DynamoDB is charged.Tagging DynamoDB resources, such as tables and indexes, allows you to categorize costs. For instance, you can tag tables by application, environment (e.g., production, staging), or team. This enables you to:* Allocate Costs: Identify which projects or teams are responsible for specific DynamoDB expenses.
Track Usage
Monitor the consumption of resources by different applications or environments.
Optimize Spending
Identify tables or applications with high costs and optimize their configurations.For example, if a DynamoDB table is tagged with the key `Application` and the value `OrderProcessing`, all costs associated with that table will be attributed to the OrderProcessing application. This facilitates the analysis of cost trends, identifying cost-saving opportunities, and accurate budgeting. Using the AWS Cost Explorer, you can filter costs by tags to view the expenses for each tagged resource.
Comparison of Serverless Service Cost Implications
Comparing the cost implications of different AWS serverless services helps in selecting the most cost-effective solution for a given workload. Each service has unique cost drivers and pricing models, making direct comparisons necessary for optimal cost management.The cost implications of different AWS serverless services can be compared based on several factors:* Pricing Models: Pay-per-use (Lambda, API Gateway) versus provisioned capacity (DynamoDB, Fargate).
Cost Drivers
Invocation duration and memory (Lambda), API calls and data transfer (API Gateway), vCPU/memory and task duration (Fargate), read/write capacity and storage (DynamoDB).
Scalability
How well the service scales to handle varying workloads.
Performance
The impact of resource allocation on performance.For example, if an application requires a highly scalable, event-driven architecture, AWS Lambda might be a cost-effective choice, given its pay-per-use model. However, if the application involves complex containerized workloads with specific resource requirements, AWS Fargate might be more suitable, despite the need to manage container configurations.A comparative table:
| Service | Cost Drivers | Pricing Model | Scalability | Use Cases |
|---|---|---|---|---|
| AWS Lambda | Invocation Duration, Memory, Number of Invocations | Pay-per-use | Highly Scalable | Event-driven applications, API backends |
| AWS API Gateway | Number of API Calls, Data Transfer, Caching | Pay-per-use, Provisioned Capacity | Highly Scalable | API management, microservices |
| AWS Fargate | vCPU, Memory, Task Duration | Pay-per-use | Scalable | Containerized applications, batch processing |
| AWS DynamoDB | Provisioned Capacity, Storage, Data Transfer | Provisioned Capacity, On-Demand | Highly Scalable | NoSQL database, session management |
The choice of service should align with the application’s requirements and the team’s cost-optimization strategy. Regular monitoring and analysis of resource utilization and costs are essential for maintaining cost-effectiveness.
Azure Services and Cost Management
Understanding and managing costs is crucial for efficiently operating serverless applications on Azure. Azure provides a suite of services for serverless computing, each with its own pricing model and cost implications. Effective cost management involves a combination of understanding these models, utilizing tagging for resource allocation, and leveraging Azure’s cost management tools. This section will delve into the pricing structures of key Azure serverless services and how to analyze their associated costs.
Pricing Models for Azure Functions
Azure Functions, the serverless compute service on Azure, offers various pricing plans tailored to different workload requirements. These plans influence how costs are incurred and how they can be optimized.
- Consumption Plan: This is the default and most cost-effective option for many workloads. Pricing is based on the number of executions, execution time (measured in gigabyte-seconds), and memory consumption. There’s a free grant of 400,000 GB-s of execution time and 1 million executions per month. Costs are incurred only when the function is running, making it ideal for event-driven applications with infrequent or unpredictable traffic.
For example, a function that processes a file upload might only run a few times a day, making the Consumption Plan cost-effective.
- Premium Plan: The Premium plan offers enhanced performance and features compared to the Consumption plan, including pre-warmed instances and VNet integration. It provides a more consistent performance profile and can be used for scenarios that require predictable performance. The pricing is based on the number of allocated compute instances and execution time. It’s charged for the resources reserved, even when the function is idle.
This plan is beneficial when a function needs to respond quickly and consistently, such as for web applications or APIs.
- Dedicated (App Service) Plan: Functions can also be deployed on an App Service plan, which provides dedicated virtual machines. This plan offers more control over the underlying infrastructure and is suitable for functions with high and consistent workloads. The pricing depends on the size of the virtual machine and the instance count. It provides predictable pricing but can be more expensive if the function is not utilized consistently.
Monitoring Azure API Management Costs
Azure API Management (APIM) facilitates the creation, publication, and management of APIs. Monitoring its costs involves understanding the different pricing tiers and the usage patterns.
- Tier-Based Pricing: APIM offers various tiers, including Consumption, Developer, Basic, Standard, and Premium. Each tier has different features, capacity limits, and pricing structures. The Consumption tier is pay-per-use and is suitable for testing and development or low-volume APIs. Other tiers have fixed monthly costs plus variable charges based on usage. The choice of tier significantly impacts costs.
- Usage Metrics: APIM provides detailed metrics on API usage, including the number of API calls, data transfer, and caching usage. These metrics are essential for understanding cost drivers. Analyzing these metrics helps to identify the APIs or operations that consume the most resources.
- Cost Analysis Tools: Azure Cost Management + Billing allows for detailed cost analysis, enabling the breakdown of APIM costs by different dimensions, such as resource group, API name, or API operation. This allows for pinpointing the cost of specific API usage.
- Tagging Strategies: Tags can be applied to APIM instances and associated resources, such as API operations or products, to categorize costs and facilitate cost allocation. This allows for better tracking and reporting on the cost of specific API features or business units. For example, using tags, you can track the cost of APIs used by a specific product.
Using Tags for Azure Logic Apps Cost Analysis
Azure Logic Apps is a cloud service that helps you schedule, automate, and orchestrate tasks, business processes, and workflows when you need to integrate apps, data, systems, and services across enterprises or organizations. Tagging is a crucial component of effective cost management.
- Tagging Logic Apps: Apply tags to each Logic App instance to categorize and group them logically. Common tags include:
- `Environment`: (e.g., Production, Development, Staging)
- `Application`: (e.g., OrderProcessing, UserAuthentication)
- `Department`: (e.g., Sales, Marketing, Finance)
- `CostCenter`: (e.g., CC-1234)
- Tagging Related Resources: Tagging resources associated with Logic Apps, such as storage accounts, service bus namespaces, and connectors, provides a comprehensive view of the overall costs. This approach ensures that all the components contributing to the cost are appropriately categorized.
- Cost Analysis with Tags:
- Use Azure Cost Management + Billing to filter and group costs based on tags.
- Analyze the cost of Logic Apps based on different dimensions, such as application, environment, or cost center.
- Identify cost drivers and trends, such as which Logic Apps are the most expensive.
- Example:
Imagine a company uses Logic Apps for order processing. They tag the Logic App with `Application: OrderProcessing`, `Environment: Production`, and `Department: Sales`. Using Azure Cost Management, they can view the exact cost of order processing in production, attributing the costs to the sales department.
Analyzing Azure Cosmos DB Expenses with Tags
Azure Cosmos DB is a fully managed NoSQL database service for modern app development. Understanding and managing its costs are essential for optimizing serverless applications that utilize Cosmos DB.
- Tagging Cosmos DB Accounts: Apply tags to Cosmos DB accounts to categorize and track costs effectively. Recommended tags include:
- `Application`: (e.g., CustomerData, ProductCatalog)
- `Environment`: (e.g., Production, Test)
- `Team`: (e.g., DatabaseTeam, FrontendTeam)
- `Project`: (e.g., ProjectX, ProjectY)
- Cost Breakdown: Cosmos DB costs are primarily driven by provisioned throughput (RU/s), storage consumed, and data transfer. Analyzing these costs using tags is vital.
