The advent of serverless computing has fundamentally altered the operational landscape, necessitating a paradigm shift in how organizations approach infrastructure management. This transition moves away from traditional, resource-intensive models towards a more agile and efficient approach, where the cloud provider assumes a greater share of operational responsibilities. Understanding the implications of this shift is crucial for operations teams seeking to navigate the complexities of serverless architectures and harness their full potential.
This analysis will dissect the evolving role of operations in a serverless environment, exploring the redistribution of responsibilities, the adoption of automation, and the challenges of monitoring, security, and cost optimization. It will also provide practical guidance on deployment, incident response, and scalability, culminating in a discussion of vendor lock-in and the necessary skills for operations teams to thrive in this new era.
Shifting Responsibilities in Serverless Operations

Serverless computing fundamentally alters the operational landscape, offloading many traditional infrastructure management tasks to the cloud provider. This shift allows operations teams to refocus on higher-level concerns, such as application performance and security, while the provider handles the underlying infrastructure. Understanding this redistribution of responsibilities is crucial for effectively managing applications in a serverless environment.
Operational Tasks Managed by Cloud Providers
The cloud provider in a serverless architecture assumes responsibility for several operational tasks previously handled by operations teams. This delegation is a core tenet of the serverless model, offering significant benefits in terms of reduced operational overhead and increased developer productivity.The cloud provider handles the following tasks:
- Server Provisioning and Management: The cloud provider is responsible for provisioning, scaling, and managing the underlying servers. Operations teams no longer need to worry about server capacity planning, patching, or operating system maintenance.
- Infrastructure Scaling: Serverless platforms automatically scale resources based on demand. Operations teams do not need to manually scale infrastructure during peak loads or scale down during periods of low activity.
- Operating System Management: The cloud provider manages the operating system, including security patches, updates, and configurations. This removes the need for operations teams to perform these tasks.
- Capacity Planning: Capacity planning is handled by the cloud provider. The provider dynamically allocates resources based on the function’s execution needs. Operations teams are not required to forecast resource requirements.
- High Availability and Disaster Recovery: Cloud providers offer built-in high availability and disaster recovery mechanisms. These mechanisms are usually managed and configured by the provider, simplifying the process for operations teams.
- Monitoring of Infrastructure Health: While operations teams still monitor application performance, the underlying infrastructure’s health and status are the responsibility of the cloud provider. The provider offers tools for monitoring the infrastructure’s health and performance.
Key Responsibilities Remaining with Operations Teams
Even in a serverless architecture, operations teams retain crucial responsibilities that are essential for ensuring application performance, security, and cost optimization. These responsibilities are critical for successful serverless deployments.The following responsibilities remain with operations teams:
- Application Monitoring and Observability: Operations teams must monitor application performance, including function execution times, error rates, and latency. They utilize monitoring tools and dashboards to gain insights into application behavior. They also manage logging and tracing to facilitate troubleshooting and debugging.
- Security and Compliance: Operations teams are responsible for securing serverless applications. This includes implementing security best practices, such as securing function code, managing access control, and adhering to compliance regulations. They need to implement robust security measures and maintain security configurations.
- Cost Optimization: Serverless architectures can be cost-effective, but they require careful management. Operations teams are responsible for monitoring and optimizing costs, including analyzing function usage, identifying cost-saving opportunities, and implementing cost controls.
Comparison of Operations Responsibilities: Traditional vs. Serverless
The transition to serverless significantly alters the roles and responsibilities of operations teams. The following table contrasts the operational tasks in traditional infrastructure and serverless environments.
| Responsibility | Traditional Infrastructure | Serverless Environment | Impact of Shift |
|---|---|---|---|
| Server Provisioning | Operations teams provision, configure, and manage servers. | Cloud provider handles server provisioning and management. | Reduced operational overhead, increased automation. |
| Infrastructure Scaling | Operations teams manually scale infrastructure. | Cloud provider automatically scales infrastructure. | Improved scalability, reduced manual intervention. |
| Operating System Management | Operations teams manage operating system updates, patching, and security. | Cloud provider manages the operating system. | Simplified management, increased security through automatic updates. |
| Capacity Planning | Operations teams forecast resource requirements and plan capacity. | Cloud provider handles capacity planning. | Elimination of capacity planning, increased resource efficiency. |
| High Availability and Disaster Recovery | Operations teams configure and manage high availability and disaster recovery solutions. | Cloud provider provides built-in high availability and disaster recovery. | Simplified setup, improved resilience. |
| Application Monitoring | Operations teams monitor application performance and infrastructure health. | Operations teams focus on application performance, utilizing provider-provided monitoring tools. | Shift in focus towards application-level monitoring, reduced infrastructure-level monitoring. |
| Security Management | Operations teams manage security infrastructure, including firewalls and intrusion detection systems. | Operations teams focus on application security, access control, and identity management. | Shift in focus towards application-level security, reduced infrastructure-level security management. |
| Cost Optimization | Operations teams manage infrastructure costs and optimize resource utilization. | Operations teams monitor and optimize function execution costs. | Focus on function-level cost optimization, utilizing cost analysis tools. |
Automation and Serverless Management
Serverless computing necessitates a fundamental shift in how automation is approached within operations. Traditional infrastructure management often relies on automation tools designed to configure and maintain long-lived servers. Serverless environments, however, are characterized by ephemeral resources, event-driven architectures, and a greater reliance on managed services. This shift demands a different set of automation strategies, focusing on deployment, scaling, monitoring, and incident response tailored to the unique characteristics of serverless applications.
Automation Tools in Serverless Operations
Automation tools in serverless operations are utilized differently compared to traditional infrastructure management due to the inherent characteristics of serverless architectures. Instead of focusing on server provisioning and configuration, automation in serverless shifts to managing the lifecycle of functions, APIs, and event triggers. Tools like Infrastructure as Code (IaC) are paramount for defining and deploying serverless resources consistently. Continuous Integration/Continuous Deployment (CI/CD) pipelines become critical for automating code updates and deployments.
Monitoring and alerting systems need to be automated to dynamically respond to changes in application performance and resource utilization. Furthermore, automation plays a crucial role in security, ensuring consistent application of security policies and automated remediation of vulnerabilities.
Critical Automation Tasks for Serverless Management
Effective serverless management hinges on automating several key tasks. These tasks, if implemented correctly, significantly reduce operational overhead and improve the reliability and scalability of serverless applications.
- Automated Deployment and Rollbacks: Automating the deployment process ensures consistent and repeatable deployments of serverless functions and associated resources. Rollback mechanisms are crucial for quickly reverting to a previous, stable state in case of deployment failures.
- Automated Scaling and Resource Management: Serverless platforms inherently scale automatically, but automation is needed to manage resource limits, provisioned concurrency, and other platform-specific configurations to optimize performance and cost. This includes automated adjustment of memory allocation and timeouts based on observed performance metrics.
- Automated Monitoring and Alerting: Implementing automated monitoring systems that collect and analyze metrics from serverless functions and associated services is essential. Automated alerts should be configured to notify operations teams of performance degradation, errors, and security threats.
- Automated Security and Compliance: Security automation encompasses tasks like automated vulnerability scanning, security policy enforcement, and compliance checks. This includes integrating security testing into CI/CD pipelines and automatically applying security patches and updates.