- Cost Management Tools:
- Use Azure Cost Management + Billing to view costs associated with Cosmos DB.
- Filter costs by tags to analyze expenses by application, environment, or team.
- Identify cost trends and anomalies.
- Example: A company uses Cosmos DB to store customer data. By tagging the Cosmos DB account with `Application: CustomerData` and `Environment: Production`, they can see the exact cost of storing and processing customer data in the production environment.
- Optimization:
- Regularly review provisioned throughput and adjust it based on actual needs.
- Monitor storage consumption and optimize data models for efficiency.
- Consider using reserved capacity for predictable workloads to reduce costs.
Comparison of Azure Serverless Services and Their Cost Implications
Azure offers a range of serverless services, each with unique pricing models and cost implications. Understanding these differences is essential for choosing the right service for a specific use case and for optimizing costs.
| Service | Pricing Model | Key Cost Drivers | Cost Implications | Use Cases |
|---|---|---|---|---|
| Azure Functions | Consumption, Premium, Dedicated | Executions, execution time, memory, compute instance allocation | Consumption is cost-effective for infrequent workloads; Premium and Dedicated provide more control but may be more expensive. | Event-driven processing, web APIs, scheduled tasks |
| Azure API Management | Consumption, Developer, Basic, Standard, Premium | API calls, data transfer, caching | Consumption is pay-per-use; higher tiers have fixed costs plus variable charges. | API gateway, API publishing, API management |
| Azure Logic Apps | Pay-per-use | Workflow executions, connectors used | Costs depend on the complexity and frequency of workflows; connectors can add to the cost. | Workflow automation, integration, business process automation |
| Azure Cosmos DB | Provisioned throughput (RU/s), storage, data transfer | Provisioned throughput, storage consumed | Costs depend on the provisioned throughput, storage used, and data transfer. Optimizing throughput and storage is crucial. | NoSQL database, modern app development, high-performance applications |
Google Cloud Platform and Cost Management

Google Cloud Platform (GCP) offers a suite of serverless services, each with its own pricing model and cost management considerations. Effective cost management in GCP serverless environments requires a deep understanding of service-specific pricing, resource consumption, and the strategic application of tagging. This section will explore the cost structures of key serverless offerings, provide practical examples of cost tracking, and demonstrate how to leverage tagging for granular cost allocation and optimization.
Pricing Structure of Google Cloud Functions
Google Cloud Functions employs a pay-per-use pricing model, meaning you are charged only for the resources your function consumes. The cost is determined by several factors.
- Invocation Count: The number of times your function is executed. This is the most straightforward cost component.
- Compute Time: The time your function runs, measured in gigabyte-seconds (GB-seconds) and CPU-seconds. This accounts for the resources used during execution.
- Memory Allocation: The amount of memory allocated to your function. More memory can improve performance but increases costs.
- Network Egress: Data transferred out of your function, incurring charges based on the destination and data volume.
- Storage: If your function uses Cloud Storage, you’ll be charged for storage and operations.
The pricing is tiered, with lower rates for higher usage. For instance, the first free tier allows a certain number of invocations, compute time, and egress data each month. Exceeding these free tiers results in charges based on the pricing tiers. Understanding these tiers and monitoring usage is crucial for cost optimization.For example, consider a function processing image uploads. The cost would depend on the number of images processed (invocation count), the time taken to process each image (compute time and memory allocation), the size of the images (network egress if stored elsewhere), and storage costs if the images are saved in Cloud Storage.
Optimizing image processing code for efficiency (e.g., using optimized libraries, resizing images) can directly reduce compute time and, consequently, costs.
Cost = (Invocation Count
– Invocation Rate) + (Compute Time
– Compute Rate) + (Memory Allocation
– Memory Rate) + (Network Egress
– Network Rate) + (Storage
– Storage Rate)
Tracking Expenses for Google Cloud Run
Google Cloud Run, a fully managed compute platform, provides a different cost model compared to Cloud Functions. Tracking expenses for Cloud Run involves monitoring several key metrics.
- CPU Usage: The amount of CPU cores allocated and used by your container instances.
- Memory Usage: The amount of memory allocated and used by your container instances.
- Requests: The number of incoming requests served by your container instances.
- Network Egress: The data transferred out of your container instances.
GCP provides several tools to monitor these metrics.
- Cloud Monitoring: This service allows you to create dashboards and alerts based on various metrics. You can track CPU and memory utilization, request counts, and network egress. Create custom metrics if needed.
- Cloud Billing: Cloud Billing provides detailed cost breakdowns, including costs associated with Cloud Run. You can filter costs by project, service, and other criteria to understand spending patterns.
- Cloud Logging: Logs generated by your Cloud Run instances can be analyzed to identify performance bottlenecks or inefficient resource usage. Logging also provides insights into request patterns and error rates.
For example, suppose you deploy a web application on Cloud Run. By monitoring CPU and memory utilization, you can determine if you are over-provisioning resources, leading to unnecessary costs. If CPU utilization is consistently low, you might scale down the number of instances or reduce the CPU allocation per instance. Conversely, if CPU utilization is consistently high, you might need to scale up the number of instances or increase CPU allocation.
Similarly, monitoring request counts can help you understand traffic patterns and scale your application accordingly.
Analyzing Google Cloud API Gateway Costs
Google Cloud API Gateway provides a managed service for creating, publishing, and managing APIs. Analyzing its costs requires understanding its pricing model and leveraging GCP’s cost management tools.
- Request Volume: The primary cost driver is the number of requests processed by the API Gateway. Pricing is based on the number of requests.
- Data Transfer: Data transferred out of the API Gateway incurs charges based on the data volume.
- Service Integration: The cost of the backend services integrated with the API Gateway (e.g., Cloud Functions, Cloud Run) contributes to the overall cost.
GCP offers tools for analyzing API Gateway costs.
- Cloud Billing: Use Cloud Billing to track costs associated with API Gateway. Filter by service and project to isolate API Gateway expenses.
- Cloud Monitoring: Create dashboards to monitor request volume, latency, and error rates. Set up alerts to notify you of unexpected spikes in traffic or errors that could indicate performance issues.
- API Gateway Metrics: API Gateway provides built-in metrics like request count, latency, and error rate. These metrics can be used to identify performance bottlenecks and optimize API usage.
For example, consider an API Gateway managing requests to a Cloud Function. Monitoring the request count to the API Gateway can help you understand API usage patterns. High request volumes can increase costs. Analyzing the latency of requests can help you identify performance bottlenecks in either the API Gateway or the backend service (Cloud Function). If the backend service is slow, the API Gateway will experience increased latency.
Optimizing the backend service can reduce latency and improve the user experience.
Using Tags for Monitoring Google Cloud Datastore Expenses
Google Cloud Datastore, a NoSQL document database, allows you to store and manage data for your serverless applications. Tagging is a powerful technique for allocating Datastore costs accurately.
- Entity Storage: Charges are based on the amount of data stored in Datastore.
- Read Operations: Charges are applied for each read operation performed.
- Write Operations: Charges are applied for each write operation performed.
- Network Egress: Data transferred out of Datastore incurs charges.
Tags can be used to group resources based on various criteria.
- Application: Tag resources by application name (e.g., “ecommerce-app,” “blog-platform”) to track the cost of each application.
- Environment: Tag resources by environment (e.g., “development,” “staging,” “production”) to isolate costs for different environments.
- Team: Tag resources by the team responsible for the application to facilitate cost accountability.
To implement tagging, follow these steps.
- Define Tagging Strategy: Determine the tagging scheme (e.g., key-value pairs) that best aligns with your cost allocation requirements.