- Automated Incident Response: Automation is crucial for incident response. This includes automatically triggering actions based on alerts, such as scaling resources, restarting functions, or rolling back deployments. Automated runbooks and playbooks streamline the response process and minimize downtime.
Infrastructure as Code for Serverless Deployment
Infrastructure as Code (IaC) is a foundational practice for managing serverless infrastructure. IaC allows for defining and managing serverless resources using code, enabling version control, repeatability, and automated deployments. Tools like AWS CloudFormation, Terraform, and the Serverless Framework are commonly used for this purpose.For example, consider a simple serverless function deployed on AWS Lambda triggered by an API Gateway. Using CloudFormation, you can define this infrastructure in a YAML or JSON template.“`yamlAWSTemplateFormatVersion: ‘2010-09-09’Transform: AWS::Serverless-2016-10-31Description: Simple Serverless Function with API GatewayResources: MyFunction: Type: AWS::Serverless::Function Properties: Handler: index.handler Runtime: nodejs18.x CodeUri: ./src Events: ApiEvent: Type: Api Properties: Path: /hello Method: get ApiGatewayPermission: Type: AWS::Lambda::Permission Properties: FunctionName: !GetAtt MyFunction.Arn Action: lambda:InvokeFunction Principal: apigateway.amazonaws.com SourceArn: !Sub arn:aws:execute-api:$AWS::Region:$AWS::AccountId:$ApiGatewayApi/*/*“`This CloudFormation template defines a Lambda function (MyFunction) with a specified handler, runtime, and code location.
It also defines an API Gateway event (ApiEvent) that triggers the function when a GET request is made to the /hello path. The template also creates a Lambda permission allowing the API Gateway to invoke the Lambda function. The `CodeUri` property points to the source code location. The `Handler` property specifies the entry point of the function. The `Events` section defines how the function is triggered.The deployment process using IaC typically involves the following steps:
- Template Creation: The infrastructure is defined in a template (YAML or JSON).
- Template Validation: The template is validated to ensure it is syntactically correct and semantically valid.
- Deployment: The IaC tool deploys the resources defined in the template, creating, updating, or deleting resources as needed.
- Version Control: Templates are stored in version control systems, enabling tracking of changes and rollbacks.
This approach ensures that the infrastructure is consistently deployed and managed, enabling automation and reducing the risk of human error. The example demonstrates the ability to define, deploy, and manage serverless functions and related resources using code, showcasing the power of IaC in a serverless context.
Monitoring and Observability Challenges
Serverless architectures, while offering significant benefits in terms of scalability and cost efficiency, introduce novel complexities to monitoring and observability. The ephemeral nature of serverless functions, the distributed nature of event-driven systems, and the reliance on managed services create unique challenges in understanding application behavior, diagnosing issues, and ensuring optimal performance. Traditional monitoring approaches, often designed for monolithic applications running on dedicated servers, are frequently inadequate for the dynamic and decentralized nature of serverless deployments.
This necessitates the adoption of new tools, techniques, and strategies to effectively monitor and observe these environments.
Ephemeral Nature and Granularity
Serverless functions execute on demand, often for short durations, making traditional monitoring techniques, such as log analysis and performance profiling, more challenging. The transient nature of function instances means that metrics and logs are often scattered across numerous executions, requiring aggregation and correlation to gain meaningful insights. Moreover, the fine-grained nature of serverless applications, with numerous functions potentially interacting with each other, increases the complexity of tracing requests and identifying performance bottlenecks.
Distributed Tracing and Correlation
The distributed nature of serverless applications necessitates robust distributed tracing capabilities. A single user request may trigger a chain of events, resulting in the execution of multiple functions across different services. Without distributed tracing, it is difficult to understand the flow of a request, identify the functions involved, and pinpoint the source of performance issues or errors. Correlating logs, metrics, and traces across these distributed components is crucial for effective debugging and performance optimization.
Third-Party Dependencies and Managed Services
Serverless applications often rely heavily on third-party services and managed services, such as databases, message queues, and storage solutions. Monitoring these dependencies is critical, as their performance and availability directly impact the application. Furthermore, understanding the interactions between serverless functions and these external services, including latency, error rates, and resource consumption, is essential for comprehensive observability.
Monitoring Tools and Techniques for Serverless Applications
Several monitoring tools and techniques are specifically designed to address the challenges of serverless architectures. These tools provide features such as automatic instrumentation, distributed tracing, and serverless-specific metrics to help developers gain visibility into their applications.
- CloudWatch (AWS): Amazon CloudWatch is a comprehensive monitoring service provided by AWS. It offers features for collecting and visualizing metrics, logging, and setting up alarms. CloudWatch integrates seamlessly with other AWS services, including Lambda, API Gateway, and DynamoDB, providing out-of-the-box monitoring capabilities. It offers detailed metrics such as invocation count, duration, errors, and throttles for Lambda functions. CloudWatch Logs allows for centralized log aggregation and analysis, facilitating troubleshooting and performance analysis.
- Google Cloud Monitoring (GCP): Google Cloud Monitoring (formerly Stackdriver) is Google Cloud’s monitoring service. It offers similar capabilities to CloudWatch, including metric collection, logging, and alerting. Cloud Monitoring integrates with Google Cloud services, such as Cloud Functions, Cloud Run, and Cloud Storage, providing detailed performance metrics and logs. It offers advanced features like log-based metrics and custom dashboards for tailored monitoring.
- Azure Monitor (Azure): Azure Monitor is Microsoft Azure’s monitoring service. It provides comprehensive monitoring capabilities for Azure services, including Azure Functions, API Management, and Cosmos DB. Azure Monitor offers features for collecting metrics, logs, and traces, as well as setting up alerts and dashboards. It integrates with Application Insights for application performance monitoring, offering features like distributed tracing and transaction diagnostics.
- OpenTelemetry: OpenTelemetry is a vendor-neutral, open-source observability framework. It provides a standardized way to collect and export telemetry data (metrics, logs, and traces) from applications. OpenTelemetry can be used to instrument serverless functions and send telemetry data to various backends, such as Prometheus, Jaeger, and Grafana. This allows developers to gain a unified view of their application’s performance and behavior across different cloud providers and environments.
- Serverless-Specific APM Tools: Several Application Performance Monitoring (APM) tools specialize in serverless monitoring. These tools, such as Epsagon (now part of Lightstep) and Lumigo, provide automated instrumentation, distributed tracing, and serverless-specific dashboards. They typically offer features like automatic error detection, performance profiling, and cost optimization recommendations tailored to serverless environments.
Setting Up Alerts and Dashboards
Setting up effective alerts and dashboards is crucial for proactively monitoring serverless applications and responding to issues promptly. Alerts notify developers when critical metrics exceed predefined thresholds, while dashboards provide a visual overview of application health and performance.
- Define Key Metrics: Identify the most important metrics for your serverless application. These metrics will vary depending on the application’s functionality and requirements, but common examples include:
- Invocation Count: The number of times a function is executed.
- Duration: The time it takes for a function to complete execution.
- Errors: The number of errors that occur during function execution.
- Throttles: The number of times a function is throttled due to resource limitations.
- Cold Starts: The number of times a function experiences a cold start (i.e., the first invocation after a period of inactivity).
- Latency: The time it takes for a request to be processed, from the user’s perspective.