- Apply Tags to Resources: When creating Datastore instances or related resources (e.g., Cloud Functions accessing Datastore), apply the appropriate tags. This can be done through the Google Cloud Console, the gcloud CLI, or infrastructure-as-code tools like Terraform.
- Use Cloud Billing Reports: In Cloud Billing, filter and group costs by tags to analyze expenses. You can create custom dashboards to visualize cost breakdowns by tag.
For example, if you have an e-commerce application using Datastore, you could tag Datastore resources with the key “application” and the value “ecommerce-app.” You could then use Cloud Billing to filter costs by this tag, allowing you to see the exact cost of running Datastore for your e-commerce application. This level of granularity allows for accurate cost allocation and helps identify areas for optimization.
Comparing Cost Management Strategies Across Different Google Cloud Serverless Offerings
Different serverless offerings on Google Cloud necessitate distinct cost management strategies. The optimal approach depends on the service’s pricing model and the application’s characteristics.
- Cloud Functions: The pay-per-use model of Cloud Functions emphasizes optimizing function execution time, memory allocation, and network egress. Regularly review function logs to identify performance bottlenecks.
- Cloud Run: Cloud Run’s resource-based pricing necessitates optimizing CPU and memory allocation, and scaling the number of instances to meet demand. Monitor CPU and memory utilization.
- API Gateway: Cost management for API Gateway focuses on monitoring request volume and optimizing backend service performance to reduce latency. Regularly analyze API usage patterns.
- Cloud Datastore: Datastore cost management involves optimizing data storage, read/write operations, and network egress. Implement efficient data modeling and indexing.
A common thread across all services is the importance of monitoring, tagging, and automated scaling.
- Monitoring: Use Cloud Monitoring to track key metrics (CPU, memory, request volume, latency) for each service.
- Tagging: Apply tags to resources to allocate costs accurately and identify cost drivers.
- Automated Scaling: Implement autoscaling to dynamically adjust resources based on demand. This can prevent over-provisioning and reduce costs.
For instance, consider a scenario where a single application utilizes Cloud Functions, Cloud Run, and API Gateway. You could use Cloud Billing and Cloud Monitoring to visualize costs for each service, and then use tags to break down the cost by application, environment, and team. By combining these techniques, you can gain a comprehensive understanding of your serverless costs and make informed decisions about resource allocation and optimization.
Setting up Cost Tracking and Monitoring
Effective cost tracking and monitoring are crucial for maintaining control over serverless application expenditures. This involves establishing dashboards for real-time insights, generating customized reports for detailed analysis, implementing alerts to proactively address anomalies, automating data export for comprehensive review, and visualizing cost data to facilitate understanding and informed decision-making. These steps collectively provide the visibility and control needed to optimize serverless spending.
Enabling Cost Monitoring Dashboards
Enabling cost monitoring dashboards provides a centralized view of serverless application expenses. These dashboards display real-time cost data, allowing for immediate identification of spending trends and potential issues.To enable cost monitoring dashboards, consider the following:
- Cloud Provider’s Native Tools: Utilize the built-in cost management tools provided by the cloud provider (AWS Cost Explorer, Azure Cost Management + Billing, Google Cloud Cost Management). These tools offer pre-built dashboards and visualizations. For instance, AWS Cost Explorer allows filtering and grouping costs by tags, service, and other dimensions.
- Third-Party Tools: Explore third-party cost management platforms that offer enhanced features and integrations. These platforms often provide more advanced analytics, customizable dashboards, and multi-cloud support. Examples include CloudHealth by VMware, and Apptio Cloudability.
- Dashboard Configuration: Configure the dashboards to display relevant metrics, such as total cost, cost by service, cost by tag, and cost over time. Customize the date ranges and granularity (daily, weekly, monthly) to meet specific monitoring needs.
- Access Control: Implement appropriate access control to restrict dashboard access to authorized personnel only. Ensure that sensitive cost data is protected from unauthorized viewing.
- Alert Integration: Integrate dashboards with alerting systems to proactively notify stakeholders of cost anomalies or budget overruns. For example, set up alerts in AWS Cost Explorer to trigger notifications when costs exceed a predefined threshold.
Creating Custom Cost Reports
Creating custom cost reports allows for a more granular analysis of serverless application costs. These reports can be tailored to specific business requirements, providing detailed insights into spending patterns and cost drivers.To create custom cost reports, the following steps can be employed:
- Data Source Selection: Identify the data sources for the cost reports. This typically includes cost and usage data provided by the cloud provider (e.g., AWS Cost and Usage Report, Azure Cost Management data export, Google Cloud Billing export).
- Data Transformation: Prepare the data for reporting by transforming and cleaning the data. This may involve aggregating data, filtering data based on specific criteria (e.g., tags, services), and calculating derived metrics. For example, aggregate costs by tag and service.
- Reporting Tools: Select appropriate reporting tools. This can include:
- Cloud Provider’s Reporting Tools: Utilize built-in reporting capabilities provided by the cloud provider.
- Spreadsheet Software: Use spreadsheet software like Microsoft Excel or Google Sheets for basic reporting and analysis.
- Business Intelligence (BI) Tools: Leverage BI tools like Tableau, Power BI, or Looker for advanced reporting and visualization. These tools can connect to various data sources and provide interactive dashboards.
- Report Design: Design the report structure, including the data to be displayed, the visualizations to be used, and the layout of the report. Focus on presenting the data in a clear and concise manner.
- Report Scheduling and Distribution: Schedule the report generation and distribution to relevant stakeholders. Automate the report delivery to ensure timely access to cost information.
Creating a Checklist for Setting up Cost Alerts and Notifications
Implementing cost alerts and notifications is a proactive approach to managing serverless application costs. This allows for immediate notification of potential cost issues, enabling timely intervention and preventing unexpected expenses.The checklist for setting up cost alerts and notifications should include the following:
- Define Alerting Thresholds: Establish clear alerting thresholds based on budget limits, historical spending patterns, and business requirements. These thresholds should trigger notifications when costs exceed a predefined amount or percentage.
- Configure Alerting Rules: Configure the alerting rules within the cloud provider’s cost management tools or third-party platforms. Specify the conditions that trigger alerts (e.g., exceeding a daily budget, a sudden increase in cost).
- Specify Notification Channels: Define the notification channels for alerts, such as email, Slack, or other communication platforms. Ensure that the appropriate stakeholders receive the alerts in a timely manner.
- Customize Alert Content: Customize the alert content to include relevant information, such as the service or resource incurring the cost, the amount of the cost, and the time period. Include links to the cost management dashboards for further investigation.
- Test Alerts: Thoroughly test the alerts to ensure that they are functioning correctly and that notifications are being delivered as expected.
- Monitor Alert Performance: Regularly monitor the performance of the alerting system to ensure that it is effectively identifying cost anomalies and providing timely notifications.
- Documentation: Document the alert configuration, including the alerting thresholds, notification channels, and contact information for the responsible parties.
Designing a System to Automate Cost Data Export for Analysis
Automating cost data export streamlines the process of analyzing serverless application costs. This ensures that cost data is readily available for detailed analysis, reporting, and integration with other business systems.To design a system for automated cost data export, consider the following:
- Data Source Selection: Identify the data source for the cost data. This typically includes the cloud provider’s cost and usage data (e.g., AWS Cost and Usage Report, Azure Cost Management data export, Google Cloud Billing export).
- Export Format: Choose the appropriate export format, such as CSV, JSON, or Parquet. The format should be compatible with the analysis tools being used.
- Storage Location: Select a storage location for the exported data, such as a cloud storage service (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage), a data warehouse (e.g., AWS Redshift, Azure Synapse Analytics, Google BigQuery), or a database.