- API Gateway Latency: The time it takes for a request to be processed by the API gateway.
- Database Read/Write Throughput: The amount of data being read from or written to the database.
- Message Queue Processing Time: The time it takes for messages to be processed from the message queue.
- Invocation Count Over Time: A line chart showing the number of function invocations over a specific period. This helps visualize the traffic patterns and identify any unexpected spikes or drops.
- Error Rate by Function: A bar chart showing the error rate for each function in your application. This allows you to quickly identify the functions that are experiencing the most errors.
- Function Duration Distribution: A histogram showing the distribution of function execution times. This helps identify potential performance bottlenecks and optimize function code.
- API Gateway Latency: A line chart or a table displaying the average latency for different API endpoints.
- Database Connection Pool Usage: A graph showing the number of database connections in use over time. This helps in identifying potential resource exhaustion issues.
Security Considerations in Serverless Operations

The transition to a serverless architecture fundamentally alters the security landscape, shifting responsibilities and demanding a new approach to securing applications and infrastructure. Traditional security practices, designed for managing and protecting servers, are often inadequate in a serverless environment. The shared responsibility model becomes even more pronounced, with cloud providers managing the underlying infrastructure security, while developers take on greater responsibility for application-level security, identity and access management, and data protection.
This requires a proactive and continuous security posture that adapts to the dynamic and ephemeral nature of serverless functions.
Shifting Security Responsibilities in Serverless
The shared responsibility model in serverless operations delineates security responsibilities between the cloud provider and the user. The cloud provider is accountable for the security
- of* the cloud, including the underlying infrastructure, the availability of services, and the physical security of data centers. Users, on the other hand, are responsible for the security
- in* the cloud, focusing on the security of their applications, data, and configurations.
- Cloud Provider Responsibilities: The cloud provider’s responsibilities include:
- Physical security of data centers and infrastructure.
- Security of the underlying compute, storage, and network infrastructure.
- Availability and security of serverless platform services.
- Protection against infrastructure-level attacks (e.g., DDoS attacks).
- User Responsibilities: Users are primarily responsible for:
- Securing serverless function code and dependencies.
- Implementing robust identity and access management (IAM) policies.
- Securing data at rest and in transit.
- Monitoring and logging application activity.
- Configuration and security of associated resources (e.g., databases, APIs).
- Responding to security incidents.
Security Best Practices for Securing Serverless Functions and Resources
Securing serverless functions and associated resources requires a layered approach that encompasses code, configuration, and access control. Implementing these best practices helps mitigate security risks and ensures the integrity and confidentiality of serverless applications.
- Secure Function Code:
- Regularly scan function code for vulnerabilities using static analysis tools.
- Minimize dependencies and keep them updated to patch security vulnerabilities.
- Implement input validation to prevent injection attacks (e.g., SQL injection, cross-site scripting).
- Use secure coding practices to avoid common vulnerabilities.
- Encrypt sensitive data within the function code, such as API keys and database credentials.
- Implement Strong Authentication and Authorization:
- Use strong authentication mechanisms, such as multi-factor authentication (MFA), to verify user identities.
- Employ the principle of least privilege, granting functions only the necessary permissions to access resources.
- Use IAM roles and policies to control access to cloud resources.
- Regularly review and update IAM policies to ensure they align with security best practices.
- Implement API gateways with authentication and authorization features to control access to serverless functions.
- Secure Data at Rest and in Transit:
- Encrypt data at rest using encryption keys managed by the cloud provider or a customer-managed key (CMK).
- Encrypt data in transit using TLS/SSL certificates.
- Use secure protocols (e.g., HTTPS) for API communication.
- Protect sensitive data by tokenizing or masking it.
- Monitor and Log Application Activity:
- Enable detailed logging for all serverless functions and associated resources.
- Monitor logs for suspicious activity, such as unauthorized access attempts or unusual API calls.
- Use security information and event management (SIEM) tools to collect, analyze, and correlate security logs.
- Implement automated alerting for security incidents.
- Regularly review and audit security logs.
- Automate Security:
- Automate security testing, such as vulnerability scanning and penetration testing, as part of the CI/CD pipeline.
- Use infrastructure-as-code (IaC) to define and manage security configurations consistently.
- Automate security patching and updates for dependencies.
- Implement automated security audits to identify and remediate security vulnerabilities.
Security Checklist for Serverless Deployments
This security checklist provides a structured approach to securing serverless deployments, covering key areas such as authentication, authorization, data encryption, and monitoring. This checklist is designed for four responsive columns: “Category”, “Check Item”, “Verification Method”, and “Status”. The “Status” column is intended to be updated as the security measures are implemented and verified.
| Category | Check Item | Verification Method | Status |
|---|---|---|---|
| Authentication | Implement multi-factor authentication (MFA) for all user accounts. | Verify MFA is enabled in the cloud provider’s console and tested for access. | |
| Authentication | Use API keys with appropriate restrictions and rotation. | Review API gateway configuration and access logs for key usage and rotation schedule. | |
| Authorization | Apply the principle of least privilege to all IAM roles and policies. | Review IAM policies and access logs to ensure only necessary permissions are granted. | |
| Authorization | Use resource-based policies for fine-grained access control. | Examine resource policies (e.g., S3 bucket policies, Lambda function policies) for proper access control. | |
| Code Security | Scan function code for vulnerabilities and dependencies. | Execute static analysis tools and review scan reports for vulnerabilities. | |
| Code Security | Implement input validation and output encoding to prevent injection attacks. | Review function code for input validation and output encoding implementations. | |
| Data Encryption | Encrypt data at rest using cloud provider-managed or customer-managed keys. | Verify encryption settings for storage services (e.g., S3, databases). | |
| Data Encryption | Encrypt data in transit using TLS/SSL certificates. | Confirm TLS/SSL is enabled for all API endpoints and data transfers. | |
| Monitoring and Logging | Enable detailed logging for all serverless functions and associated resources. | Verify logging is enabled in the cloud provider’s console and review log configuration. | |
| Monitoring and Logging | Monitor logs for suspicious activity and security incidents. | Configure security alerts and review monitoring dashboards. | |
| Network Security | Secure serverless functions by placing them within a VPC (Virtual Private Cloud) | Verify the Lambda function is within a VPC, network ACLs are configured and security groups. | |
| Configuration Management | Use infrastructure-as-code (IaC) to manage security configurations consistently. | Review IaC templates (e.g., CloudFormation, Terraform) for security settings and compliance. |
Cost Optimization Strategies
Serverless architectures fundamentally alter the landscape of cost management in software development. Unlike traditional infrastructure models where costs are often fixed and predictable, serverless environments operate on a pay-per-use basis. This necessitates a shift in strategy, focusing on granular control and continuous optimization to minimize expenses. The dynamic nature of serverless demands a proactive approach to cost management, involving careful monitoring, analysis, and iterative adjustments.
Impact of Serverless Architectures on Cost Management
Serverless computing transforms cost management by aligning expenses directly with actual resource consumption. This contrasts with traditional models where resources are provisioned and paid for regardless of utilization. This shift introduces both opportunities and challenges.
- Pay-per-use model: Costs are incurred only when functions are executed or resources are utilized. This eliminates idle resource costs, which can be significant in traditional infrastructure.