- Automation Mechanism: Implement an automation mechanism to export the cost data on a regular schedule. This can involve:
- Cloud Provider’s Native Tools: Utilize the built-in data export features provided by the cloud provider.
- Custom Scripts: Develop custom scripts using scripting languages like Python or Bash to automate the data export process.
- Workflow Automation Tools: Leverage workflow automation tools like AWS Step Functions, Azure Logic Apps, or Google Cloud Workflows to orchestrate the data export process.
- Data Transformation and Processing: Transform and process the exported data as needed. This may involve cleaning the data, aggregating data, and enriching the data with additional information (e.g., tags, metadata).
- Data Integration: Integrate the exported data with other business systems, such as BI tools, data warehouses, or custom applications.
- Monitoring and Logging: Implement monitoring and logging to track the data export process. Monitor for errors and ensure that the data is being exported successfully.
Organizing a Presentation on Visualizing Serverless Application Costs
Presenting serverless application cost data effectively requires careful organization and visualization techniques. A well-structured presentation helps communicate cost insights clearly and concisely to stakeholders.To organize a presentation on visualizing serverless application costs, consider the following structure and elements:
- Introduction: Start with a brief overview of serverless computing and its cost implications. Define the objectives of the presentation and the target audience.
- Data Sources and Methodology: Describe the data sources used for the analysis (e.g., AWS Cost Explorer, Azure Cost Management, Google Cloud Cost Management) and the methodology employed for data collection and analysis. Explain any assumptions or limitations.
- Cost Breakdown: Present a breakdown of serverless application costs, categorized by service, tag, or other relevant dimensions. Use visualizations such as:
- Bar Charts: To compare costs across different services or tags.
- Line Charts: To show cost trends over time.
- Pie Charts: To illustrate the proportion of costs allocated to different components.
- Heatmaps: To visualize cost patterns across multiple dimensions (e.g., service and region).
- Cost Drivers: Identify the key drivers of serverless application costs. This may include:
- Service Usage: The amount of time a service is used.
- Resource Consumption: The amount of resources consumed by a service.
- Request Volume: The number of requests processed by a service.
- Cost Optimization Strategies: Present strategies for optimizing serverless application costs. This may include:
- Right-sizing resources: Adjusting the resources allocated to services to match the actual workload.
- Using reserved instances or committed use discounts: Taking advantage of discounts offered by cloud providers for long-term usage commitments.
- Optimizing code: Improving the efficiency of code to reduce resource consumption.
- Implementing auto-scaling: Automatically scaling resources up or down based on demand.
- Actionable Insights and Recommendations: Provide actionable insights and recommendations based on the cost analysis. This may include identifying areas for cost reduction, recommending specific optimization strategies, and suggesting improvements to the cost monitoring process.
- Conclusion: Summarize the key findings of the presentation and reiterate the importance of cost management for serverless applications.
- Q&A: Allow time for questions and answers from the audience.
- Visual Aids: Utilize clear and concise visualizations to present the data. Ensure that the visualizations are easy to understand and that the key insights are highlighted.
- Presentation Tools: Use presentation tools such as PowerPoint, Google Slides, or Keynote to create the presentation.
Analyzing Cost Data with Reports and Dashboards
Interpreting cost data and visualizing it effectively are critical for understanding and managing serverless application expenses. Cloud providers offer a variety of reporting and dashboarding tools that enable detailed cost analysis, anomaly detection, and proactive cost optimization. This section delves into the practical aspects of utilizing these tools to gain valuable insights into serverless cost behavior.
Interpreting Cost Reports
Cost reports from cloud providers offer a granular view of resource consumption and associated costs. Understanding how to navigate and interpret these reports is fundamental to effective cost management.
- Report Structure: Cost reports are typically organized by service, region, and resource. Each row usually represents a specific resource instance or a combination thereof, with columns detailing usage metrics (e.g., requests, compute time, data transfer) and the corresponding cost. Reports may also include information on tags, allowing for cost allocation based on projects, departments, or other custom dimensions.
- Key Metrics: Familiarize yourself with the core metrics relevant to serverless cost analysis. These include:
- Requests: The number of invocations for functions or API calls.
- Compute Time/Duration: The amount of time your code is actively running (e.g., function execution time).
- Memory Consumption: The amount of memory allocated to your serverless functions.
- Data Transfer: The amount of data transferred in and out of your services (e.g., network traffic).
- Storage Usage: The amount of storage used by your services (e.g., object storage).
- Filtering and Grouping: Most cost reports provide filtering and grouping capabilities. Use these features to focus on specific services, regions, or tagged resources. Grouping by tag is particularly useful for understanding the cost contribution of different projects or teams.
- Cost Breakdown: Analyze the cost breakdown for each service to identify the largest cost drivers. This involves examining the usage metrics associated with each cost component to understand which activities are consuming the most resources and driving up costs.
- Date Range and Granularity: Select appropriate date ranges and granularity (e.g., daily, hourly) to analyze trends and identify patterns. Shorter timeframes provide more detailed insights into short-term fluctuations, while longer timeframes reveal long-term trends.
Visualizing Cost Data with Dashboards
Dashboards transform raw cost data into interactive visualizations, making it easier to identify trends, anomalies, and areas for optimization. Cloud providers offer built-in dashboarding tools, and third-party solutions provide more advanced features.
- Common Visualization Types: Effective dashboards employ a variety of visualization types:
- Line Charts: Track cost trends over time, highlighting periods of high or low spending.
- Bar Charts: Compare costs across different services, regions, or tagged resources.
- Pie Charts: Show the proportion of cost attributed to different cost components or resource types.
- Heatmaps: Visualize cost data across multiple dimensions (e.g., service, region, date) to identify patterns.
- Dashboard Components: A well-designed cost dashboard typically includes the following components:
- Cost Overview: A summary of total costs and key metrics (e.g., cost per day, cost per service).
- Trend Charts: Line charts showing cost trends over time, with options to filter by service or tag.
- Breakdown Charts: Bar or pie charts illustrating the cost distribution across different dimensions.
- Alerting: Configurable alerts that notify you when costs exceed predefined thresholds.
- Custom Dashboards: Cloud providers allow you to create custom dashboards tailored to your specific needs. This allows you to focus on the metrics and dimensions that are most relevant to your serverless applications.
- Examples of Dashboard Use Cases:
- Project-Based Cost Tracking: Create a dashboard to monitor the cost of each project by filtering the data by project tags.
- Service-Specific Cost Analysis: Build a dashboard to track the cost of a specific serverless service (e.g., AWS Lambda, Azure Functions, Google Cloud Functions), showing its compute time, requests, and data transfer costs over time.
- Anomaly Detection: Use dashboards to visually identify cost anomalies, such as unexpected spikes in function invocations or data transfer.
Identifying Cost Anomalies in Reports
Detecting cost anomalies is crucial for preventing unexpected cost overruns and optimizing resource utilization.
- Baseline Establishment: Establish a baseline of expected costs based on historical data and application behavior. This involves analyzing past cost reports to understand normal spending patterns.
- Trend Analysis: Regularly review cost reports and dashboards to identify deviations from the baseline. Look for sudden spikes or dips in spending that are not explained by normal application activity.
- Alerting Systems: Configure cost alerts to notify you when costs exceed predefined thresholds or exhibit unusual behavior. Cloud providers offer various alerting mechanisms, such as email notifications or integration with monitoring tools.
- Anomaly Detection Tools: Some third-party cost management tools offer automated anomaly detection capabilities. These tools use machine learning algorithms to identify unusual cost patterns and flag them for investigation.
- Investigating Anomalies: When an anomaly is detected, investigate the root cause by:
- Examining Usage Metrics: Analyze the usage metrics associated with the anomaly (e.g., function invocations, compute time, data transfer) to understand what is driving the increased cost.
- Reviewing Application Logs: Examine application logs to identify any errors, performance issues, or unexpected behavior that may be contributing to the anomaly.
- Checking for Misconfigurations: Verify that your serverless resources are configured correctly and that there are no misconfigurations that could be leading to excessive resource consumption.
Drilling Down into Cost Data
Drilling down into cost data allows you to move from high-level summaries to granular details, providing a deeper understanding of cost drivers.
- Hierarchical Analysis: Use the filtering and grouping capabilities of cost reports and dashboards to analyze cost data at different levels of detail. Start with a broad overview and then drill down into specific services, regions, or tagged resources.
- Tag-Based Filtering: Leverage tags to filter cost data by project, environment, or other relevant dimensions. This allows you to isolate the costs associated with specific components of your serverless applications.
- Time-Based Analysis: Analyze cost data over different time periods (e.g., daily, hourly) to identify trends and patterns. This can help you pinpoint the exact times when costs are highest.
- Service-Specific Breakdown: Drill down into the cost breakdown for each serverless service to identify the specific resource components that are driving costs. For example, for AWS Lambda, you can drill down into compute time, memory consumption, and data transfer costs.
- Example Scenario: Suppose you observe an increase in AWS Lambda costs. To drill down, you might:
- Filter the cost report by the “Lambda” service.
- Group the data by “Function Name” to identify which functions are contributing the most to the cost increase.
- Analyze the metrics (e.g., duration, invocations) for the high-cost functions to understand the root cause.
- Review application logs for the high-cost functions to identify potential issues (e.g., inefficient code, excessive invocations).
Comparing Reporting Tools for Serverless Cost Data
Different reporting tools offer varying features and capabilities for analyzing serverless cost data. Selecting the right tool depends on your specific needs and budget.
- Cloud Provider Native Tools: AWS Cost Explorer, Azure Cost Management + Billing, and Google Cloud Cost Management are native tools offering basic cost reporting, dashboarding, and alerting features. They provide detailed cost data for their respective services and are generally free to use.
- Advantages: Tight integration with cloud services, access to detailed cost data, and cost-effective.
- Disadvantages: Limited cross-cloud support, potentially less advanced features compared to third-party tools.
- Third-Party Cost Management Tools: Tools like CloudHealth by VMware, Apptio, and others offer advanced cost optimization features, cross-cloud support, and enhanced reporting capabilities. They typically provide more sophisticated dashboards, anomaly detection, and cost optimization recommendations.
- Advantages: Advanced features, cross-cloud support, and enhanced automation.
- Disadvantages: Subscription fees, potential complexity.
- Open-Source Tools: Tools like Grafana, coupled with cost data sources, allow for customizable dashboards and visualizations.
- Advantages: Highly customizable, free to use, and can be integrated with various data sources.
- Disadvantages: Requires technical expertise to set up and maintain, and can have limited out-of-the-box functionality.
- Feature Comparison Table:
Feature Cloud Provider Native Tools Third-Party Cost Management Tools Open-Source Tools Cross-Cloud Support Limited Yes Yes (with integrations) Advanced Dashboards Basic Advanced Highly Customizable Anomaly Detection Basic Advanced Requires setup Cost Optimization Recommendations Limited Advanced Requires setup Pricing Free (usually) Subscription-based Free
Cost Optimization Strategies

Optimizing serverless application costs requires a multifaceted approach, encompassing code efficiency, resource allocation, and strategic utilization of caching mechanisms. This section Artikels practical strategies to reduce operational expenses by focusing on performance enhancements and resource management. The goal is to minimize waste and maximize the value derived from serverless infrastructure.
Optimizing Code for Reduced Execution Time
Code optimization is a crucial step in reducing serverless function costs. The duration of function execution directly correlates with the incurred expenses, as providers typically charge based on execution time and resource consumption. Therefore, writing efficient code is paramount.
- Profiling and Performance Analysis: Employ profiling tools specific to the chosen runtime environment (e.g., Python’s cProfile, Node.js’s –inspect) to identify performance bottlenecks within the code. This analysis helps pinpoint slow-running functions or sections that consume excessive resources.
- Algorithm and Data Structure Selection: Choose algorithms and data structures that offer optimal performance for the specific tasks. For example, using hash maps for lookups generally provides faster retrieval compared to linear searches in lists. Consider the time complexity (Big O notation) of algorithms when evaluating their efficiency.
- Code Minimization and Bundling: Reduce the size of the code by removing unnecessary comments, whitespace, and unused code blocks. For Node.js applications, tools like Webpack or Parcel can bundle the code and dependencies into a single, optimized file, which reduces cold start times and execution duration.
- Dependency Management: Minimize the number of external dependencies and ensure they are optimized. Avoid importing entire libraries when only a small subset of functionalities is required. Consider using lighter-weight alternatives or refactoring the code to avoid unnecessary dependencies.
- Asynchronous Operations: Utilize asynchronous operations (e.g., `async/await` in JavaScript, `threading` in Python) to prevent functions from blocking while waiting for I/O operations or network requests. This allows the function to handle other tasks concurrently, improving overall throughput and reducing execution time.
- Caching Results: Implement caching mechanisms for frequently accessed data or computationally intensive results. Caching can significantly reduce the number of executions needed, thereby decreasing costs.
Choosing the Right Instance Sizes for Serverless Functions
Selecting the appropriate instance size (memory allocation) for serverless functions is essential for balancing performance and cost. Over-provisioning memory results in unnecessary expenses, while under-provisioning can lead to performance degradation and increased execution time.
- Monitoring Resource Utilization: Continuously monitor the memory and CPU utilization of serverless functions. Cloud providers offer monitoring tools that provide insights into resource consumption. This data helps identify whether a function is consistently under-utilized or approaching its memory limits.
- Testing with Different Memory Configurations: Experiment with different memory configurations to determine the optimal setting for each function. Start with a baseline memory allocation and gradually increase or decrease it while monitoring performance metrics such as execution time and error rates.
- Consider CPU Allocation: Serverless platforms often allocate CPU proportionally to the allocated memory. Functions that require more CPU power, such as those performing complex calculations or image processing, may benefit from higher memory allocations.
- Leverage Auto-Scaling: Configure auto-scaling to automatically adjust the number of function instances based on demand. This ensures that sufficient resources are available during peak loads while minimizing costs during periods of low activity.
- Function-Specific Tuning: Tailor memory allocation to the specific requirements of each function. Functions that perform simple tasks may require less memory than those that handle complex operations or large datasets.
Using Caching to Minimize Costs
Caching is a powerful technique for reducing costs by storing frequently accessed data or results, thereby minimizing the number of function invocations and the associated expenses.
- Caching Data from External Sources: Cache data retrieved from external APIs or databases to reduce the number of requests made to these services. Implement a cache invalidation strategy to ensure that the cached data remains up-to-date.
- Caching Function Results: Cache the results of computationally intensive functions, especially those that process the same inputs repeatedly. This can significantly reduce execution time and resource consumption.
- Choosing a Caching Strategy: Select the appropriate caching strategy based on the specific requirements of the application. Options include:
- In-Memory Caching: Use in-memory caches (e.g., Redis, Memcached) for fast access to frequently accessed data.
- CDN Caching: Utilize a Content Delivery Network (CDN) to cache static assets, such as images and JavaScript files, closer to users, reducing latency and improving performance.
- Client-Side Caching: Implement client-side caching in web browsers to store static content, reducing the number of requests to the server.
- Cache Invalidation Strategies: Implement effective cache invalidation strategies to ensure data consistency. This includes:
- Time-Based Expiration: Set a time-to-live (TTL) for cached data, and invalidate the cache after the specified time.