- Scalability and elasticity: Serverless platforms automatically scale resources based on demand, preventing over-provisioning and associated costs. This elasticity ensures that you pay only for what you use, optimizing costs during periods of fluctuating traffic.
- Granular billing: Serverless providers offer detailed billing information, allowing for precise cost tracking and analysis. This granular visibility enables you to identify cost drivers and optimize specific areas of your application.
- Vendor lock-in considerations: While serverless offers cost benefits, it can also introduce vendor lock-in. Carefully evaluating the pricing models and service offerings of different providers is essential to avoid excessive costs and ensure flexibility.
Methods for Optimizing Serverless Application Costs
Optimizing the cost of serverless applications requires a multi-faceted approach, encompassing resource allocation, function design, and ongoing monitoring.
- Resource Allocation Optimization: This involves fine-tuning the resources allocated to serverless functions to match their actual needs. Over-provisioning leads to unnecessary costs, while under-provisioning can result in performance degradation.
- Memory allocation: Carefully select the appropriate memory allocation for each function. Monitor function performance and adjust memory settings to balance performance and cost.
- Timeout configuration: Set appropriate timeout values for functions to prevent them from running longer than necessary. Shorter timeouts can reduce costs, but excessively short timeouts may lead to errors.
- Function Optimization: Efficient function design is crucial for minimizing execution time and resource consumption.
- Code optimization: Write efficient code that minimizes execution time and resource usage. Profile your functions to identify performance bottlenecks and optimize critical sections of code.
- Dependency management: Minimize the number and size of dependencies included in your function packages. Larger packages increase cold start times and execution costs.
- Function reuse: Design functions to be reusable across different parts of your application. This reduces code duplication and minimizes the number of functions that need to be deployed and managed.
- Event Source Optimization: Optimize the triggers that initiate function execution.
- Batching: Configure event sources, such as message queues, to batch events and trigger functions less frequently. This reduces the number of function invocations and associated costs.
- Filtering: Use event filtering mechanisms to ensure that functions are only triggered for relevant events. This prevents unnecessary function invocations and reduces costs.
- Monitoring and Alerting: Implementing comprehensive monitoring and alerting systems is crucial for identifying cost anomalies and opportunities for optimization.
- Cost dashboards: Create custom dashboards to visualize your serverless spending and track key metrics, such as function invocation counts, execution times, and memory usage.
- Cost alerts: Set up alerts to notify you when costs exceed predefined thresholds. This allows you to proactively address cost spikes and prevent unexpected expenses.
Cost Analysis Model for Serverless Functions
A cost analysis model provides a framework for estimating and controlling costs associated with serverless functions. The model considers factors such as function execution time, memory usage, and the number of invocations.The core components of a cost analysis model include:
- Function Execution Time: Measured in milliseconds, this is the duration a function runs for each invocation.
- Memory Usage: Measured in gigabytes (GB), this is the amount of memory allocated to the function.
- Number of Invocations: The total number of times a function is executed.
- Pricing Model: The specific pricing structure of the serverless provider, which typically includes a cost per execution and a cost per GB-second of compute time.
The basic formula for estimating the cost of a serverless function can be represented as:
Cost = (Number of Invocations)
- [(Execution Time in Seconds)
- (Memory Used in GB)
- (Price per GB-second) + (Price per Invocation)]
Example:Consider a serverless function with the following characteristics:
- 1,000,000 Invocations per month
- Average Execution Time: 200 milliseconds (0.2 seconds)
- Memory Used: 128 MB (0.128 GB)
- Provider Price: $0.00001667 per GB-second, $0.0000002 per invocation
Applying the formula:
Cost = 1,000,000
- [(0.2)
- (0.128)
- (0.00001667) + 0.0000002]
= 1,000,000 – [0.000000426 + 0.0000002]= 1,000,000 – 0.000000626= $0.626 per month.
This model can be expanded to include other cost factors, such as data transfer costs and storage costs. By using a cost analysis model, you can:
- Estimate costs: Predict the cost of running serverless functions based on expected usage patterns.
- Track costs: Monitor actual costs and compare them to your estimates.
- Identify cost drivers: Determine which factors are contributing the most to your serverless spending.
- Optimize costs: Experiment with different configurations and code optimizations to reduce your expenses.
Deployment and Release Management
Serverless architectures fundamentally alter the approach to deployment and release management. The ephemeral nature of serverless functions, combined with the event-driven paradigm, necessitates a shift from traditional infrastructure-centric deployment strategies to a code-centric, automated approach. This shift emphasizes rapid iteration, atomic deployments, and robust rollback mechanisms to ensure application stability and agility.
Changes in Deployment and Release Management Processes
Serverless deployment processes differ significantly from those in traditional infrastructure-based environments. These changes are driven by the characteristics of serverless functions, including their stateless nature, event-driven invocation, and the managed infrastructure provided by the cloud provider.
- Infrastructure as Code (IaC) is Paramount: Serverless deployments rely heavily on IaC principles. Configuration, infrastructure provisioning (e.g., API gateways, database connections), and function deployment are defined declaratively using tools like AWS CloudFormation, Azure Resource Manager, or Terraform. This approach ensures consistency, repeatability, and version control of the entire application stack. Instead of manually configuring servers, the configuration is codified and deployed as a unit.
- Atomic Deployments are Commonplace: Serverless platforms often support atomic deployments, where a new version of a function is deployed without affecting existing invocations. This ensures that in-flight requests are not interrupted during updates. The cloud provider manages the routing of traffic between different function versions, allowing for zero-downtime deployments.
- Blue/Green Deployments and Canary Releases are Simplified: Serverless platforms facilitate advanced deployment strategies like blue/green deployments and canary releases. Blue/green deployments involve deploying a new version (green) alongside the existing version (blue) and then switching traffic gradually or all at once. Canary releases involve routing a small percentage of traffic to the new version to test it in production before a full rollout. These strategies minimize risk and allow for faster feedback.
- Automated Rollbacks are Critical: Because serverless applications are inherently distributed and rely on external services, failures can occur. Automated rollbacks are essential to quickly revert to a known-good version of a function if issues are detected. This involves mechanisms to automatically detect errors and trigger the deployment of a previous version.
- Simplified Versioning and Aliasing: Serverless platforms typically offer built-in versioning and aliasing capabilities. Each time a function is updated, a new version is created. Aliases, which are human-readable names (e.g., “production,” “staging”), can then be associated with specific function versions. This simplifies traffic management and enables rollback strategies.
- Focus on Code Deployment, Not Infrastructure Management: The emphasis shifts from managing servers and infrastructure to deploying and managing the application code itself. The cloud provider handles the underlying infrastructure, allowing developers to focus on writing business logic. This reduces operational overhead and speeds up the development lifecycle.
Implementing a CI/CD Pipeline for Serverless Functions
A well-defined CI/CD pipeline is crucial for automating the build, test, and deployment of serverless functions. The pipeline streamlines the development process, enabling rapid and reliable releases. Here’s a step-by-step guide.
- Code Repository and Version Control: Use a version control system like Git to manage the source code of your serverless functions. Each change to the code should be committed and tracked. Platforms like GitHub, GitLab, and Bitbucket provide hosting and collaboration features.
- Build Process: This step involves compiling code (if necessary), packaging dependencies, and preparing the function for deployment. For example, with Node.js functions, this might involve running `npm install` to install dependencies and bundling the code.