- Event-Driven Invalidation: Trigger cache invalidation based on events, such as updates to the underlying data.
- Monitoring Cache Performance: Monitor the cache hit ratio and the cache size to optimize caching performance. A high hit ratio indicates that the cache is effectively serving requests, while the cache size should be sufficient to store the required data.
Designing a Plan to Identify and Eliminate Unused Serverless Resources
Identifying and eliminating unused serverless resources is a crucial step in cost optimization. Unused resources consume compute power and incur costs without providing any value. A proactive approach is essential.
- Regular Audits: Conduct regular audits of the serverless infrastructure to identify unused functions, event triggers, and other resources. These audits should be performed at least quarterly, or more frequently for large or rapidly changing environments.
- Monitoring Function Invocation Counts: Monitor the invocation counts of serverless functions. Functions with zero or very low invocation counts over a sustained period are potential candidates for removal.
- Analyzing Event Trigger Usage: Examine the usage of event triggers. Identify triggers that are not actively invoked or that are no longer needed.
- Reviewing Resource Configuration: Review the configuration of serverless resources to identify any over-provisioned settings. Adjust memory allocations, concurrency limits, and other parameters to match the actual requirements.
- Implementing a Decommissioning Process: Establish a formal process for decommissioning unused resources. This process should include:
- Notification: Notify stakeholders of the planned decommissioning.
- Data Archiving: Archive any necessary data before removing the resources.
- Testing: Test the impact of the decommissioning on other parts of the system.
- Removal: Remove the unused resources.
The Impact of Event Triggers on Expenses
Event triggers play a critical role in serverless applications, and their configuration and usage directly impact costs. Careful consideration of event trigger behavior is essential for optimizing expenses.
- Trigger Frequency and Cost: The frequency of event triggers directly influences the number of function invocations, and therefore, the cost. For example, a trigger that invokes a function every minute will result in significantly higher costs than a trigger that invokes a function once a day.
- Batching and Aggregation: Consider batching or aggregating events to reduce the number of function invocations. For example, instead of triggering a function for each individual message in a queue, process a batch of messages in a single function invocation.
- Event Filtering: Implement event filtering to ensure that only relevant events trigger the function. This can significantly reduce the number of unnecessary invocations.
- Trigger Configuration: Carefully configure event trigger settings, such as the concurrency limits and retry policies. Setting appropriate limits can prevent runaway costs and ensure that the function can handle the expected load.
- Event Source Optimization: Optimize the event source configuration. For example, when using a message queue, configure the queue to efficiently distribute messages to function instances.
Automation for Cost Management
Automating cost management is crucial for efficiently controlling serverless application expenses. Manual cost tracking and optimization are time-consuming and prone to errors. Automation enables proactive cost control, ensuring resources are utilized effectively and costs are minimized without sacrificing performance or scalability. This section explores various automation techniques and tools to streamline serverless cost management.
The Role of Infrastructure as Code (IaC) in Cost Control
Infrastructure as Code (IaC) plays a vital role in serverless cost control by enabling the programmatic definition and management of infrastructure resources. This approach promotes consistency, repeatability, and version control, all of which are essential for optimizing costs.IaC contributes to cost control in several key ways:
- Resource Provisioning and Configuration: IaC tools allow for the precise definition of resources, including their size, region, and associated configurations. This ensures that only necessary resources are provisioned, preventing over-provisioning and associated costs.
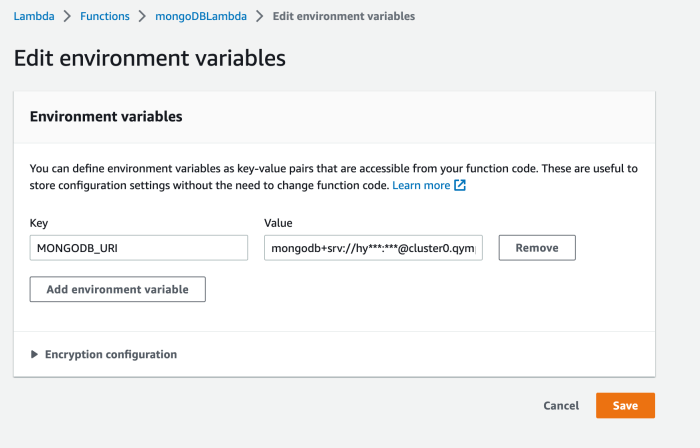
- Tagging Implementation: IaC facilitates the automated application of tagging policies. Tags are critical for cost allocation and analysis, enabling the tracking of expenses by project, team, or environment. IaC ensures consistent and accurate tagging across all resources.
- Environment Replication: IaC enables the easy replication of environments. This is particularly useful for testing and development, allowing teams to create isolated environments for experimentation without incurring excessive costs. These environments can be quickly spun up and torn down.
- Version Control: IaC integrates seamlessly with version control systems. Changes to infrastructure configurations are tracked, allowing for easy rollback to previous versions if issues arise. This reduces the risk of costly errors caused by manual configuration changes.
- Automated Deployment and Updates: IaC automates the deployment and updates of infrastructure, reducing the need for manual intervention. This reduces the risk of human error and ensures that updates are applied efficiently, potentially leading to cost savings.
Examples of Using Automation to Enforce Tagging Policies
Enforcing tagging policies is essential for accurate cost allocation and reporting. Automation tools can be used to ensure that all serverless resources are tagged consistently and correctly.Examples of automated tagging enforcement include:
- Pre-deployment Checks: Before deploying a new serverless function or other resource, automation tools can scan the IaC configuration (e.g., CloudFormation templates, Terraform scripts) to ensure that all required tags are present. If a required tag is missing, the deployment can be blocked or an error message can be generated, preventing the deployment of untagged resources.
- Post-deployment Validation: After deployment, automation tools can periodically scan deployed resources to verify that they are correctly tagged. If a resource is found to be missing a tag or has an incorrect tag value, the tool can automatically apply the correct tags or send a notification to the relevant team.
- Tagging Propagation: Automation can propagate tags from parent resources to child resources. For example, if a Lambda function is deployed within a VPC, the automation tool can ensure that the VPC’s tags are also applied to the Lambda function, allowing for accurate cost tracking across related resources.
- Custom Tagging Rules: Automation tools can enforce custom tagging rules. For example, you might require that all resources associated with a specific project have a particular tag with a specific value. The automation tool can validate these rules and automatically apply the tags if they are missing.
- Using CloudFormation Hooks: AWS CloudFormation Hooks can be used to automatically add or validate tags during resource creation. Hooks allow you to customize the behavior of CloudFormation during resource creation, update, and deletion operations.
Methods for Automatically Scaling Resources to Manage Costs
Automatic scaling is a critical component of cost management in serverless environments. Serverless platforms automatically scale resources based on demand, but you can further optimize costs by implementing strategies to control the scaling behavior.Methods for automatically scaling resources include:
- Configuring Autoscaling Policies: Serverless platforms, such as AWS Lambda, Azure Functions, and Google Cloud Functions, offer built-in autoscaling capabilities. You can configure these policies to automatically scale resources based on metrics such as CPU utilization, memory utilization, and concurrent executions. By setting appropriate thresholds and scaling limits, you can ensure that resources are scaled up only when needed, minimizing idle resources and associated costs.
- Implementing Scheduled Scaling: For workloads with predictable traffic patterns, you can schedule scaling events to proactively adjust resource capacity. For example, you can schedule a Lambda function to scale up during peak hours and scale down during off-peak hours. This allows you to optimize resource utilization and reduce costs during periods of low demand.