- Automated Testing: Implement automated tests to ensure the quality and reliability of the code. This includes unit tests, integration tests, and potentially end-to-end tests. Testing should cover various aspects of the function’s behavior, including input validation, error handling, and interaction with external services.
- Deployment to a Staging Environment: Deploy the function to a staging environment for testing and validation. This environment mirrors the production environment but allows for safe testing without impacting users. Use a separate set of resources and configurations for the staging environment.
- Staging Environment Testing: Run thorough testing in the staging environment, including integration tests and user acceptance testing (UAT). This verifies that the function behaves as expected in a realistic environment.
- Deployment to Production: Once the function passes all tests in the staging environment, deploy it to production. This can involve several strategies, such as blue/green deployments or canary releases, to minimize downtime and risk.
- Monitoring and Alerting: Implement monitoring and alerting to track the performance and health of the function in production. This includes metrics like invocation count, execution time, error rates, and resource utilization. Set up alerts to notify the team of any issues.
- Automated Rollback: Configure automated rollbacks to revert to a previous version of the function if issues are detected in production. This can be triggered by monitoring metrics, such as error rates exceeding a threshold.
Code Deployment Example (AWS Lambda and Node.js):
This example demonstrates deploying a simple Node.js function to AWS Lambda using the AWS CLI and a `serverless.yml` configuration file (a simplified example):
serverless.yml:
“`yamlservice: my-serverless-appprovider: name: aws runtime: nodejs18.x region: us-east-1 # IAM role with permissions to access AWS resources iamRoleStatements:
Effect
“Allow” Action:
“s3
GetObject” Resource: “arn:aws:s3:::my-bucket/*”functions: hello: handler: handler.hello events:
http
path: /hello method: get“`
handler.js:
“`javascriptexports.hello = async (event) => return statusCode: 200, body: JSON.stringify( message: ‘Hello, Serverless!’ ), ;;“`
Deployment Steps (using the AWS CLI):
- Install the Serverless Framework (if not already installed):
npm install -g serverless - Configure AWS credentials: Ensure your AWS credentials are configured, typically via `aws configure`.
- Deploy the function: Navigate to the project directory and run
serverless deploy. The Serverless Framework will handle the packaging, deployment, and configuration of the Lambda function and related resources (e.g., API Gateway). - Test the deployment: After deployment, the Serverless Framework will output the API endpoint URL. You can test the function by sending a GET request to that URL (e.g., using `curl` or a web browser).
Managing Version Control and Rollbacks in Serverless Applications
Effective version control and rollback strategies are critical for maintaining the stability and reliability of serverless applications. These strategies minimize downtime and enable rapid recovery from deployment issues.
- Version Control Systems: Employ Git or a similar version control system to track all code changes. This allows developers to revert to previous versions, collaborate effectively, and maintain a history of all modifications.
- Function Versioning: Leverage the built-in versioning capabilities of serverless platforms. Each time a function is updated, a new version is created. This creates immutable versions that can be referenced.
- Aliases for Traffic Management: Use aliases (e.g., “production,” “staging”) to map to specific function versions. This enables easy traffic management. For example, the “production” alias might point to version 1.0, while “staging” points to version 1.1.
- Blue/Green Deployments: Deploy a new version (green) alongside the existing version (blue) and gradually shift traffic. This minimizes downtime during updates.
- Canary Releases: Route a small percentage of traffic to the new version (canary) to test it in production before a full rollout. This allows for early detection of issues.
- Automated Rollback Triggers: Implement automated rollback triggers based on monitoring metrics, such as error rates, latency, and invocation failures. When a trigger is activated, the system automatically reverts to a previous, known-good version. These triggers can be based on thresholds, for instance, if the error rate exceeds 5% over a 5-minute period.
- Monitoring and Alerting for Rollbacks: Ensure that monitoring and alerting systems are in place to detect issues quickly. This includes metrics related to function performance, error rates, and external service dependencies. Alerts should be configured to notify the operations team of any problems.
- Rollback Automation: Integrate automated rollback capabilities into the CI/CD pipeline. This can be triggered by automated tests, monitoring metrics, or manual intervention. The automation should handle the redeployment of the previous version and, if necessary, revert any related infrastructure changes.
- Testing Rollback Procedures: Regularly test the rollback procedures to ensure they function correctly. This includes simulating failures and verifying that the system can revert to a previous version without significant downtime or data loss.
- Immutable Infrastructure Principles: Adopt immutable infrastructure principles. Treat infrastructure as code, and deploy new versions rather than modifying existing ones. This approach minimizes the risk of configuration drift and simplifies rollbacks.
Incident Response and Troubleshooting
Serverless architectures, while offering significant advantages in scalability and operational efficiency, introduce unique challenges to incident response and troubleshooting. The distributed nature of serverless applications, coupled with the ephemeral nature of function executions, necessitates a shift in traditional operational practices. Effective incident response requires proactive monitoring, rapid identification of issues, and automated remediation strategies to minimize downtime and maintain service levels.
Incident Response Procedures in Serverless Environments
The procedures for incident response in a serverless environment diverge from those in traditional infrastructure. The focus shifts from server-level diagnostics to function-level analysis and the interplay of various serverless services.
- Event-Driven Nature: Serverless applications are inherently event-driven. Incidents often manifest as failures in event processing or incorrect responses to events. Incident response must therefore prioritize the examination of event sources, triggers, and function logs to understand the sequence of events leading to a failure.
- Automated Remediation: Due to the potential for rapid scaling and the ephemeral nature of function instances, manual intervention is often impractical. Incident response should incorporate automated remediation strategies. This might include automatically scaling up function instances, rolling back deployments, or triggering alerts to notify operations teams.
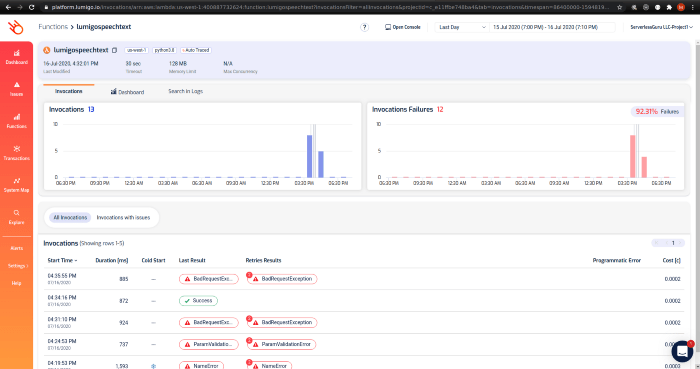
- Centralized Logging and Monitoring: Centralized logging and monitoring are crucial. Services like AWS CloudWatch, Azure Monitor, and Google Cloud Operations provide comprehensive logging, metrics, and tracing capabilities. These tools are essential for correlating events across different services and functions, providing a holistic view of the application’s health.
- Function-Specific Alerts: Alerts should be configured based on function-specific metrics, such as invocation errors, latency, and resource utilization. These alerts should be integrated with incident management systems to facilitate rapid response and escalation.
- Immutable Infrastructure Considerations: Serverless deployments often utilize immutable infrastructure principles. When an incident occurs, the focus should be on deploying a known-good version of the function or scaling existing instances rather than patching individual servers.
Troubleshooting Serverless Function Failures
Troubleshooting serverless function failures requires a systematic approach that leverages the capabilities of cloud provider tools. Identifying the root cause often involves analyzing logs, metrics, and traces to pinpoint the source of the problem.
- Log Analysis: Detailed logs are the primary source of information for troubleshooting. Function logs, API Gateway logs, and logs from other integrated services provide valuable insights into the function’s behavior. Analyzing these logs involves searching for error messages, stack traces, and other relevant information.
- Metric Monitoring: Monitoring key metrics, such as invocation count, error rate, latency, and resource utilization, provides an overview of the function’s performance. Anomalies in these metrics can indicate potential issues. For instance, a sudden increase in error rate may signal a code bug or a resource constraint.
- Tracing: Distributed tracing allows for tracking requests as they flow through various services and functions. Tracing tools, such as AWS X-Ray, provide a visual representation of the request flow, making it easier to identify bottlenecks and errors.
- Error Handling and Retries: Implementing robust error handling and retry mechanisms within functions is crucial. Retrying failed operations can mitigate transient errors, while proper error handling can prevent cascading failures.
- Resource Constraints: Serverless functions have resource limits, such as memory and execution time. Exceeding these limits can lead to failures. Monitoring resource utilization and optimizing function code to reduce resource consumption are important troubleshooting steps.
Troubleshooting Flowchart for Serverless Applications
A troubleshooting flowchart provides a structured approach to diagnosing and resolving common serverless application problems. This flowchart guides through a series of steps, starting with initial symptoms and leading to potential solutions.
Flowchart Description:
The flowchart begins with the observation of an issue, such as increased latency or function failures. It then proceeds through a series of decision points and actions:
1. Symptom Observed
The process starts when a user or system detects an issue. This could be increased latency, errors, or unexpected behavior.
2. Check Monitoring Dashboard
The first step is to examine the monitoring dashboard (e.g., CloudWatch, Azure Monitor, Google Cloud Operations). This provides an overview of the application’s health, including metrics like error rates, latency, and invocation counts.
Error Rate High? If the error rate is high, proceed to the next step; otherwise, check the latency.
4. Examine Function Logs
Analyze function logs to identify error messages, stack traces, and other relevant information. Logs are the primary source of information for understanding the function’s behavior.
5. Review API Gateway Logs
If applicable, review API Gateway logs to check for issues related to request routing, authentication, and authorization.
6. Inspect Integrated Service Logs
Examine logs from any integrated services, such as databases or message queues, to identify potential external dependencies.
7. Identify Root Cause
Based on the analysis of logs and metrics, identify the root cause of the issue. This could be a code bug, resource constraint, or external dependency issue.
Code Bug? If the root cause is a code bug, proceed to the next step; otherwise, proceed to the next section.
9. Deploy Code Fix
Deploy a code fix to address the bug.
Resource Constraint? If the root cause is a resource constraint, proceed to the next step; otherwise, proceed to the next section.
1
1. Increase Resource Limits/Optimize Code
Either increase the resource limits for the function or optimize the code to reduce resource consumption.
External Dependency Issue? If the root cause is an external dependency issue, proceed to the next step; otherwise, proceed to the next section.
1
3. Check Dependency Health
Check the health of the external dependency. This may involve examining the dependency’s status page or monitoring its metrics.
1
4. Remediate Dependency Issue
Take steps to remediate the dependency issue, such as restarting the dependency or contacting the vendor.
Latency High? If the latency is high, proceed to the next step.
1
6. Review Function Metrics and Traces
Examine function metrics and traces to identify performance bottlenecks.
1
7. Identify Bottleneck
Based on the analysis of metrics and traces, identify the performance bottleneck. This could be a slow database query or inefficient code.
1
8. Optimize Code/Database Query
Optimize the code or database query to address the bottleneck.
Issue Resolved? After taking corrective actions, verify that the issue is resolved by checking the monitoring dashboard and logs. If the issue is resolved, the process ends; otherwise, repeat the troubleshooting steps.
Scalability and Performance Tuning
Serverless architectures fundamentally alter how scalability and performance are approached in application development and operations. The inherent elasticity of serverless platforms, where resources are dynamically provisioned and scaled based on demand, simplifies many traditional scaling challenges. However, it introduces new considerations for performance tuning, particularly focusing on function optimization and resource management to ensure efficient operation and cost-effectiveness.
Impact of Serverless Architectures on Scalability
Serverless architectures inherently impact scalability through their event-driven, on-demand nature. This contrasts sharply with traditional infrastructure, where scaling often involves pre-provisioning resources and manual adjustments. The key features contributing to scalability in serverless include automatic scaling, horizontal scaling, and fine-grained resource allocation.
- Automatic Scaling: Serverless platforms automatically scale functions based on the number of incoming requests. This scaling is typically triggered by metrics like the number of concurrent executions or the duration of function invocations. This eliminates the need for manual capacity planning and scaling actions.
- Horizontal Scaling: Serverless functions scale horizontally, meaning that the platform spins up additional instances of a function to handle increased load. This approach allows for virtually unlimited scalability, limited primarily by the platform’s infrastructure capabilities and account quotas.
- Fine-grained Resource Allocation: Serverless platforms allow developers to configure resource allocation for functions, such as memory and execution time. This granular control enables developers to optimize function performance and resource utilization based on specific workload requirements.
Strategies for Optimizing Serverless Function Performance
Optimizing the performance of serverless functions requires a multifaceted approach, focusing on code optimization, memory allocation, and efficient use of platform features. Key strategies include code optimization, efficient use of dependencies, and minimizing cold start times.
- Code Optimization: Writing efficient code is crucial for minimizing function execution time and resource consumption. This includes optimizing algorithms, using efficient data structures, and minimizing the amount of data processed by each function invocation. Profiling tools can be used to identify performance bottlenecks in the code.
- Memory Allocation: Properly allocating memory to serverless functions is critical for performance. Allocating too little memory can lead to performance degradation due to resource constraints, while allocating too much memory can increase costs without a corresponding performance benefit. The optimal memory allocation depends on the function’s workload and the amount of data it processes.
- Efficient Use of Dependencies: Minimizing the size and number of dependencies can reduce function deployment size and cold start times. This includes using only the necessary dependencies, optimizing dependency loading, and considering the use of serverless-native dependencies where available.
- Minimizing Cold Start Times: Cold starts, the delay experienced when a function is invoked for the first time or after a period of inactivity, can significantly impact performance. Strategies to mitigate cold starts include keeping functions warm by pre-provisioning instances, optimizing code for fast startup, and choosing the appropriate runtime environment.
Diagram Illustrating Autoscaling Behavior
The autoscaling behavior of serverless functions can be visualized through a diagram that illustrates how function instances are added or removed based on traffic load.
Diagram Description:The diagram illustrates the autoscaling behavior of a serverless function. The X-axis represents time, and the Y-axis represents the number of function instances. The diagram begins with a baseline of one function instance. As the traffic load (represented by the number of incoming requests) increases, the platform automatically scales the number of function instances.
Annotations:
- Initial State: One function instance is running.
- Traffic Spike: An increase in the number of incoming requests triggers the autoscaling mechanism.
- Scaling Up: The platform detects the increased load and automatically provisions additional function instances. The number of instances increases linearly with the load.