- Using Custom Metrics and Alerts: Monitor custom metrics and set up alerts to trigger scaling actions. For example, if your application experiences a sudden spike in request latency, you can configure an alert to trigger an autoscaling event to increase the number of function instances.
- Optimizing Concurrency Limits: For functions with limited concurrency, such as AWS Lambda, carefully configure the concurrency limits. Setting these limits too high can lead to over-provisioning and wasted resources. Conversely, setting the limits too low can lead to throttling and degraded performance.
- Using Resource-Based Scaling: Some serverless platforms allow you to scale resources based on the needs of individual requests. For example, you can configure a function to automatically increase its memory allocation if it receives a request that requires more processing power.
How to Integrate Cost Management into the CI/CD Pipeline
Integrating cost management into the CI/CD (Continuous Integration/Continuous Delivery) pipeline enables proactive cost control throughout the software development lifecycle. This integration allows teams to identify and address cost issues early in the development process.Integration methods include:
- Automated Tagging in CI/CD: Incorporate automated tagging into the CI/CD pipeline. When a new resource is deployed, the pipeline can automatically apply the necessary tags based on project, environment, or other relevant criteria. This ensures that all resources are tagged consistently and accurately.
- Cost Analysis During Build and Deployment: Integrate cost analysis tools into the CI/CD pipeline to assess the potential cost impact of changes. Before deploying a new version of a function or application, the pipeline can run a cost analysis to estimate the cost of the new deployment. This helps identify any cost-related issues before the deployment is completed.
- Cost Alerts and Notifications: Configure the CI/CD pipeline to send alerts and notifications if cost thresholds are exceeded. For example, if the estimated cost of a new deployment exceeds a predefined limit, the pipeline can trigger an alert and notify the relevant team.
- Cost Reporting and Visualization: Integrate cost reporting and visualization tools into the CI/CD pipeline. This allows teams to easily track and analyze the cost of their deployments over time. This data can be used to identify trends and areas for optimization.
- Automated Rollback for Cost Issues: Implement automated rollback mechanisms in the CI/CD pipeline to revert to a previous version of the application if cost issues are detected. This can prevent excessive costs from being incurred by a problematic deployment.
Compare Different Automation Tools for Serverless Cost Optimization
Several automation tools can be used for serverless cost optimization. The choice of tools depends on factors such as the cloud provider, the complexity of the application, and the specific cost optimization goals.Here’s a comparison of some popular automation tools:
| Tool | Cloud Provider | Key Features | Strengths | Weaknesses |
|---|---|---|---|---|
| AWS CloudFormation | AWS | Infrastructure as Code, resource provisioning, automated deployments, tagging | Native integration with AWS services, mature ecosystem, robust features | Can be complex for large projects, steep learning curve for beginners |
| Terraform | Multi-Cloud | Infrastructure as Code, resource provisioning, automated deployments, tagging | Supports multiple cloud providers, modular design, strong community support | Can be more complex to configure for AWS-specific features compared to CloudFormation |
| AWS Lambda Power Tuning | AWS | Automated performance testing, cost optimization for Lambda functions | Provides data-driven insights into function configuration, helps identify optimal memory allocation | Focuses primarily on Lambda function optimization |
| Azure Resource Manager (ARM) templates | Azure | Infrastructure as Code, resource provisioning, automated deployments, tagging | Native integration with Azure services, declarative syntax | Can be less flexible than Terraform for multi-cloud deployments |
| Google Cloud Deployment Manager | Google Cloud | Infrastructure as Code, resource provisioning, automated deployments, tagging | Native integration with Google Cloud services, supports declarative configuration | Smaller community and less mature ecosystem compared to Terraform or CloudFormation |
| Kubernetes (with tools like KubeCost) | Multi-Cloud | Container orchestration, cost monitoring, resource allocation | Provides granular control over resource allocation, supports cost tracking at the container level | Steeper learning curve for Kubernetes, requires expertise in containerization |
Advanced Cost Management Techniques
Effective serverless cost management extends beyond basic tracking and allocation. It necessitates the implementation of advanced techniques that proactively predict, detect, and optimize spending. This section delves into these sophisticated strategies, empowering organizations to gain greater control over their cloud expenditures and ensure financial efficiency.
Using Budgets and Forecasts to Predict Costs
Budgets and forecasts are crucial for proactive cost management. They enable organizations to anticipate future spending, identify potential overruns, and make informed decisions.To create an effective budget, several key steps should be followed:
- Establish Baseline Costs: Analyze historical spending data, leveraging cost allocation tags to understand costs by service, application, or team. This provides a foundation for future predictions.
- Define Budget Periods: Set budgets for specific timeframes, such as monthly, quarterly, or annually, aligning with financial reporting cycles.
- Set Budget Thresholds: Define spending limits and set alerts to notify stakeholders when spending approaches or exceeds those limits. Common alert thresholds are 80%, 90%, and 100% of the budget.
- Consider Seasonal Fluctuations: Account for expected variations in usage patterns due to seasonal events, marketing campaigns, or other factors.
- Incorporate Growth Projections: Factor in anticipated increases in usage and resource consumption as applications scale.
Forecasting utilizes historical data and trends to predict future costs. It often involves the following elements:
- Data Collection: Gather historical cost data, ideally with granular detail provided by cost allocation tags.
- Trend Analysis: Identify patterns and trends in spending over time, such as linear growth, exponential growth, or cyclical patterns.
- Statistical Modeling: Employ statistical models, such as time series analysis or regression analysis, to predict future costs based on historical data and identified trends.
- Scenario Planning: Develop multiple forecasts based on different scenarios, such as conservative, moderate, and aggressive growth projections.
For example, a company launching a new e-commerce platform can utilize historical data from similar platforms to predict costs. They would establish a budget based on estimated user traffic, transaction volume, and resource consumption. They could then set up alerts to monitor spending against the budget, adjusting resource allocation and optimizing configurations as needed to stay within the allocated financial limits.
Demonstrating the Use of Anomaly Detection to Identify Unusual Spending Patterns
Anomaly detection plays a critical role in identifying unexpected or unusual spending patterns that might indicate errors, misconfigurations, or malicious activity. It uses various techniques to establish a baseline of normal spending behavior and flag deviations from that baseline.The following are common anomaly detection techniques:
- Statistical Methods: Employ statistical methods, such as standard deviation and moving averages, to identify outliers in spending data. For example, if a service’s daily cost consistently falls within a specific range, an unexpected spike outside that range would be flagged as an anomaly.
- Machine Learning: Train machine learning models, such as clustering algorithms or time series forecasting models, to learn normal spending patterns and detect deviations. For example, a model trained on historical data can predict the expected cost for a given period, and significant discrepancies between the prediction and actual spending would trigger an alert.
- Rule-Based Systems: Define rules based on specific thresholds or conditions. For example, a rule could be set to flag any spending increase of more than 20% compared to the previous day.
Anomaly detection can be implemented by integrating with existing monitoring and alerting systems. When an anomaly is detected, an alert can be triggered, notifying the appropriate stakeholders to investigate.For example, a serverless application using AWS Lambda functions experiences a sudden increase in invocation duration and cost. Anomaly detection identifies this deviation from the normal pattern. This triggers an alert, allowing the development team to investigate the issue, potentially revealing a code bug, an inefficient function configuration, or a denial-of-service attack.
By promptly addressing the anomaly, the team can prevent excessive costs and maintain the application’s performance.
Creating a Guide to Using Cost Allocation Tags for Chargeback Purposes
Cost allocation tags are instrumental for allocating costs to specific departments, projects, or teams, enabling chargeback mechanisms. A chargeback system allows organizations to assign cloud costs to the internal consumers of those resources.The following is a guide to using cost allocation tags for chargeback:
- Define Tagging Strategy: Establish a consistent and comprehensive tagging strategy, identifying the key dimensions for cost allocation, such as:
- Project/Application: Tag resources with the project or application they support.