- Peak Load: The system reaches a peak load where multiple function instances are running concurrently.
- Load Reduction: As the traffic load decreases, the platform automatically reduces the number of function instances to conserve resources and reduce costs.
- Scaling Down: The platform gradually terminates idle function instances.
- Baseline: The system returns to the initial state, with one function instance running (or potentially more, depending on platform configuration and function activity).
The diagram clearly shows how the number of function instances dynamically adjusts to the traffic load, demonstrating the elasticity of serverless architectures.
Skills and Training for Operations Teams
The transition to serverless computing fundamentally alters the skillset required of operations teams. Traditional operations roles, focused on managing physical infrastructure and operating systems, evolve to encompass a deeper understanding of cloud services, application architecture, and automation. This shift demands continuous learning and adaptation to maintain operational efficiency and security in a dynamic environment.
New Skill Requirements
Operations professionals must acquire a new set of skills to effectively manage serverless applications. These skills are critical for optimizing performance, ensuring security, and minimizing operational overhead.
- Cloud Provider Expertise: A comprehensive understanding of the specific cloud provider’s services (e.g., AWS, Azure, Google Cloud Platform) is paramount. This includes familiarity with serverless offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, as well as related services such as API Gateway, event triggers, and databases. Knowledge of provider-specific tools and APIs for monitoring, logging, and deployment is also essential.
- Infrastructure as Code (IaC): Proficiency in IaC tools, such as Terraform, AWS CloudFormation, or Azure Resource Manager, is crucial. Serverless applications are defined and managed through code, enabling automation, version control, and repeatability. The ability to write, understand, and maintain IaC templates is vital for deploying and managing serverless infrastructure efficiently.
- CI/CD Pipelines: Operations teams need to understand and implement CI/CD pipelines for serverless applications. This involves automating the build, testing, and deployment processes. Tools like AWS CodePipeline, Azure DevOps, and Jenkins are commonly used. Experience with containerization technologies (e.g., Docker) and container orchestration (e.g., Kubernetes) may also be beneficial for managing related services.
- Monitoring and Observability: A deep understanding of monitoring and observability tools is essential for tracking the health and performance of serverless applications. This includes configuring metrics, logs, and traces to identify and resolve issues quickly. Familiarity with tools like AWS CloudWatch, Azure Monitor, Google Cloud Operations Suite (formerly Stackdriver), and third-party solutions like Datadog or New Relic is critical.
- Security Best Practices: Serverless applications introduce new security considerations. Operations teams must understand security best practices for serverless environments, including identity and access management (IAM), data encryption, and vulnerability management. Knowledge of security tools and techniques specific to serverless platforms is also required.
- Programming and Scripting: While not always required for all roles, a basic understanding of programming languages (e.g., Python, JavaScript, Go) and scripting (e.g., Bash) can be highly beneficial. This enables operations engineers to automate tasks, troubleshoot issues, and customize monitoring and management tools.
- Cost Management: Serverless architectures often introduce a “pay-per-use” pricing model. Operations teams must understand cost optimization strategies, including right-sizing resources, utilizing reserved instances, and monitoring spending. Tools and techniques for cost analysis and budgeting are crucial.
- Networking Concepts: A solid grasp of networking concepts, including VPCs, subnets, security groups, and routing, is necessary for managing serverless applications that interact with other services or require network isolation.
Recommended Learning Resources
Continuous learning is crucial for staying current with serverless technologies. The following resources provide valuable information and training for operations professionals:
- Cloud Provider Documentation: Official documentation from cloud providers (AWS, Azure, GCP) is the primary source of information. These resources provide detailed explanations of services, APIs, and best practices.
- Online Courses and Tutorials: Platforms like A Cloud Guru, Udemy, Coursera, and edX offer a wide range of courses and tutorials on serverless computing, cloud technologies, and related topics. These courses often include hands-on labs and practical exercises.
- Cloud Provider Training Programs: Cloud providers offer their own training programs and certifications, such as AWS Certified Solutions Architect, Azure Solutions Architect Expert, and Google Cloud Professional Cloud Architect. These certifications validate knowledge and skills.
- Serverless Framework Documentation: The Serverless Framework is a popular open-source framework for building and deploying serverless applications. Its documentation provides valuable insights into serverless architecture and best practices.
- Blogs and Articles: Numerous blogs and articles from industry experts provide up-to-date information on serverless technologies, best practices, and real-world use cases.
- Community Forums and Online Groups: Participating in online forums and groups, such as Stack Overflow, Reddit, and cloud provider-specific communities, allows operations professionals to connect with peers, ask questions, and share knowledge.
- Books: Several books offer comprehensive guides to serverless computing and related topics.
Career Path for Serverless Operations Engineers
A well-defined career path allows operations engineers to specialize in serverless technologies and advance their careers. The following Artikel provides a typical progression:
- Entry-Level Operations Engineer: Focuses on foundational cloud and serverless concepts, learns basic IaC and CI/CD practices, and gains experience with monitoring and logging tools.
- Mid-Level Serverless Operations Engineer: Deepens expertise in serverless technologies, manages complex deployments, automates operational tasks, and contributes to architectural design. This level often involves certifications like AWS Certified Solutions Architect – Associate or Azure Solutions Architect Expert.
- Senior Serverless Operations Engineer: Leads serverless initiatives, designs and implements complex serverless architectures, develops and implements security best practices, and mentors junior engineers. Experience in a leadership role and advanced certifications, such as AWS Certified Solutions Architect – Professional, are often required.
- Serverless Architect/Lead Engineer: Responsible for defining and implementing the overall serverless strategy, making high-level architectural decisions, and leading a team of engineers. This role requires extensive experience and a deep understanding of serverless technologies.
The following certifications can boost a career path:
- AWS Certified Solutions Architect – Associate/Professional: Validates skills in designing and deploying scalable, highly available, and fault-tolerant systems on AWS.
- Azure Solutions Architect Expert: Demonstrates expertise in designing and implementing solutions on Azure.
- Google Cloud Professional Cloud Architect: Certifies the ability to design and manage cloud solutions on Google Cloud Platform.
- Vendor-Specific Certifications: Certifications from vendors like HashiCorp (Terraform) or Datadog can enhance skills in specific tools.
Experience plays a crucial role in career advancement. Hands-on experience with serverless technologies, building and deploying applications, and troubleshooting issues is essential. Contributions to open-source projects, presenting at conferences, and writing technical articles can also enhance career prospects.
Vendor Lock-in and Portability Concerns
Serverless computing, while offering numerous benefits, introduces the potential for vendor lock-in, which can significantly impact operational flexibility and long-term cost management. Understanding the nuances of vendor lock-in and employing strategies to mitigate its effects is crucial for organizations adopting serverless architectures. This section explores the mechanisms of vendor lock-in, methods for achieving portability, and a comparative analysis of various serverless platforms.
Potential for Vendor Lock-in in Serverless Platforms
The core principle of serverless computing – abstracting away infrastructure management – creates a dependency on the underlying platform provider. This dependency can manifest as vendor lock-in, making it challenging to switch providers or migrate applications.
- Proprietary Services and APIs: Serverless platforms often offer unique, proprietary services and APIs that are not standardized across providers. Integrating these services, such as specific database offerings, event bus systems, or machine learning services, can create tight coupling between the application and the platform. For example, an application heavily reliant on AWS Lambda functions and AWS DynamoDB would require substantial refactoring to migrate to Google Cloud Functions and Google Cloud Datastore.