- Department/Team: Tag resources with the department or team responsible for their usage.
- Environment: Tag resources with the environment they belong to (e.g., production, staging, development).
- Cost Center: Tag resources with a cost center code for accounting purposes.
- Enforce Tagging: Implement policies and mechanisms to ensure consistent tagging across all resources.
- Tagging Policies: Define mandatory tags and their allowed values.
- Automation: Automate tag assignment using infrastructure-as-code tools or cloud provider-specific features.
- Tag Validation: Implement validation rules to ensure tags adhere to the defined standards.
- Collect and Analyze Cost Data: Use the cloud provider’s cost management tools to aggregate cost data based on the tags.
- Cost Explorer/Cost Management Dashboards: Utilize dashboards to visualize costs by tag, identifying the cost breakdown for each department, project, or team.
- Cost Reports: Generate detailed cost reports that can be used for chargeback purposes.
- Implement Chargeback Process: Define the process for allocating costs to internal consumers.
- Cost Allocation Model: Determine the methodology for allocating costs, such as direct allocation (assigning costs directly to the consuming department) or shared cost allocation (allocating costs based on usage metrics).
- Billing System Integration: Integrate the cost data with the organization’s internal billing system to generate chargeback invoices.
- Communication: Communicate the cost allocation process and results to the relevant stakeholders.
For example, a software development company uses cost allocation tags to track the costs associated with different software projects. Each project is assigned a unique tag. The company then generates monthly cost reports showing the costs incurred by each project, based on the associated tags. These reports are used to charge the project teams for the cloud resources they consume, fostering cost awareness and promoting efficient resource utilization.
Designing a System to Generate Cost Recommendations Based on Usage Patterns
Generating cost recommendations based on usage patterns is an effective way to proactively identify opportunities for cost optimization. This involves analyzing resource utilization, identifying inefficiencies, and suggesting actionable improvements.Here’s a system design for generating cost recommendations:
- Data Collection: Gather comprehensive data on resource usage, including:
- Service Utilization Metrics: Collect metrics such as CPU utilization, memory usage, network traffic, and storage capacity.
- Cost Data: Integrate cost data from cloud provider’s cost management tools, leveraging cost allocation tags.
- Application Performance Metrics: Gather metrics such as request latency, error rates, and throughput.
- Data Processing and Analysis: Process the collected data to identify usage patterns and potential optimization opportunities:
- Resource Profiling: Analyze resource utilization patterns to identify underutilized or over-provisioned resources.
- Performance Analysis: Analyze application performance metrics to identify areas for improvement.
- Cost Anomaly Detection: Implement anomaly detection techniques to identify unusual spending patterns.
- Recommendation Generation: Generate actionable recommendations based on the analysis:
- Right-Sizing: Recommend resizing resources based on utilization patterns, such as suggesting a smaller instance size for underutilized virtual machines.
- Configuration Optimization: Recommend optimizing configurations, such as enabling auto-scaling or optimizing database settings.
- Code Optimization: Recommend code improvements to reduce resource consumption, such as optimizing database queries or reducing the size of uploaded files.
- Recommendation Delivery: Deliver the recommendations to the relevant stakeholders:
- Dashboards: Display recommendations in dashboards, providing a clear overview of cost optimization opportunities.
- Alerts: Send alerts when potential cost savings are identified.
- Reports: Generate detailed reports summarizing recommendations and their potential impact.
For example, a system analyzes the usage of an AWS Lambda function. It identifies that the function is frequently invoked but consistently utilizes a small fraction of the allocated memory. The system generates a recommendation to reduce the function’s memory allocation, potentially resulting in cost savings without impacting performance. This recommendation is presented in a dashboard, along with an estimated cost reduction.
Organizing a Discussion About the Future Trends in Serverless Cost Management
Serverless cost management is an evolving field. Future trends will be shaped by advancements in cloud technology, the growing complexity of serverless applications, and the increasing demand for cost optimization.Here’s a discussion about the future trends:
- AI-Powered Cost Optimization: Artificial intelligence (AI) and machine learning (ML) will play an increasingly important role in cost optimization.
- Predictive Analytics: AI-powered tools will use predictive analytics to forecast future costs and identify potential cost overruns with greater accuracy.
- Automated Resource Optimization: AI will automate resource optimization, dynamically adjusting resource allocation based on real-time usage patterns.
- Anomaly Detection: AI will enhance anomaly detection, identifying unusual spending patterns and potential security threats with greater sophistication.
- Granular Cost Allocation and Reporting: The demand for granular cost allocation and reporting will continue to increase.
- Enhanced Tagging Capabilities: Cloud providers will offer more advanced tagging capabilities, allowing organizations to track costs at a more granular level, such as by individual function invocation or API call.
- Advanced Reporting Tools: Reporting tools will become more sophisticated, providing detailed cost breakdowns and insights into resource utilization.
- Serverless-Specific Cost Management Tools: Dedicated serverless cost management tools will emerge.
- Specialized Analytics: These tools will provide specialized analytics tailored to the unique characteristics of serverless applications, such as function invocation duration, cold start times, and concurrency.
- Automated Optimization: These tools will automate common optimization tasks, such as right-sizing functions and optimizing event triggers.
- Cost-Aware Development Practices: Developers will increasingly adopt cost-aware development practices.
- Cost-Aware Code: Developers will write code that is optimized for cost efficiency, such as minimizing function execution time and reducing the size of data transfers.
- Cost-Aware CI/CD: Continuous integration and continuous delivery (CI/CD) pipelines will incorporate cost checks, automatically identifying and addressing cost inefficiencies during the development process.
- Integration with FinOps: Serverless cost management will be seamlessly integrated with FinOps (Financial Operations) practices.
- Collaboration: Closer collaboration between engineering, finance, and operations teams will be essential for effective cost management.
- Data-Driven Decisions: Data-driven decision-making will be prioritized, using cost data to inform resource allocation, architectural design, and development practices.
The future of serverless cost management is characterized by automation, intelligence, and a greater emphasis on collaboration. Organizations that embrace these trends will be better positioned to optimize their cloud spending, improve their financial performance, and accelerate innovation.
Last Point
In conclusion, effective serverless cost management is no longer a luxury but a necessity. By strategically implementing tagging, organizations gain unparalleled visibility into their spending patterns, enabling informed decision-making and proactive optimization. This approach, coupled with automation and a commitment to continuous monitoring, allows teams to harness the full potential of serverless computing while maintaining financial prudence. As the cloud landscape evolves, mastering these techniques will be critical for maximizing the value of serverless deployments and achieving sustainable cost efficiency.
FAQ
What are the primary benefits of using tags for cost allocation?
Tags enable granular cost tracking, allowing businesses to allocate expenses to specific projects, teams, or environments, providing enhanced cost visibility and accountability.
How can I ensure consistent tagging across my organization?
Implementing tagging policies through Infrastructure as Code (IaC) and automating tag enforcement within your CI/CD pipeline can help to maintain consistency and prevent manual errors.
What is the impact of code execution time on serverless costs?
Longer execution times directly translate to higher costs, as you are billed for the duration of the function’s runtime. Optimizing code for efficiency is crucial to minimize execution time and reduce expenses.
How do I choose the right instance size for my serverless functions?
Selecting the appropriate memory allocation is crucial; start with the lowest possible allocation and monitor performance. Increase memory only when necessary to optimize cost and performance.
Can tagging help with chargeback within an organization?
Yes, by using cost allocation tags, organizations can accurately attribute costs to specific departments or teams, facilitating chargeback processes and promoting financial responsibility.