- Configuration and Deployment Differences: The configuration and deployment processes, including the tools and methods for defining and managing serverless resources (e.g., functions, APIs, storage), vary considerably between providers. These differences necessitate adapting deployment pipelines, configuration files, and infrastructure-as-code scripts when migrating.
- Pricing Models and Cost Optimization: Each provider employs distinct pricing models and cost optimization strategies. Switching platforms can involve re-evaluating and potentially redesigning the application to minimize costs, as pricing structures for compute time, storage, and network traffic vary significantly.
- Ecosystem and Tooling: Serverless platforms often have unique ecosystems and tooling, including monitoring, logging, and debugging tools. Migrating to a new platform requires learning new tools and adapting to different workflows, potentially increasing operational overhead.
- Event-Driven Architectures: Serverless applications frequently leverage event-driven architectures, which are often tightly coupled with the platform’s event bus or message queue services (e.g., AWS EventBridge, Google Cloud Pub/Sub). Migrating such applications can be complex due to differences in event formats, routing, and integration capabilities.
Strategies for Mitigating Vendor Lock-in and Improving Application Portability
While complete avoidance of vendor lock-in is difficult, several strategies can reduce its impact and enhance application portability.
- Abstraction Layers: Implementing abstraction layers between the application code and the platform-specific services can isolate the application from platform dependencies. This involves creating custom interfaces or libraries that encapsulate platform-specific functionalities. For instance, instead of directly using AWS DynamoDB APIs, an application could interact with a custom data access layer that abstracts the underlying database implementation. This allows for switching the database without changing the core application logic.
- Open Standards and Protocols: Prioritizing the use of open standards and protocols (e.g., HTTP, REST APIs, JSON) minimizes vendor-specific dependencies. Building APIs that conform to standard interfaces promotes portability, as the underlying implementation can be swapped without affecting the API contract.
- Infrastructure-as-Code (IaC): Utilizing IaC tools like Terraform or Pulumi enables the definition and management of infrastructure resources in a declarative manner. This approach allows for creating platform-agnostic infrastructure definitions, making it easier to deploy and manage serverless applications across different providers. When migrating, the IaC definitions can be adapted to the target platform.
- Containerization: Containerizing serverless functions using technologies like Docker can enhance portability. Containerized functions can be deployed across different platforms that support container execution, such as AWS Lambda with container image support, Google Cloud Functions, and Azure Functions.
- Serverless Frameworks and Abstractions: Employing serverless frameworks that provide higher-level abstractions can simplify the development and deployment process. Frameworks like the Serverless Framework abstract away many platform-specific details, enabling deployment across multiple providers with minimal code changes.
- Monitoring and Logging Agnostic Approaches: Implementing monitoring and logging solutions that are not tied to a specific vendor can improve portability. Using open-source or platform-agnostic monitoring tools allows for switching platforms without losing the monitoring and observability capabilities.
- Modular Design: Designing applications with modularity in mind facilitates the migration of specific components or services. By breaking down the application into smaller, independent modules, it is easier to migrate individual modules to a new platform without affecting the entire application.
Comparison of Serverless Platforms
The following table compares key features, pricing models, and potential lock-in risks across several popular serverless platforms. The information presented is for illustrative purposes and is subject to change. Always refer to the official documentation for the most up-to-date details.
| Feature | AWS Lambda | Google Cloud Functions | Azure Functions | Cloudflare Workers |
|---|---|---|---|---|
| Compute | Functions as a Service (FaaS) | Functions as a Service (FaaS) | Functions as a Service (FaaS) | Edge computing platform, Functions as a Service (FaaS) |
| Programming Languages | Node.js, Python, Java, Go, .NET, Ruby, etc. (container image support) | Node.js, Python, Go, Java, .NET, etc. | Node.js, Python, Java, .NET, PowerShell, etc. | JavaScript, WebAssembly (Wasm) |
| Event Sources | API Gateway, S3, DynamoDB, Kinesis, EventBridge, etc. | Cloud Storage, Cloud Pub/Sub, Cloud Firestore, HTTP, etc. | HTTP, Azure Blob Storage, Azure Cosmos DB, Event Hubs, etc. | HTTP requests, scheduled triggers, KV storage changes |
| Pricing | Pay-per-use (compute time, requests, memory) | Pay-per-use (compute time, requests, memory) | Pay-per-use (compute time, requests, memory) | Pay-per-use (compute time, requests) |
| Lock-in Risks | High (extensive ecosystem, proprietary services like DynamoDB, API Gateway) | Medium (tight integration with Google Cloud services, event sources) | Medium (integration with Azure services, event sources) | Lower (focused on edge computing, uses standard web technologies) |
| Portability Considerations | Requires significant refactoring to migrate to other providers. Use of abstraction layers and containerization is recommended. | Migration involves adapting event sources and deployment configurations. Use of open standards and IaC tools is beneficial. | Adapting to different event sources and deployment configurations. Containerization and IaC are useful for improving portability. | Relatively portable due to reliance on standard web technologies. Code often requires minimal changes for migration. |
| Example Lock-in Scenario | Heavy reliance on AWS DynamoDB for data storage, AWS API Gateway for API management, and AWS EventBridge for event routing. | Application tightly coupled with Google Cloud Storage for data storage, Cloud Pub/Sub for messaging, and Cloud Functions for event processing. | Application heavily uses Azure Blob Storage, Azure Cosmos DB, and Azure Event Hubs. | Using Cloudflare’s Workers KV for data storage and relying on Cloudflare’s edge network for serving requests. |
Final Thoughts

In conclusion, the shift to serverless represents a profound transformation for operations teams. While the cloud provider handles many traditional infrastructure tasks, operations teams retain critical responsibilities, including automation, monitoring, security, and cost management. By embracing new tools, adopting best practices, and acquiring the necessary skills, operations professionals can successfully navigate this transition, optimize serverless deployments, and drive innovation within their organizations.
The future of operations is undeniably intertwined with the continued evolution of serverless technologies.
FAQ Guide
What are the primary benefits of serverless for operations teams?
Serverless offers benefits such as reduced operational overhead (e.g., no server management), automated scaling, pay-per-use pricing, and increased developer productivity due to simplified deployment and management processes.
How does serverless impact the need for infrastructure provisioning?
Serverless largely eliminates the need for manual infrastructure provisioning. The cloud provider dynamically allocates resources based on demand, reducing the time and effort required for infrastructure management.
What are the key considerations for security in a serverless environment?
Security considerations include securing function code, managing access control (IAM), monitoring for vulnerabilities, and implementing robust logging and auditing practices. Security is often shifted towards identity and access management and function code security.
How does serverless affect incident response procedures?
Incident response in serverless requires a focus on identifying and resolving issues related to function execution, event triggers, and API integrations. Logging, monitoring, and tracing are crucial for root cause analysis and rapid remediation.
What skills are most important for operations engineers working with serverless?
Essential skills include proficiency in cloud provider services (e.g., AWS Lambda, Azure Functions, Google Cloud Functions), Infrastructure as Code (IaC), monitoring and observability tools, CI/CD pipelines, and a strong understanding of security best practices.